
常见异架构基础
ARM
CTF比赛中,大部分题的都是x86、x86_64的程序,这类程序是属于Intel处理器支持的
但其实,在生活中配置ARM处理器的设备要多得多,比如:Android、网络设备、智能家居等
Intel和ARM之间的区别主要是指令集
●CISC 复杂指令集
●RISC 精简指令集
精简指令集通过减少每条指令的时钟周期来缩短执行时间,可以更快的执行指令,但因为指令较少,因此在实现功能时,会显得比Intel冗长
其次,在x86上,大多数指令都可以直接对内存中的数据进行操作,而在ARM上,必须先将内存中的数据从内存移到寄存器中,然后再进行操作
一般我们说的arm是ARMv7架构,是32位,而aarch64是ARMv8架构,也就是64位。
寄存器
ARM32
寄存器的数量取决于ARM版本,ARM32有30个通用寄存器(基于ARMv6-M和基于ARMv7-M的处理器除外),前16个寄存器可在用户级模式下访问,其他寄存器可在特权软件执行中使用
其中,r0-15寄存器可在任何特权模式下访问。这16个寄存器可以分为两组:通用寄存器(R0-R11)和专用寄存器(R12-R15)
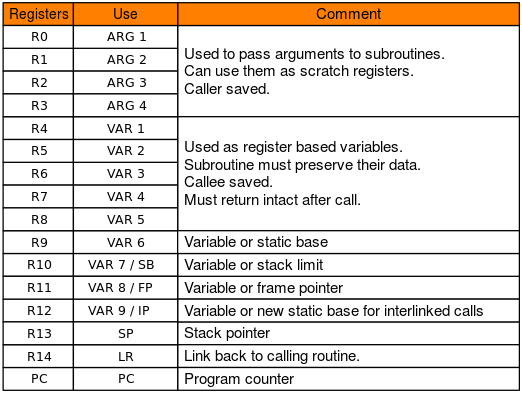
普通寄存器R0-R12:可在常规操作期间用于存储临时值,指针(到存储器的位置)等,例如:
●R0在算术操作期间可称为累加器,或用于存储先前调用的函数的结果
●R7在处理系统调用时非常有用,因为它存储系统调用号
●R11帮助我们跟踪用作帧指针的堆栈的边界
●ARM上的函数调用约定指定函数的前四个参数存储在寄存器r0-r3中
特殊寄存器
R13:SP(堆栈指针)。堆栈指针指向堆栈的顶部。堆栈是用于函数特定存储的内存区域,函数返回时将对其进行回收。因此,通过从堆栈指针中减去我们要分配的值(以字节为单位),堆栈指针可用于在堆栈上分配空间。换句话说,如果我们要分配一个32位值,则从堆栈指针中减去4
R14:LR(链接寄存器)。进行功能调用时,链接寄存器将使用一个内存地址进行更新,该内存地址引用了从其开始该功能的下一条指令。这样做可以使程序返回到“父”函数,该子函数在“子”函数完成后启动“子”函数调用
R15:PC(程序计数器)。程序计数器自动增加执行指令的大小。在ARM状态下,此大小始终为4个字节,在THUMB模式下,此大小始终为2个字节。当执行转移指令时,PC保留目标地址。在执行期间,PC在ARM状态下存储当前指令的地址加8(两个ARM指令),在Thumb(v1)状态下存储当前指令的地址加4(两个Thumb指令)。这与x86不同,x86中PC始终指向要执行的下一条指令
与x86平行对比

函数调用
1.当参数少于4个时,子程序间通过寄存器R0~R3来传递参数;当参数个数多于4个时,将多余的参数通过数据栈进行传递,入栈顺序与参数顺序正好相反,即从左到右,子程序返回前无需恢复R0~R3的值
2.在子程序中,使用R4~R11保存局部变量,若使用需要入栈保存,子程序返回前需要恢复这些寄存器;R12是临时寄存器,使用不需要保存
3.R13用作数据帧指针,记作SP;R14用作链接寄存器,记作LR,用于保存子程序返回时的地址;R15是程序计数器,记作PC
4.ATPCS规定堆栈是满递减堆栈FD;
5.子程序返回32位的整数,使用R0返回;返回64位整数时,使用R0返回低位,R1返回高位
AARCH64
AARCH64也即64位的ARM,从ARMv8开始才有。ARMv8分为aarch32和aarch64两部分。
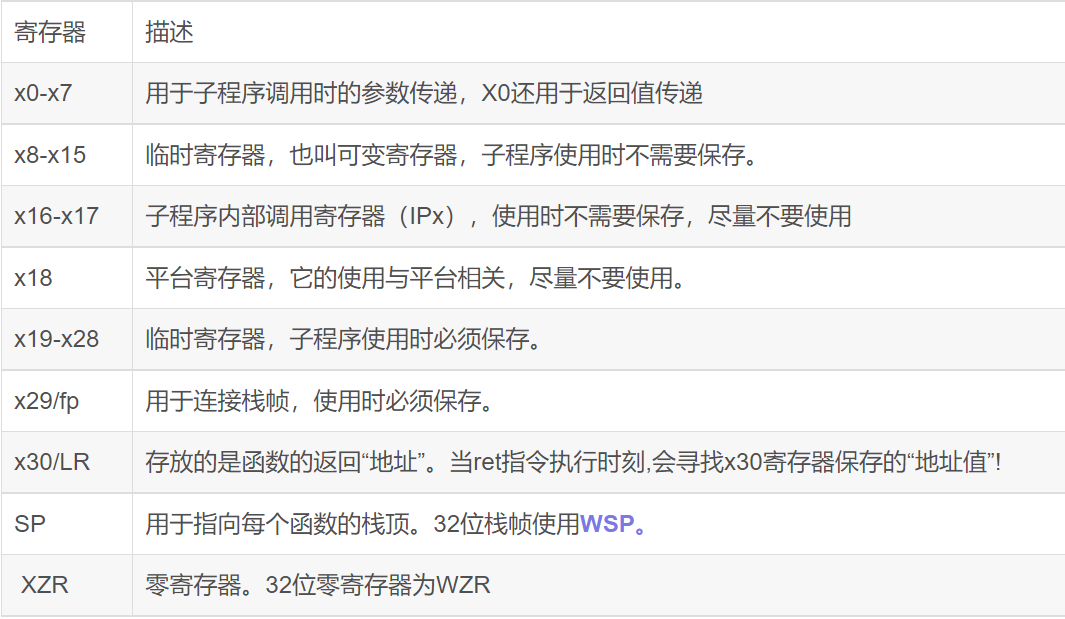
aarch64有31个通用寄存器:X0-X30
低 32 位可以通过 W0-W30 来访问. 当写入 Wy 时, Xy 的高 32 位会被置 0。

AARCH64标准提供了8个通用寄存器(X0~X7)用于传递函数参数,依次对应于前8个函数参数。超过8个的参数使用堆栈进行参数传递。
函数的返回值用通用寄存器X0来保存。
32与64位差异
arm32下,前4个参数是通过r0~r3传递,第4个参数需要通过sp访问,第5个参数需要通过sp + 4 访问,第n个参数需要通过sp + 4*(n-4)访问。
arm64下,前8个参数是通过x0~x7传递,第8个参数需要通过sp访问,第9个参数需要通过sp + 8 访问,第n个参数需要通过sp + 8*(n-8)访问。
ARM指令在32位下和在64位下并不是完全一致的,但大部分指令是通用的,特别的,” mov r2, r1, lsl #2”仅在ARM32下支持,它等同于ARM64的” lsl r2, r1, #2”
还有一些32位存在的指令在64位下是不存在的,比如vswp指令,条件执行指令subgt,addle等
arm指令集
ARM指令集
ARM处理器具有两种可以运行的主要状态(此处不包括Jazelle):ARM和Thumb
这两种状态之间的主要区别是指令集,其中ARM状态下的指令始终为32位,Thumb状态下的指令始终为16位(但可以为32位)
现在,ARM引入了增强的Thumb指令集(Thumbv2),该指令集允许32位Thumb指令甚至条件执行,而在此之前的版本中是不可能的,为了在Thumb状态下使用条件执行,引入了“ it”指令。但是,这个指令在后来的版本中被删除并替换成了其他的
在编写ARM shellcode时,我们需要摆脱NULL字节,并使用16位Thumb指令而不是32位ARM指令来减少使用它们的机会。
Thumb和ARM一样也有不同的版本:
●Thumb-1(16位指令):在ARMv6和更早的体系结构中使用
●Thumb-2(16位和32位指令):通过添加更多指令并使它们的宽度为16位或32位(ARMv6T2,ARMv7)来扩展Thumb-1
●ThumbEE:包括一些针对动态生成的代码的更改和添加
ARM和Thumb之间的区别:
●条件执行:ARM状态下的所有指令均支持条件执行。某些ARM处理器版本允许使用“it”指令在Thumb中有条件执行。
●32位ARM和Thumb指令:32位Thumb指令带有.w后缀。
●桶式移位器(barrel shifter)是ARM模式的另一个独特功能。它可以用于将多个指令缩小为一个。例如,您可以使用左移,而不是使用两条指令,将寄存器乘以2并使用mov将结果存储到另一个寄存器中:mov r1, r0, lsl #1 ; r1 = r0 * 2
切换处理器执行的状态
必须满足以下两个条件之一:
●我们可以使用分支指令BX(分支和交换)或BLX(分支,链接和交换)并将目标寄存器的最低有效位设置为1。这可以通过在偏移量上加上1来实现,例如0x5530 + 1。可能会认为这会导致对齐问题,因为指令是2字节或4字节对齐的。这不是问题,因为处理器将忽略最低有效位
●我们知道如果当前程序状态寄存器中的T位置1,则我们处于Thumb模式。
ARM指令初识
汇编语言由指令构成,而指令是主要的构建块。ARM指令通常后跟一个或两个操作数,并且通常使用以下模板:
MNEMONIC {S} {condition} {Rd},Operand1,Operand2

注意,由于ARM指令集的灵活性,并非所有指令都使用模板中提供的所有字段。其中,条件字段与CPSR寄存器的值紧密相关,或者确切地说,与寄存器内特定位的值紧密相关
Operand2被称为灵活操作数,因为我们可以以多种形式使用它,例如,我们可以将这些表达式用作Operand2:

下面以一些常见指令为例:

ARM常用指令
| 指令 | 描述 | 指令 | 描述 |
|---|---|---|---|
| MOV | 移动数据 | EOR | 按位异或 |
| MVN | 移动并取反 | LDR | 加载 |
| ADD | 加 | STR | 存储 |
| SUB | 减 | LDM | 加载多个 |
| MUL | 乘 | STM | 存储多个 |
| LSL | 逻辑左移 | PUSH | 入栈 |
| LSR | 逻辑右移 | POP | 出栈 |
| ASR | 算术右移 | B | 跳转 |
| ROR | 右旋 | BL | Link跳转 |
| CMP | 比较 | BX | 分支跳转 |
| AND | 按位与 | BLX | 使用Link分支跳转 |
| ORR | 按位或 | SWI/SVC | 系统调用 |
LDR 和 STR
ARM使用加载存储模型进行内存访问,这意味着只有加载/存储(LDR和STR)指令才能访问内存
通常,LDR用于将某些内容从内存加载到寄存器中,而STR用于将某些内容从寄存器存储到内存地址中

LDR操作:将R0中的地址的值加载到R2寄存器中
STR操作:将R2中的值存储到R1中的内存地址处

LDM 和 STM
在执行压栈和出栈的指令时,通常使用LDMIA/STMDB
但事实上在汇编的过程中,可以看到LDMIA和STMDB指令已转换为PUSH和POP,那是因为 PUSH和STMDB sp!, reglist,POP和LDMIA sp! Reglist是等价的

分支
分支指令分为三种:
分支(B)
简单跳转到功能
分支链接(BL)
将(PC + 4)保存为LR并跳转至功能
分支交换(BX)和分支链接交换(BLX)
与B / BL +exchange指令集相同(ARM <-> Thumb)
需要一个寄存器作为第一个操作数:BX / BLX reg
BX / BLX用于将指令集从ARM交换到Thumb
不过AARCH64中貌似去除了thumb转换指令
指令后缀
| 后缀 | 描述 |
|---|---|
| S | 更新 APSR(应用程序状态寄存器,如进位、溢出、零和负标志),例如:ADDS R0,R1;该ADD操作会更新APSR |
| EQ, NE, CS, CC, MI,PL,VS,VC,HI,LS,GE, LT, GT, LE | 条件执行后缀,若满足相应条件则执行后面的语句,例如:BEQ label;若之前的操作得到相等的状态(状态寄存器Z置位),则跳转至 label |
| .N,.W | 指定使用的是 16 位指令 (narrow) 或 32 位指令(wide) |
| .32,.F32 | 指定 32 位单精度运算, 对于多数工具链, 32 后缀是可选的 |
| .64,.F64 | 指定 64 位单精度运算, 对于多数工具链, 64 后缀是可选的 |
可以通过 S 后缀的指令影响状态寄存器的标志位,再通过各类条件码后缀执行相应判断
| 条件码助记符 | 条件码 | 标志 | 含义 |
|---|---|---|---|
| EQ | 0000 | Z=1 | 相等 |
| NE | 0001 | Z=0 | 不相等 |
| CS/HS | 0010 | C=1 | 无符号数大于或等于 |
| CC/LO | 0011 | C=0 | 无符号数小于 |
| MI | 0100 | N=1 | 负数 |
| PL | 0101 | N=0 | 正数 |
| VS | 0110 | V=1 | 溢出 |
| VC | 0111 | V=0 | 没有溢出 |
| HI | 1000 | C=1,Z=0 | 无符号数大于 |
| LS | 1001 | C=0 或 Z=1 | 无符号数小于或等于 |
| GE | 1010 | N=V | 带符号数大于或等于 |
| LT | 1011 | N!=V | 带符号数小于 |
| GT | 1100 | Z=0,N=V | 带符号数大于 |
| LE | 1101 | Z=1 或 N!=V | 带符号数小于或等于 |
| AL | — | 无条件执行 | |
| NV | — | 不执行 |
条件码应用举例:
比较两个值大小,并进行相应加1处理,C语言代码为:
1 | if ( a > b ) |
对应的ARM指令如下(其中R0中保存a 的值,R1中保存b的值):
1 | CMP R0, R1 ; R0与R1比较,做R0-R1的操作 |
ARM32与AARCH64部分指令差异

arm
arm架构下的寄存器和x86_64架构还是有很大区别的,其中R0 ~ R3是用来依次传递参数的,相当于x64下的rdi, rsi, rdx,R0还被用于存储函数的返回值,R7常用来存放系统调用号,R11是栈帧,相当于ebp,在arm中也被叫作FP,相应地,R13是栈顶,相当于esp,在arm中也被叫作SP,R14(LP)是用来存放函数的返回地址的,R15相当于eip,在arm中被叫作PC,但是在程序运行的过程中,PC存储着当前指令往后两条指令的位置,在arm架构中并不是像x86_64那样用ret返回,而是直接pop {PC}。
在arm中的ldr和str指令是必须清楚的,其中ld就是load(加载),st就是store(存储),而r自然就是register(寄存器),搞明白这些以后,这两个指令就很容易理解了(cond为条件):
LDR {cond} Rd, <addr>:加载指定地址(addr)上的数据(字),放入到Rd寄存器中。
STR {cond} Rd, <addr>:将Rd寄存器中的数据(字)存储到指定地址(addr)中。
当然,这两个指令有很多种写法,灵活多变:
str r2, [r1, #2]:寄存器r2中的值被存放到寄存器r1中的地址加2处的地址中,r1寄存器中的值不变;
str r2, [r1, #2]!:与上一条一样,不过最后r1 += 4,这里的{!}是可选后缀,若选用该后缀,则表示请求回写,也就是当数据传送完毕之后,将最后的地址写入到基址寄存器(Rn)中;
ldr r2, [r1], #-2:将r1寄存器里地址中的值给r2寄存器,最后r1 -= 2;
上面的立即数或者寄存器也类似,此外还可以有这些写法:
str r2, [r1, r3, LSL#2]:将寄存器r2中的值存储到寄存器r1中的地址加上r3寄存器中的值左移两位后的值所指向的地址中;
ldr r2, [r1], r3, LSL#2:将r1寄存器里地址中的值给r2寄存器,最后r1 += r3 << 2.
在arm中仍有mov指令,通常用于寄存器与寄存器间的数据传输,也可以传递立即数。
1 | mov r1, #0x10`:`r1 = 0x10 |
1 | mov r1, r2`:`r1 = r2 |
1 | mov r1, r2, LSL#2`:`r1 = r2 << 2 |
由此可见,ldr和str指令通常用于寄存器与内存间的数据传递,其中会通过另一个寄存器作为中介,而mov指令则是通常用于两个寄存器之间数值的传递。
此外,还有数据块传输指令LDM, STM,
其中提到了STMFD和LDMFD指令,可用作压栈和弹栈,如STMFD SP! ,{R0-R7,LR}和LDMFD SP! ,{R0-R7,LR},但是在我们拿到的CTF题目中,常见的仍是push {}和pop {}指令。
还需要知道的是add和sub命令:
add r1, r2, #2 相当于 r1 = r2 + 2;
sub r1, r2, r3 相当于 r1 = r2 - r3.
还有跳转指令B相关的一些指令,相当于jmp:
B Label:无条件跳转到Label处;
BL Label:当程序跳转到标号Label处执行时,同时将当前的PC值保存到R14中;
BX Label:这里需要先提一下arm指令压缩形式的子集Thumb指令了,不像是arm指令是一条四个字节,Thumb指令一条两个字节,arm对应的cpu工作状态位为0,而Thumb对应的cpu工作状态位为1,我们从其中一个指令集跳到另外一个指令集的时候,需要同时修改其对应的cpu工作状态位,不然会报invalid instrument错误,当BX后面的地址值最后一个bit为1时,则转为Thumb模式,否则转为arm模式,直接pop {pc}这样跳转也有这种特性;
BLX Label:就是BL + BX指令共同作用的效果。
位运算命令:and orr eor 分别是 按位与、或、异或。
aarch64
aarch64和arm架构相比,还是有一些汇编指令上的区别的:
首先仍是寄存器,在64位下都叫作Xn寄存器了,其对应的低32位叫作Wn寄存器,其中栈顶是X31(SP)寄存器,栈帧是X29(FP)寄存器,X0 ~ X7用来依次传递参数,X0存放着函数返回值,X8常用来存放系统调用号或一些函数的返回结果,X32是PC寄存器,X30存放着函数的返回地址(aarch64中的RET指令返回X30寄存器中存放的地址)。
然后是跳转指令,仍有B,BL指令,新增了BR指令(向寄存器中的地址跳转),BLR组合指令。
还有一些带判断的跳转指令:b.ne是不等则跳转,b.eq是等于则跳转,b.le是大于则跳转,b.ge是小于则跳转,b.lt是大于等于则跳转,b.gt是小于等于则跳转,cbz为结果等于零则跳转,cbnz为结果非零则跳转…
在aarch64架构下的一大变化就是,不再使用push和pop指令压栈和弹栈了,也没有LDM和STM指令,而是使用STP和LDP指令:
STP x4, x5, [sp, #0x20]:将sp+0x20处依次覆盖为x4,x5,即x4入栈到sp+0x20,x5入栈到sp+0x28,最后sp的位置不变。
LDP x29, x30, [sp], #0x40:将sp弹栈到x29,sp+0x8弹栈到x30,最后sp += 0x40。
其中,STP和LDP中的P是pair(一对)的意思,也就是说,仅可以同时读/写两个寄存器。
ARM堆栈和函数调用
是一种先进后出的数据结构,栈底是第一个进栈的数据所处位置,栈顶是最后一个数据进栈所处的位置。在创建进程时会在栈中分配相应内存,我们使用堆栈来保存局部变量、参数传递、保存寄存器的值
ARM中主要使用PUSH和POP指令与堆栈进行交互
注意,这里的PUSH和POP是其他一些与内存相关的指令的别名,而不是真实的指令
四种堆栈:ARM采用的满降栈
●满/空栈
根据SP指针指向的位置,栈可以分为满栈和空栈
满栈:当堆栈指针总是指向最后压入堆栈的数据
空栈:当堆栈指针总是指向下一个将要放入数据的空位置
●升/降栈
根据SP指针移动的方向,栈可以分为升栈和降栈
升栈:随着数据的入栈,SP指针从低地址->高地址移动
降栈:随着数据的入栈,SP指针从高地址->低地址移动

这是不同的栈使用的压栈/出栈(存储多个/加载多个)指令:

ARM栈帧
栈帧(stack frame)就是一个函数所使用的那部分栈,所有函数的栈帧串起来就组成了一个完整的栈。栈帧的两个边界分别由fp(r11)和sp(r13)来限定。

前面描述的是ARM的栈帧布局方式。main stack frame为调用函数的栈帧,func1 stack frame为当前函数(被调用者)的栈帧,栈底在高地址,栈向下增长
FP就是栈基址,它指向函数的栈帧起始地址;SP则是函数的栈指针,它指向栈顶的位置。ARM压栈的顺序依次为当前函数指针PC、返回指针LR、栈指针SP、栈基址FP、传入参数个数及指针、本地变量和临时变量
如果函数准备调用另一个函数,跳转之前临时变量区先要保存另一个函数的参数。从main函数进入到func1函数,main函数的上边界和下边界保存在被它调用的栈帧里面。
ARM也可以用栈基址和栈指针明确标示栈帧的位置,栈指针SP一直移动
汇编
1、比较两个值大小, C 语言代码如下:
1 | if(a > b) a++; else b++; |
对应的 ARM 指令代码如下:(设 R0 为 a,R1 为 b)
1 | CMP R0, R1 ;R0与R1比较 |
2、若两个条件均成立,则将这两个数值相加,C 语言代码如下:
1 | if((a != 10)&&(b != 20)) a = a + b; |
对应的 ARM 指令代码为:
1 | CMP R0,#10 ;比较R0是否为10 |
3、若两个条件有一个成立,则将这两个数值相加,C 语言代码如下:
1 | if((a!=10)||(b!=20)) a=a+b; |
对应的 ARM 指令代码为:
1 | CMP R0,#10 |
处理器内数据传送
以32为例
| 指令名称 | 语法 | 指令作用 | 注意 |
|---|---|---|---|
| MOV | MOV Rx,Ry/#num32 |
将源操作数的值赋给目的操作数 | |
| MRS | MRS Rx,Rs |
同 MOV | 源操作数应为特殊寄存器 |
| MSR | MSR Rs,Rx |
同 MOV | 目的操作数应为特殊寄存器 |
| MOVW | MOVW Rx,#num16 |
将源操作数赋给目的操作数的低 16 位 | 高位清零 |
| MOVT | MOVT Rx,#num16 |
将源操作数赋给目的操作数的高 16 位 | 低位不变 |
不同数据大小的存储器访问
| 数据类型 | 读存储器指令 | 写存储器指令 | 语法 |
|---|---|---|---|
| 32 位 | LDR | STR | LDR Rx,ADDR;将地址ADDR上的值赋给Rx STR Rx,ADDR;将Rx的值赋给地址为ADDR的存储空间 |
| 16 位有符号 | LDRSH | 无 | |
| 16 位无符号 | LDRH | STRH | |
| 8 位有符号 | LDRSB | 无 | |
| 8 位无符号 | LDRB | STRB | |
| 多个 32 位 | LDM | STM | LDM、STM |
| 双字(64 位) | LDRD | STRD | LDRD/STRD R1,R2,ADDR;从地址ADDR上读出两个字并分别赋给两个寄存器 |
| 栈操作(32 位) | POP | PUSH | PUSH、POP |
1 | ldr指令的格式: |
存储器访问方式(地址表达式)
立即数偏移
数据传输使用的存储器地址为:寄存器中的数值 + 立即数常量(偏移地址)
LDRB R0,[R1,#0x3];从地址R1+0x3中读取一个字节并将其存入R0
加入感叹号(!)可更新存放地址的寄存器的值(写回):LDRB R0,[R1,#0x3]!;从地址R1+0x3中读取一个字节并将其存入R0后令R1=R1+0x3
寄存器偏移
类似立即数偏移,但这里的寄存器可以通过移位指令进行移位:
1 | LDR R3,[R0, R2, LSL #2];将存储器[R0+(R2<<2)]读入R3 |
注意:这里进行的是前序偏移,也就是以地址偏移后的值为地址进行取值,下面介绍一下后序寻址:
后序寻址是取地址上的值,后进行地址偏移:
1 | LDR R0, [R1], #offset;读取存储器[R1],然后R1被赋值为R1+偏移 |
后序寻址不能使用 R14(SP)或 R15(PC)。
跳转
| 指令名称 | 语法 | 指令作用 |
|---|---|---|
| B | B label |
跳转到标号对应的地址,属于相对跳转(会计算标号和当前 PC 的差),跳转范围为 ±2KB(可添加. W 后缀使用 32 位版本的指令) |
| BX | BX Rx |
跳转到存放于寄存器 Rx 中的地址值,并基于 Rx 第 0 位设置处理器执行状态(Cortex-M 只支持 Thumb 状态,因此第 0 位必须为 1) |
函数调用
| 指令名称 | 语法 | 指令作用 |
|---|---|---|
| BL | BL label |
跳转到标号位置并将返回地址保存到链接寄存器 R14(LR)中 |
| BLX | BLX Rx |
跳转到存放于寄存器 Rx 中的地址值并将返回地址保存到 LR 中,以及更新 EPSR 中的 T 位为 Rx 的最低位 |
程序计数器 R15(PC)为跳转目标地址(即将标号 / 地址赋给 PC)
返回地址即 BL/BLX 指令后的指令的地址
由于 Cortex-M 只支持 Thumb 状态,因此使用 BLX 指令时,Rx 的第 0 位必须为 1
函数调用和标号跳转的区别在于,函数调用需要将返回地址保存,这也是 BL 和 BLX 与 B 和 BX 的区别
相关概念
AAPCS
在较早之前,ARM过程调用标准叫做 APCS (ARM Procedure Call Standard),
Thumb 的过程调用标准为 TPCS。
如今这两种叫法已经废弃,统一称作 AAPCS (Procedure Call Standard for the ARM Architecture)。
thumb&arm
ARM架构有两种指令编码:ARM and THUMB
ARM指令集使用32位指令(不论32位还是64位),而Thumb指令集使用16位指令,旨在提高代码密度,降低存储和带宽要求。在ARM体系结构中,处理器可以在ARM和Thumb指令之间切换执行。
| Thumb 状态 | ARM 状态 | |
|---|---|---|
| 指令集 | Thumb 指令集 | ARM 指令集 |
| 指令长度 | 16 位(半字指令) | 32 位 |
| 指令执行条件 | 大多数指令无条件执行 | 大多数指令有条件执行 |
| 优点 | 低功耗,存储空间要求低 | 代码需要的指令数少,性能高 |
EABI
EABI是嵌入式应用二进制接口(Embedded Application Binary Interface)。ARM EABI是一种与ARM架构相关的二进制接口标准,旨在确保在嵌入式系统中编写的软件的二进制兼容性。
EABI定义了一组规范,涉及到函数调用规约、数据对齐、异常处理、堆栈管理等方面。这有助于确保在不同的编译器、操作系统和库之间生成的二进制程序可以在ARM架构的嵌入式系统上正确运行
el&hf
armel是arm eabi little endian的缩写
armhf是arm hard float的缩写
arm64,64位的arm默认就是hf的,因此不需要hf的后缀。
armel和armhf的区别
它们的区别体现在浮点运算上,它们在进行浮点运算时都会使用fpu,但是armel传参数用普通寄存器,而armhf传参数用的是fpu的寄存器,因此armhf的浮点运算性能更高。
MIPS
特点
- mips是大端(big-endian)架构,而mipsel是小端(little-endian)架构。指令的用法是差不多的。
- MIPS固定4字节指令长度;
- 内存中的数据访问(load/store)必须严格对其(至少4字节对齐);
- 跳转指令只有26位目标地址,加上2位对齐位,可寻址28位的空间,即256MB;
- 条件分支指令只有16位跳转地址,加上2位对齐位,可寻址18位的空间,即256KB;
- 流水线效应。MIPS采用了高度的流水线,其中最重要的就是分支延迟效应。在分支跳转语句后面那条语句叫分支延迟槽。实际上,在程序执行到分支语句时,当他刚把要跳转的地址填充好(填充到代码计数器里),还没有完成本条指令时,分支语句后面的那个指令就已经执行了,其原因就是流水线效应——几条指令同时执行,只是处于不同的阶段,mips不像其它架构那样存在流水线阻塞。所以分支跳转语句的下一条指令通常都是空指令nop或一些其他有用的语句。
- 缓存刷新机制:MIPS CPUs有两个独立的cache:指令cache和数据cache。 指令和数据分别在两个不同的缓存中。当缓存满了,会触发flush, 将数据写回到主内存。攻击者的攻击payload通常会被应用当做数据来处理,存储在数据缓存中。当payload触发漏洞, 劫持程序执行流程的时候,会去执行内存中的shellcode.如果数据缓存没有触发flush的话,shellcode依然存储在缓存中,而没有写入主内存。这会导致程序执行了本该存储shellcode的地址处随机的代码,导致不可预知的后果。(通常执行sleep(1)刷新)
寄存器
MIPS无论是32位还是64位都有32个通用寄存器,以及2个特殊的寄存器(hi、lo)用于保存乘法和除法指令的结果,还有一个计数寄存器pc。
寄存器分为两类:通用寄存器(GPR)和特殊寄存器。通用寄存器:MIPS体系结构中有32个通用寄存器,汇编程序中用$0~$31表示。也可以用名称表示,如$sp、$t1、$ra等。
| 编号 | 寄存器名称 | 描述 |
|---|---|---|
| $0 | $zero | 第0号寄存器,其值始终为0。 |
| $1 | $at | 保留寄存器 |
| $2-$3 | $v0-$v1 | values,保存表达式或函数返回结果 |
| $4-$7 | $a0-$a3 | argument,作为函数的前四个参数 |
| $8-$15 | $t0-$t7 | temporaries,供汇编程序使用的临时寄存器 |
| $16-$23 | $s0-$s7 | saved values,子函数使用时需先保存原寄存器的值 |
| $24-$25 | $t8-$t9 | temporaries,供汇编程序使用的临时寄存器,补充$t0-$t7。 |
| $26-$27 | $k0-$k1 | 保留,中断处理函数使用 |
| $28 | $gp | global pointer,全局指针 |
| $29 | $sp | stack pointer,堆栈指针,指向堆栈的栈顶 |
| $30 | $fp | frame pointer,保存栈指针 |
| $31 | $ra | return address,返回地址 |
栈帧
MISP的函数调用约定:$a0~$a3 用于函数前四个参数传参,多的参数用堆栈传参。$v0~$v1用于保存函数返回值。$fp寄存器可以理解为x86下的ebp
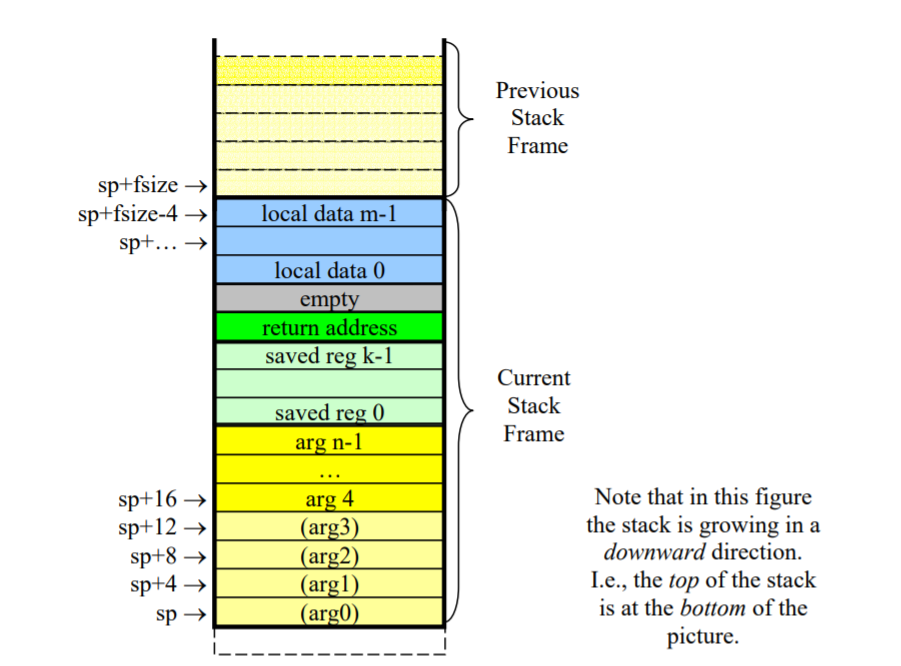
MIPS O32调用约定规定了执行跳转(调用)指令时,将返回值存储在ra寄存器。所占空间不大于4 byte的参数应该放在从 a0到 a3 的寄存器中,剩下的参数应该依次放到调用者 stack frame 的参数域中,并且在参数域中需要为前四个参数保留栈空间,因为被调用者使用到前四个参数时,是统一的将参数寄存器中的值放入保留的栈空间,再从保留的栈空间里面取值;如果被调用者需要使用 $s0~$s7 这些保留寄存器(saved register),就必须先将这些保留寄存器的值保存在被调用者 stack frame 的保留寄存器域中,当被调用者返回时恢复这些寄存器值;当被调用者不是叶子函数时,即被调用者中存在对其它函数的调用,需要将 ra (return address) 寄存器 值保存到被调用者 stack frame 的返回值域中;被调用者所需要使用的局部变量,应保存在被调用者 stack frame 的本地变量域中。
进入一个函数时需要将当前栈指针向下移动 n 比特,这个大小为n比特的存储空间就是此函数的 stack frame 的存储区域。此后栈指针便不再移动,只能在函数返回时再将栈指针加上这个偏移量恢复栈现场。由于不能随便移动栈指针,所以寄存器压栈和出栈都必须指定偏移量。
在 RISC 计算机中主要参与计算的是寄存器,saved registers 就是指在进入一个函数后,如果某个保存原函数信息的寄存器会在当前函数中被使用,就应该将此寄存器保存到堆栈上,当函数返回时恢复此寄存器值。而且由于 RISC 计算机大部分采用定长指令或者定变长指令,一般指令长度不会超过32个位。而现代计算机的内存地址范围已经扩展到 32 位,这样在一条指令里就不足以包含有效的内存地址,所以RISC计算机一般借助于一个返回地址寄存器 RA(return address) 来实现函数的返回。几乎在每个函数调用中都会使用到这个寄存器,所以在很多情况下 RA 寄存器会被保存在堆栈上以避免被后面的函数调用修改,当函数需要返回时,从堆栈上取回 RA 然后跳转。移动 SP 和保存寄存器的动作一般处在函数的开头;恢复这些寄存器状态的动作一般放在函数的最后。
汇编指令
指令格式
MIPS指令长度为32位,其中指令位均为6位,其余的26位可以分为R型、I型、J型共3种类型。
R型 Opcode(6) Rd(5) Rs(5) Rt(5) Shamt(5) Funct(6)
I型 Opcode(6) Rd(5) Rs(5) Immediate(16)
J型 Opcode(6) Address(26)
各字段含义如下:
- Opcode:指令基本操作,成为操作码;
- Rs:第一个源操作数寄存器;
- Rt:第二个源操作数寄存器;
- Rd:存放操作结果的目的操作数;
- Shamt:位移量;
- Funct:函数,这个字段选择Opcode操作的某个特定变体。
- PS:所以有些指令会被优化,比如li $v0,0x7777,实际上CPU会解析成ori $v0,$zero,0x7777或addi $v0,$zero,0x7777执行。
常用指令
内存与寄存器
li(Load Immediate):
用于将一个立即数 存入一个寄存器
li $Rd, imm
lui(Load Upper halfword Immediate):
读取一个16位立即数放入寄存器的高16位,低16位补0。如果加载一个32位立即数(DWORD)则需要lui和addi两条指令配合完成。因为作为32位定长指令没有足够的空间存储32位立即数,只能用16位代替。
lui $a1, 0x42 //将0x42放入$a1的高16位
lw(Load Word):
用于从一个指定的地址加载一个word类型的值到寄存器中
1 | lw $Rt, offset($Rs) |
sw(Load Word):
用于将源寄存器中的值存入指定的地址
1 | sw $Rt, offset($Rs) |
算术指令
1 | add $t0, $t1, $t2 //$t0 = $t1 + $t2,带符号数相加 |
系统调用
系统调用号存放在$v0中,参数存放在$a0~$a3中(如果参数过多,会有另一套机制来处理),系统调用的返回值通常放在$v0中,如果系统调用出错,则会在$a3中返回一个错误号,最终调用Syscall指令。
内存寻址
- 跳转指令(j)
有限的32位指令长度对于大型程序的分支跳转支持确实是个难题。MIPS指令中最小的操作码域占6位,剩下的26位用于跳转目标的编址。由于所有指令在内存中都是4字节对齐的,因此最低的2个比特位是无需存储的,这样实际可供寻址范围为2^28=256MB。分支跳转地址被当做一个256MB的段内绝对地址,而非PC相对寻址。这对于地址范围超过256MB的跳转程序而言是无能为力的,所幸目前也很少遇到这么大的远程跳转需求。
- 段外分支跳转
可以使用寄存器跳转指令实现,它可以跳转到任意(有效的)32位地址。
- 条件分支跳转指令(b)
编码域的后 16 位 broffset 是相对当前指令PC的有符号偏移量,由于指令是4字节对齐的,长度都为4个字节,因此可支持的跳转范围实际上是2^16 * 4(指令宽度)=2^18=256KB(相对PC的-128KB~+128KB)。如果确定跳转目标地址在分支指令前后的128KB范围内,编译器就可以编码只生成一条简单的条件分支指令。
分支跳转指令
在MIPS中,分支跳转指令本身可通过比较两个寄存器中的值来决定是否跳转。要想实现与立即数比较的跳转,可以结合类跳转指令实现
1 | beq $Rs, $Rt, target //if ($Rs == $Rt): goto target |
直接跳转指令
j:该指令无条件跳转到一个绝对地址。实际上,j 指令跳转到的地址并不是直接指定32位的地址(所有 MIPS 指令都是 32 位长,不可能全部用于编址数据域,那样的指令是无效的,也许只有nop):由于目的地址的最高4位无法在指令的编码中给出,32位地址的最高4位取值当前PC的最高4位。对于一般的程序而言,28位地址所支持的256MB跳转空间已经足够大了。
要实现更远程的跳转,必须使用 jr 指令跳转到指定寄存器中,该指令也用于需要计算合成跳转目标地址的情形。你可以使用 j 助记符后面紧跟一个寄存器表示寄存器跳转,不过一般不推荐这么做。
jal、jalr:这两条指令分别实现了直接和间接子程序调用。在跳转到指定地址实现子程序调用的同时,需要将返回地址(当前指令地址+8)保存到 ra($31)寄存器中。为什么是当前指令地址加8呢?这是因为紧随跳转指令之后有一条立即执行的延迟槽指令(例如nop占位指令),加8刚好是延迟槽后面的那条有效指令。从子程序返回是通过寄存器跳转完成,通常调用 jr ra。
基于 PC 相对寻址的位置无关子程序调用通过 bal、bgezal 和 bltzal 指令完成。条件分支和链接指令即使在条件为假的情况下,也会将它们的返回地址保存到 ra 中,这在需要基于当前指令地址做计算的场合非常有用。
b:相对当前指令地址(PC)的无条件短距离跳转指令。
bal:基于当前指令地址(PC)的函数调用指令。
RISC-V
寄存器
RISC-V共32个通用寄存器,以及PC寄存器
| Register | ABI Name | Saver | 作用 |
|---|---|---|---|
| x0 | zero | — | 硬编码恒为0 |
| x1 | ra | Caller | 函数调用的返回地址 |
| x2 | sp | Callee | 堆栈指针 |
| x3 | gp | — | 全局指针 |
| x4 | tp | — | 线程指针 |
| x5-7 | t0-2 | Caller | 临时寄存器/ |
| x8 | s0/fp | Callee | 保存寄存器/帧指针 |
| x9 | s1 | Callee | 保存寄存器 |
| x10-11 | a0-1 | Caller | 函数参数/返回值 |
| x12-17 | a2-7 | Caller | 函数参数 |
| x18-27 | s2-11 | Callee | 保存寄存器 |
| x28-31 | t3-6 | Caller | 临时寄存器 |
函数调用过程中可以直接改写的寄存器叫临时寄存器(t0~t6)。在调用过程中不能直接改写的寄存器值得叫保存寄存器(s0~s11)**,函数调用过程中如果要使用s0~s11,需要由被调用函数进行保护,保证在函数调用前后内部值不变。
栈帧与函数调用约定

寄存器与函数调用约定


跳转

POWER-PC
PowerPC(后称Performance Optimization With Enhanced RISC – Performance Computing,有时缩写为PPC)是一种精简指令集计算机(RISC)指令集架构(ISA),由 1991 年苹果-IBM-摩托罗拉联盟创建,称为AIM。PowerPC 作为一种不断发展的指令集,自 2006 年起被命名为Power ISA,而旧名称作为基于Power Architecture的处理器 的某些实现的商标继续存在。
数据类型
PowerPC支持的数据类型
| 名称 | 字长(bits) |
|---|---|
| Quadwords | 128 |
| Doublewords | 64 |
| Halfwords | 32 |
| Words | 16 |
| Bytes | 16 |
寄存器
PowerPC中的寄存器有非常多,ABI规定的寄存器包括专用寄存器、易失性寄存器和非易失性寄存器。
易失性寄存器代表任何函数都可以自由对这些寄存器进行修改,并且不用恢复这些寄存器之前的值;而非易失性寄存器则代表函数可以使用这些寄存器,但需要在函数返回前将这些寄存器的值恢复。
- GPR寄存器
General Purpose Rgister(GPR),通用寄存器,从GPR0到GPR31共32个。
事实上在gdb中所见就是r0~r31,其中:
| 寄存器 | 用途 |
| - | - |
| r0 | 发生系统调用时对应的系统调用号 |
| r1 | 堆栈指针 |
| r2 | 内容表(toc)指针,IDA把这个寄存器反汇编标识为rtoc。系统调用时,它包含系统调用号 |
| r3 | 函数调用时的第一个参数和返回值 |
| r4-r10 | 函数调用时参数传递 |
| r11 | 用在指针的调用和当作一些语言的环境指针 |
| r12 | 它用在异常处理和glink(动态连接器)代码 |
| r13 | 保留作为系统线程ID |
| r14-r31 | 作为本地变量,非易失性(要保存) |
- FPR寄存器
Floating-Point Register(FPR),浮点寄存器,用于浮点运算,从FPR0-FPR31共32个。每个FPR寄存器都支持双精度浮点格式,在64位和32位处理器实现上,FPRs都是64位的。
- LR寄存器
Link Register(LR),链接寄存器,可以为条件转移链接寄存器指令提供转移目标地址,并在LK=1的转移指令之后保存返回地址。
LK即LINK bit,为0时不设置链接寄存器LR;为1时设置连接寄存器LR,转移指令后面的指令地址被放置在链接寄存器LR中
注意尽管两个最低有效位可以接受任何写入的值,但当LR被用作地址时,它们会被忽略。有些处理器可能会保存转移最近设置的LR值的堆栈。
- CR寄存器
Condition Register(CR),条件寄存器,它反映某些操作的结果,并提供一种测试(和转移)的机制
条件寄存器中的位被分组为8个4位字段,命名为CR字段0(CR0),…,CR字段7(CR7)。CR字段可以通过一些指令进行设置,其中CR0可以是整数指令的隐式结果,CR1可以时浮点指令的隐式结果,指定的CR字段可以表示整数或浮点数比较指令的结果。

CR0字段含义如下
| Bits | 描述 |
| - | - |
| 0 | Negative(LT) - 结果为负时设置该位,即小于 |
| 1 | Positive(GT) - 结果为正数(非零)时设置该位,即大于 |
| 2 | Zero(EQ) - 结果为0时设置该位,即等于 |
| 3 | Summary overflow(SO) - 这是XER[SO]指令完成时的最终状态的副本 |
需要注意当溢出发生时,CR0可能不能反应真实的结果
- CTR寄存器
Count Register(CTR),计数器,可以用来保存循环计数;还可以用来为转移条件计数寄存器指令提供转移目标地址。
- XER寄存器
Fixed-Point Exception Register(XER),特殊寄存器,是一个64位寄存器,用来记录溢出和进位标志
| Bits | 描述 |
|---|---|
| 0:31 | 保留 |
| 32 | Summary Overflow(SO):每当指令(除mtspr)设置溢出位时,SO位被设置为1。一旦设置,SO位会保持设置知道被一个mtspr指令(指定XER)或一个mcrxr指令清除。它不会被compare指令修改,也不会被其他不能溢出的指令(除对XER的mtspr、mcrxr)改变 |
| 33 | Overflow(OV):执行指令时发生溢出设置。OV位不会被compare指令改变,也不会被其他不能溢出的指令(除对XER的mtspr、mcrxr)改变 |
| 34 | Carry(CA):在执行某些指令时,进位设置如下,加进位,减进位,加扩展,减扩展类型的指令,如果有M位的进位则设位1,否则设为0。执行右移代数指令时如果有任何1位移出了一个负操作数,设置其为1,否则设为0。CA位不会被compare指令改变,也不会被其他不能进位的指令(除代数右移、对XER的mtspr、mcrxr)改变 |
| 35:56 | 保留 |
| 57:63 | 该字段指定“加载字符串索引”或“存储字符串索引”指令传输的字节数 |
- FPSCR寄存器
Floating-Point Status and Control Register(FPSCR),浮点状态和控制寄存器,控制浮点异常的处理,并记录浮点操作产生的状态,其中0:23位是状态位,24:31位是控制位。浮点异常包括浮点数溢出异常、下溢异常、除零异常、无效操作异常等
- MSR
机器状态寄存器,MSR定义处理器的状态,用来配置微处理器的设定。
寄存器r1、r14-r31是非易失性的,这意味着它们的值在函数调用过程保持不变。寄存器r2也算非易失性,但是只有在调用函数在调用后必须恢复它的值时才被处理。
寄存器r0、r3-r12和特殊寄存器lr、ctr、xer、fpscr是易失性的,它们的值在函数调用过程中会发生变化。此外寄存器r0、r2、r11和r12可能会被交叉模块调用改变,所以函数在调用的时候不能采用它们的值。
条件代码寄存器字段cr0、cr1、cr5、cr6和cr7是易失性的。cr2、cr3和cr4是非易失性的,函数如果要改变它们必须保存并恢复这些字段。
| 序号 | 寄存器 | 功能 |
|---|---|---|
| 1 | GPR0-GPR31(共32个寄存器) | 整数运算和寻址通用寄存器.在ABI规范中,GPR1用于堆栈指针,GPR3-GPR4用于函数返回值,GPR3-GPR10用于参数传递 |
| 2 | FPR0-FPR31(共32个寄存器) | 用于浮点运算。PPC32和PPC64的浮点数都是64位 |
| 3 | LR | 连接寄存器,记录转跳地址,常用于记录子程序返回的地址。 |
| 4 | CR | 条件寄存器。 |
| 5 | XER | 特殊寄存器,记录溢出和进位标志,作为CR的补充 |
| 6 | CTR | 计数器,用途相当于ECX |
| 7 | FPSCR | 浮点状态寄存器,用于浮点运算类型的异常记录等,可设置浮点异常捕获掩码 |
常用指令
数据传送
加载数据
1 | lbz RT,D(RA) |
上述指令均表示以(EA)=(RA|0)+D/DS为有效地址加载字节到RT中,以偏移地址寻址。b,h,w,d分别代表字节、半字、字、双字,指加载的位数。z表示其他位清零,a表示其他位将被加载的数据的位0复制填充。
指令最后加一个x表示寄存器寻址,例如lbzx RT,RA,RB表示以(RA|0)+(RB)为有效地址加载字节到RT中。
存储数据
1 | stb RS,D(RA) |
都是类似加载指令的,同理上述指令均以偏移地址寻址,将RS的值存储到(RA|0)+D/DS地址中。如果最后加一个x则表示寄存器寻址。
跳转
控制转移
无条件转移
1 | b target_addr (AA = 0 LK = 0) |
target_addr指定转移目标地址,如果AA=0,那么转移目标地址是LI||0b00经符号符号拓展后加上指令地址;如果AA=1,那么转移目标地址为LI||0b00经符号拓展后的值。
如果LK=1,则转移指令的下一条指令的有效地址会被放置到链接寄存器LR中。B-Form指令长度32位(0-31),AA是30位,LK是31位
条件转移
1 | bc BO,BI,target_addr (AA = 0 LK = 0) |
BI字段表示作为转移条件的CR位,BO字段操作码对应具体如何进行转移
一些常见的转移条件
1 | lt <=> less than |
系统调用
1 | sc |
r0作为系统调用号
栈帧与函数调用约定
栈的概念在PPC等CPU中,不是由CPU实现的,而是由编译器维护的。通常情况下,在PPC中栈顶指针寄存器使用r1,栈底指针寄存器使用r11或r31。或者r11为栈顶,其他为栈底。根据不同的编译选项和编译器环境,其使用方式都有不同,但各个编译器的共识为r1是帧栈指针,其他寄存器都可根据他为准灵活使用。
栈帧在函数中,通常用于存储局部变量、编译器产生的临时变量等。由于PPC和ARM等CPU在寄存器较多,所以函数的形参和实参大多数情况下会使用寄存器,参数较多的情况下使用栈。
PowerPC体系结构中栈的增长方向同样是从高地址到低地址,堆的增长方式是从低地址到高地址,当两者相遇时就会产生溢出。
堆栈帧的格式如下:
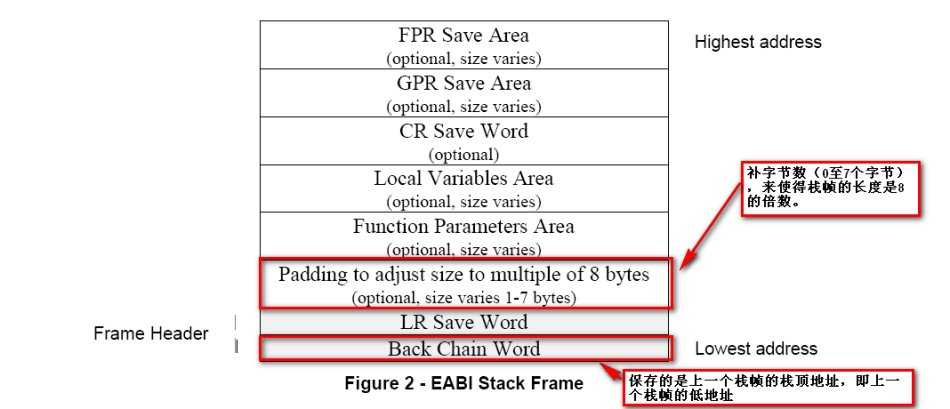
下面从一个例子分析PPC中栈帧的变化
1 | // powerpc-linux-gnu-gcc -static -g -o t t.c |
可以看到在进入函数的时候会先执行

r1就类似栈顶指针,第一条指令中,stwu最后的u表示update,指令中有效地址EA=r1+back_chain,该指令首先会将r1的值存放到EA中,接着会把有效地址EA存到r1里。back_chain对应新栈帧大小,是一个负值,此处为0x60,所以这里实际上就是开辟了一块新的栈帧,让r1指向新栈顶,同时在新栈顶处存储了上一个栈帧的栈顶,从而构成一个类似链表的东西,在之后帮助恢复栈帧。
mflr r0,把lr寄存器的值保存到r0中。接着stw将r0保存到栈上,从而在栈上保存了lr返回地址的值。指令中对栈变量的索引使用的是0x60+sender_lr(r1),r1已经指向新栈帧的栈顶,所以这里是通过栈顶指针索引栈上的局部变量,栈帧空间大小即0x60。
下一条stw指令将r31存储到栈上,然后执行mr把r1的值赋给r31。
接下来就是函数中的赋值和调用printf的操作了
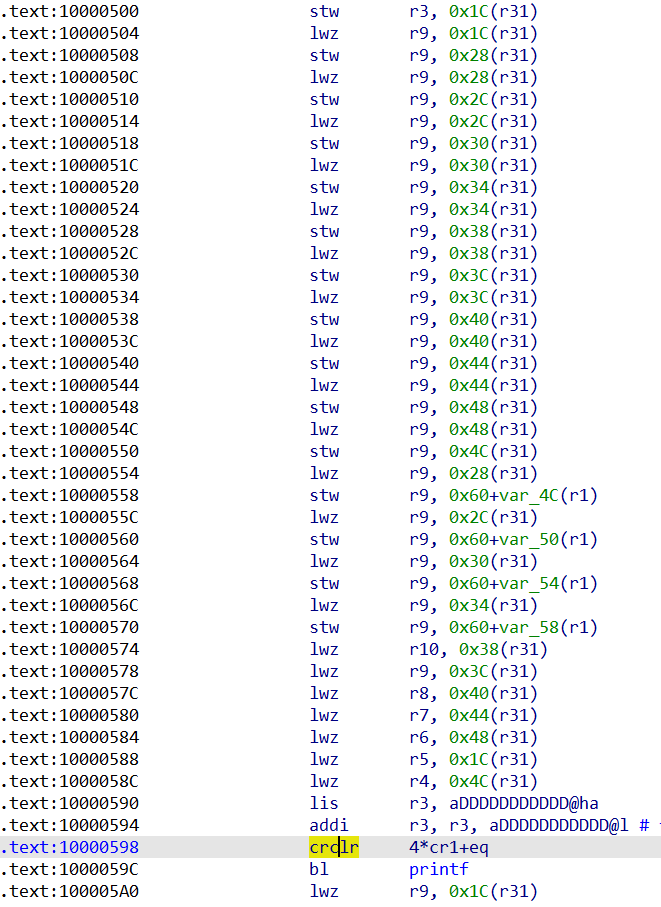
由于test函数传入了一个参数n,是通过r3传递的。所以在之后看到首先把r3存到了栈上,接着不断连续调用lwz和stw指令,以r9为中间量,并通过r31索引,对栈上局部变量进行赋值。
接下来就是为函数调用布置参数了,这里由于我们使用的参数很多,会同时使用寄存器和栈变量进行传参。ppc中没有push、pop这样的指令,栈帧空间是提前设置好的,这里指令做的就是把参数从右往左把多出来的4个参数依次在栈上从高地址往低地址放置,第9个参数与栈顶位置中间还会留下一个字长的空间,用来存放下一个栈帧的返回地址;剩下的8个参数按照从右往左依次放入r3~r10中,指定执行时是从r10开始存放的。crclr是用来调整条件寄存器CR的。
最后就是恢复函数栈帧
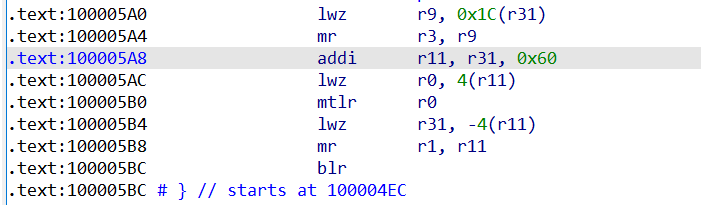
lwz将栈上的值赋给r9,再用mr把r9赋给r3,其实就是在传递函数的返回值`n
addi把上一个栈帧的栈顶地址存到r11里,然后索引到存放lr返回地址的位置把值放进r0,再通过mtlr r0把r0的值赋给lr寄存器,从而完成了返回地址的恢复。
接着lwz r31, -4(r11)即以上一个栈帧栈顶位置减4为有效地址取值存入r31,这一步是在恢复r31寄存器,对应开头进入函数时stw r31, 0x60+var_4(r1)在栈上保存的r31的值,因为它是非易失性寄存器需要恢复。
再把r11的值给r1,从而r1恢复指向原栈帧的栈顶,完成了函数的退栈操作。到这里也可以看出在ppc中是通过栈顶指针完成栈帧的开辟和弹出的,栈顶指针以链表形式链接,同时对局部变量的操作也是以栈顶为基址进行偏移索引的。
最后blr返回到原函数继续向下执行