llvm llvm包括许多内容, 这里只粗略介绍
LLVM(Low Level Virtual Machine)是苹果公司的开源编译器框架(最初是由Chris Lattner在2000年开发)
LLVM的架构采用了前后端分离的设计:
LLVM的一个核心概念是它的中间表示(Intermediate Representation,IR)。LLVM IR是一种LLVM定义的介于源码和汇编的中间语言, 语法类似于汇编, 具有三个形式:
LLVM位码(.bc) :一种二进制格式,通常用于文件存储或传输, 它体积小、解析快,适合在编译器内部和分布式编译中传输或存储中间表示。文本形式(.ll) :一种文本格式,便于阅读和调试,类似于汇编语言,包含指令、函数、基本块、变量等信息。内存形式 :内存形式是LLVM IR在内存中的数据结构表示,供LLVM的各种工具和优化器使用
ollvm OLLVM(Obfuscator-LLVM) 是瑞士西北应用科技大学安全实验室于2010年6月份发起的一个项目,该项目旨在提供一套开源的针对LLVM的代码混淆工具,以增加对逆向工程的难度
安装 1 2 3 4 git clone -b llvm-4.0 --depth=1 https://github.com/obfuscator-llvm/obfuscator.git sudo docker pull nickdiego/ollvm-build git clone --depth=1 https://github.com/oacia/docker-ollvm.git sudo docker-ollvm/ollvm-build.sh obfuscator/
使用docker进行编译, 编译需要一段时间
安装完成后即可在obfuscator/build_release/bin/目录下找到编译结果
之后我们选择一个小小的demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <stdio.h> #include <stdlib.h> int check_password (const char * input) { int sum = 0 ; for (int i = 0 ; input[i] != '\0' ; i++) { sum += input[i]; } return sum == 1000 ; } int complex_calculation (int a, int b) { int result = 0 ; if (a > b) { result = a * b + (a ^ b); } else { result = a + b * (a & b); } return result; } void print_message () { const char * msg = "Hello, OLLVM!" ; printf ("%s\n" , msg); } int main (int argc, char ** argv) { if (argc < 2 ) { printf ("Usage: %s <password>\n" , argv[0 ]); return 1 ; } if (check_password(argv[1 ])) { printf ("Password correct!\n" ); } else { printf ("Password wrong!\n" ); } int x = complex_calculation(10 , 20 ); printf ("Calculation result: %d\n" , x); print_message(); return 0 ; }
BCF(虚假控制流) 虚假控制流混淆主要通过加入包含不透明谓词的条件跳转和不可达的基本块,来干扰IDA的控制流分析和F5反汇编
也就是说一些跳转在运行之前就已经可以确定, 但IDA等工具却无法分析
例如
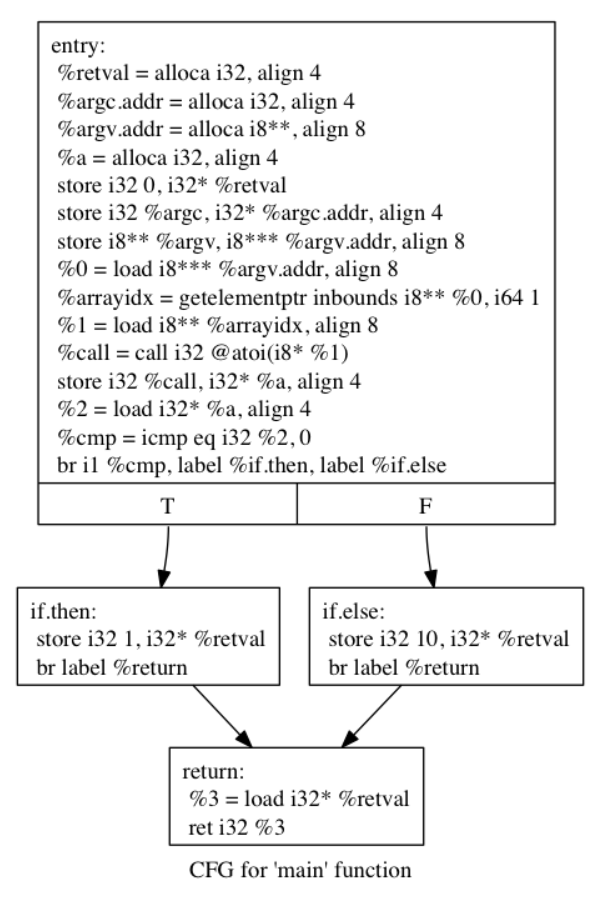
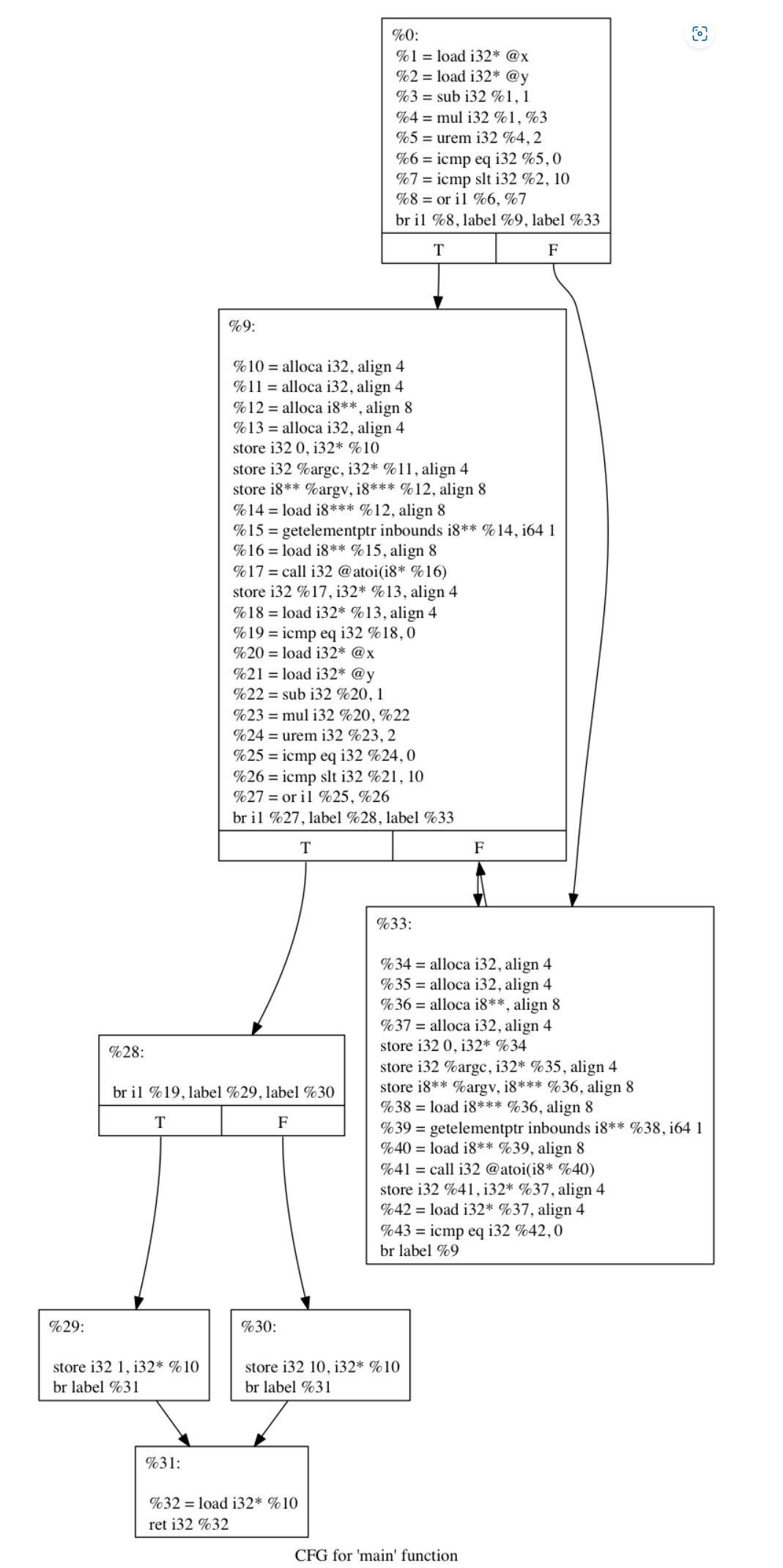
1 2 3 4 5 6 7 8 9 #include <stdlib.h> int main (int argc, char ** argv) { int a = atoi(argv[1 ]); if (a == 0 ) return 1 ; else return 10 ; return 0 ; }
混淆前
混淆后
混淆 使用ollvm对程序进行BCF混淆
1 clang -mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=40 test.c -o bcf
-mllvm -bcf: 激活虚假控制流-mllvm -bcf_loop=3 : 混淆次数,这里一个函数会被混淆 3 次,默认为 1-mllvm -bcf_prob=40 : 每个基本块被混淆的概率,这里每个基本块被混淆的概率为 40%,默认为 30 %
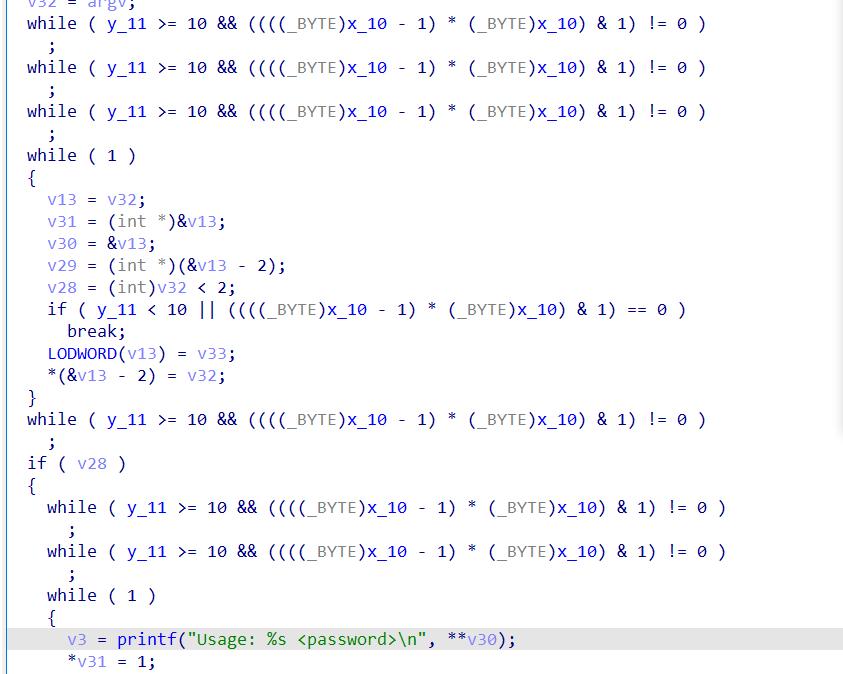
查看混淆后的结果
可以看到这个表达式y_11 >= 10 && ((((_BYTE)x_10 - 1) * (_BYTE)x_10) & 1) != 0
观察到(((_BYTE)x_10 - 1) * (_BYTE)x_10),也就是x * (x- 1),这个永远是一个偶数, 那么偶数在二进制的表示最低位肯定是0, 所以这个条件永远也不可能满足
但因为y_11和x_10是变量, IDA无法确定他们的值, 因此在反编译结果中保留了这部分代码
反混淆 消除不透明谓词 两种方案
第一种 : 将mov 寄存器, 不透明谓词全部改为mov 寄存器, 0
样例脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import ida_xrefimport ida_idaapifrom ida_bytes import get_bytes, patch_bytes def do_patch (ea ): if get_bytes(ea, 1 ) == b"\x8B" : reg = (ord (get_bytes(ea + 1 , 1 )) & 0b00111000 ) >> 3 patch_bytes(ea, (0xB8 + reg).to_bytes(1 ,'little' ) + b'\x00\x00\x00\x00\x90\x90' ) else : print ('error' ) seg = ida_segment.get_segm_by_name('.bss' ) start = seg.start_ea end = seg.end_ea for addr in range (start,end,4 ): ref = ida_xref.get_first_dref_to(addr) print (hex (addr).center(20 ,'-' )) while (ref != ida_idaapi.BADADDR): do_patch(ref) print ('patch at ' + hex (ref)) ref = ida_xref.get_next_dref_to(addr, ref) print ('-' * 20 )
第二种 : 将.bss段改为只读, 并且逐个对不透明谓词进行赋值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import ida_segmentimport ida_bytesseg = ida_segment.get_segm_by_name('.bss' ) for ea in range (seg.start_ea, seg.end_ea,4 ): ida_bytes.patch_bytes(ea, int (2 ).to_bytes(4 ,'little' )) ''' seg.perm: 由三位二进制数表示,例如一个segment为可读,不可写,不可执行,则seg.perm = 0b100 (seg.perm >> 2)&1: Read (seg.perm >> 1)&1: Write (seg.perm >> 0)&1: Execute ''' seg.perm = 0b100
模拟执行 使用angr或unicorn等模拟执行工具, 标记不可达块, 再将其nop
例如工具deflat )
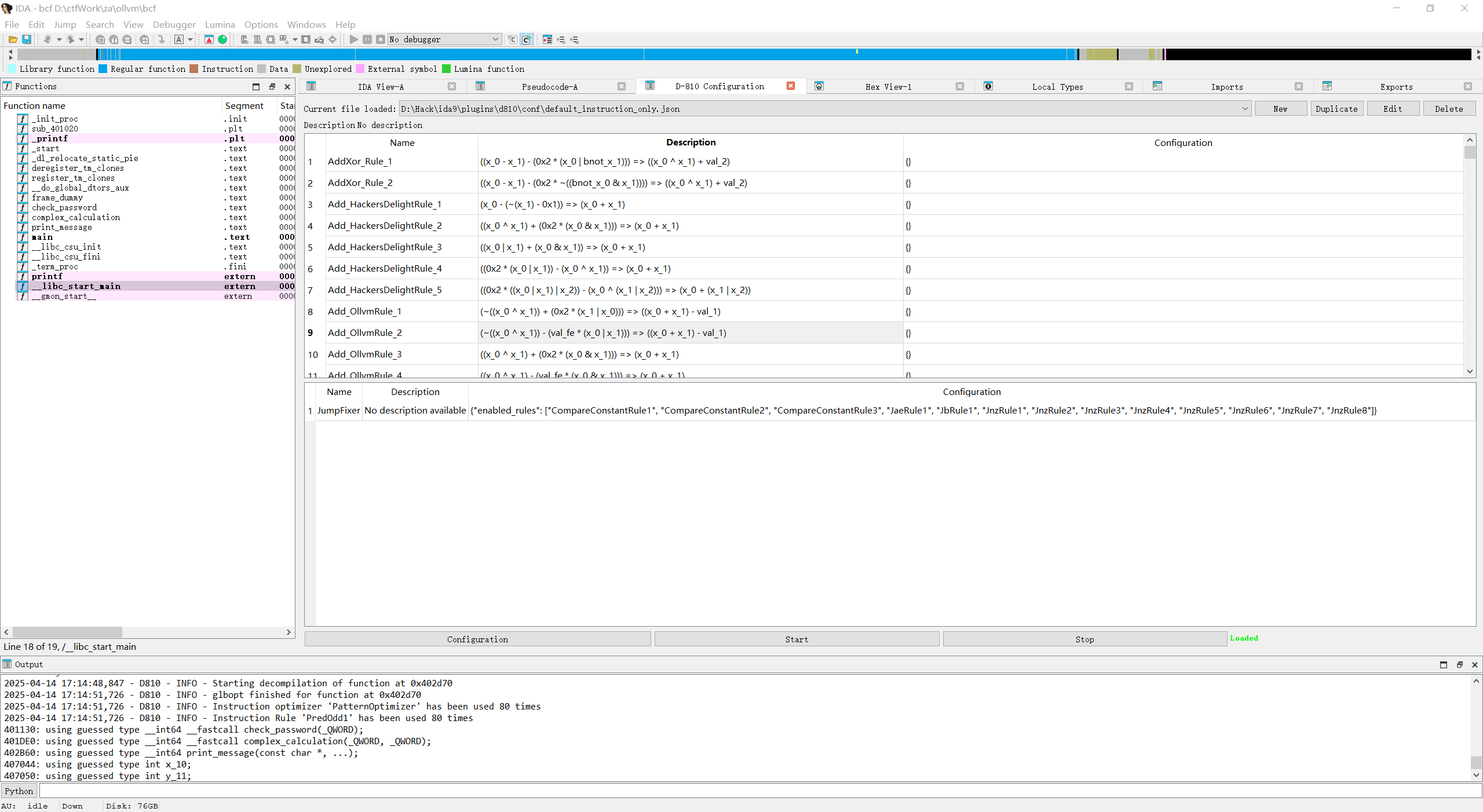
d810 d810 )是一个十分强大的IDA反混淆插件
安装后在Edit->plugins->D-810打开插件后, 选择规则, 点击start, 然后再次反编译函数即可
d810包含许多默认规则
适用于去虚假控制流, 去指令替换, 去平坦化等情况
d810添加规则 如果有配置文件不包含的情况出现, 可以额外添加配置
打开对应的配置文件\plugins\d810\conf\xxx.json
ins_rules属性添加一个成员
1 2 3 4 5 { "name" : "newrule" , "is_activated" : true , "config" : { } } ,
然后在根据具体的代码找到plugins\d810\optimizers\instructions\pattern_matching\rewrite_xxx.py, 新增对应的类
源码分析 源码在于/lib/Transforms/Obfuscation/BogusControlFlow.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 virtual bool runOnFunction (Function &F) if (ObfTimes <= 0 ) { errs ()<<"BogusControlFlow application number -bcf_loop=x must be x > 0" ; return false ; } if ( !((ObfProbRate > 0 ) && (ObfProbRate <= 100 )) ) { errs ()<<"BogusControlFlow application basic blocks percentage -bcf_prob=x must be 0 < x <= 100" ; return false ; } if (toObfuscate (flag,&F,"bcf" )) { bogus (F); doF (*F.getParent ()); return true ; } return false ; }
runOnFunction是拓展的pass类必须实现的入口
主要是检查了一下传入的混淆次数和概率是否合规, 然后使用toObfuscate判断是否传入了开启bcf的参数
接着就进入真正的混淆过程bogus
1 2 3 4 5 6 7 8 void bogus (Function &F) ++NumFunction; int NumBasicBlocks = 0 ; bool firstTime = true ; bool hasBeenModified = false ; DEBUG_WITH_TYPE ("opt" , errs () << "bcf: Started on function " << F.getName () << "\n" ); DEBUG_WITH_TYPE ("opt" , errs () << "bcf: Probability rate: " << ObfProbRate<< "\n" );
NumFunction用于记录处理过的函数数量,每调用一次 bogus 函数就会增加。
NumBasicBlocks用于统计当前函数中的基本块数量。
firstTime表示是否是第一次迭代该函数。在第一次迭代时进行一些额外的初始化操作。
hasBeenModified记录该函数是否经过修改(即是否插入了虚假的控制流)。
1 2 3 4 5 6 7 8 9 10 11 12 NumTimesOnFunctions = ObfTimes; int NumObfTimes = ObfTimes;do { DEBUG_WITH_TYPE ("cfg" , errs () << "bcf: Function " << F.getName () <<", before the pass:\n" ); DEBUG_WITH_TYPE ("cfg" , F.viewCFG ()); std::list<BasicBlock *> basicBlocks; for (Function::iterator i = F.begin (); i != F.end (); ++i) { basicBlocks.push_back (&*i); } DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Iterating on the Function's Basic Blocks\n" );
主循环对于每个函数,会执行 ObfTimes 次混淆操作。每次循环都会对该函数的基本块进行遍历。
获取基本块通过遍历函数中的所有基本块,将它们存储在 basicBlocks 列表中。之后对这些基本块进行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 while (!basicBlocks.empty ()){ NumBasicBlocks++; if ((int )llvm::cryptoutils->get_range (100 ) <= ObfProbRate){ DEBUG_WITH_TYPE ("opt" , errs () << "bcf: Block " << NumBasicBlocks <<" selected. \n" ); hasBeenModified = true ; ++NumModifiedBasicBlocks; NumAddedBasicBlocks += 3 ; FinalNumBasicBlocks += 3 ; BasicBlock *basicBlock = basicBlocks.front (); addBogusFlow (basicBlock, F); } else { DEBUG_WITH_TYPE ("opt" , errs () << "bcf: Block " << NumBasicBlocks <<" not selected.\n" ); } basicBlocks.pop_front (); if (firstTime){ ++InitNumBasicBlocks; ++FinalNumBasicBlocks; } } DEBUG_WITH_TYPE ("gen" , errs () << "bcf: End of function " << F.getName () << "\n" );if (hasBeenModified){ DEBUG_WITH_TYPE ("cfg" , errs () << "bcf: Function " << F.getName () <<", after the pass: \n" ); DEBUG_WITH_TYPE ("cfg" , F.viewCFG ()); } else { DEBUG_WITH_TYPE ("cfg" , errs () << "bcf: Function's not been modified \n" ); } firstTime = false ; } while (--NumObfTimes > 0 );
遍历基本块每次循环选择一个基本块进行处理。选择的条件是一个随机数(由 llvm::cryptoutils->get_range(100) 生成)是否小于等于 ObfProbRate,这决定了某个基本块是否被选择进行混淆。
如果基本块被选中,调用 addBogusFlow 函数在该基本块中插入虚假的控制流。addBogusFlow 是实际执行插入伪流逻辑的地方
观察addBogusFlow函数
1 2 3 4 5 6 7 BasicBlock::iterator i1 = basicBlock->begin (); if (basicBlock->getFirstNonPHIOrDbgOrLifetime ()) i1 = (BasicBlock::iterator)basicBlock->getFirstNonPHIOrDbgOrLifetime (); Twine *var; var = new Twine ("originalBB" ); BasicBlock *originalBB = basicBlock->splitBasicBlock (i1, *var); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: First and original basic blocks: ok\n" );
首先,获取基本块 basicBlock 中的第一个非 PHI 节点、调试信息或者生命周期指令的位置。如果存在这样的节点,将拆分操作从该位置开始。
调用 splitBasicBlock 方法将原始基本块 basicBlock 拆分为两个部分。splitBasicBlock返回切割的后半部分, 前半部分则存储在原来的指针
第一部分(basicBlock):只保留 PHI 节点(用于变量传递)、调试信息等,不包含实际指令。
第二部分(originalBB):包含原来的所有代码。
1 2 3 Twine * var3 = new Twine ("alteredBB" ); BasicBlock *alteredBB = createAlteredBasicBlock (originalBB, *var3, &F); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Altered basic block: ok\n" );
alteredBBoriginalBB 的修改版本,可能包含一些无用的指令或变形后的代码。看起来像是程序可能执行的分支,但实际上不会真正运行(因为条件总是跳转到 originalBB)。
createAlteredBasicBlock 函数返回一个与给定基本块类似的基本块,插入到给定基本块的紧后面与原始基本块链接。实现就不专门解析了
1 2 3 4 alteredBB->getTerminator ()->eraseFromParent (); basicBlock->getTerminator ()->eraseFromParent (); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Terminator removed from the altered" <<" and first basic blocks\n" );
移除原来的跳转指令(Terminator),准备插入新的控制流
1 2 3 4 5 6 7 Value * LHS = ConstantFP::get (Type::getFloatTy (F.getContext ()), 1.0 ); Value * RHS = ConstantFP::get (Type::getFloatTy (F.getContext ()), 1.0 ); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Value LHS and RHS created\n" );Twine * var4 = new Twine ("condition" ); FCmpInst * condition = new FCmpInst (*basicBlock, FCmpInst::FCMP_TRUE , LHS, RHS, *var4); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Always true condition created\n" );
建了一个浮动类型的常量 LHS 和 RHS,它们的值都是 1.0。随后,创建了一个 FCmpInst(浮动比较指令),用于比较 LHS 和 RHS。由于这两个值相等,因此条件永远为 true, 也就是总是走固定路径
1 2 3 BranchInst::Create (originalBB, alteredBB, (Value *)condition, basicBlock); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Terminator instruction in first basic block: ok\n" );
basicBlock 的末尾 现在变成一个 虚假的条件跳转:
如果 condition 为 true → 跳转到 originalBB(真实代码)。
如果 condition 为 false → 跳转到 alteredBB(假代码)。
但由于 condition 永远为 true,所以 alteredBB 永远不会执行,只是用来迷惑逆向分析者。
1 2 BranchInst::Create (originalBB, alteredBB); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Terminator instruction in altered block: ok\n" );
alteredBB 的末尾 直接跳回 originalBB,形成一个看似循环的结构。
1 2 3 4 5 6 BasicBlock::iterator i = originalBB->end (); Twine * var5 = new Twine ("originalBBpart2" ); BasicBlock * originalBBpart2 = originalBB->splitBasicBlock (--i , *var5); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Terminator part of the original basic block" << " is isolated\n" ); originalBB->getTerminator ()->eraseFromParent ();
把 originalBB 再切一次,分成:
originalBB(前半部分)。
originalBBpart2(后半部分,主要是原来的终止指令)
1 2 3 4 Twine * var6 = new Twine ("condition2" ); FCmpInst * condition2 = new FCmpInst (*originalBB, CmpInst::FCMP_TRUE , LHS, RHS, *var6); BranchInst::Create (originalBBpart2, alteredBB, (Value *)condition2, originalBB); DEBUG_WITH_TYPE ("gen" , errs () << "bcf: Terminator original basic block: ok\n" );
再插入一个虚假条件, 和之前一样,condition2 也 永远为 true,所以 originalBB 总是跳转到 originalBBpart2(真实代码)。
alteredBB 仍然只是摆设,不会真正执行
最终控制流结构
1 2 3 4 5 6 7 8 9 basicBlock (初始块) │ ├─ (condition=true) → originalBB (真实代码) │ │ │ ├─ (condition2=true) → originalBBpart2 (继续执行) │ └─ (condition2=false) → alteredBB (假代码,不会执行) │ └─ (condition=false) → alteredBB (假代码,不会执行) └──→ originalBB (跳回去)
实际执行路径(永远走 true 分支):
1 basicBlock → originalBB → originalBBpart2 → 继续执行
虚假路径(迷惑逆向分析者):
1 basicBlock → alteredBB → originalBB → ...
FLA(控制流平坦化) 控制流平坦化,主要通过一个主分发器来控制程序基本块的执行流程。该方法将所有基本代码放到控制流最底部,然后删除原理基本块之间跳转关系,添加次分发器来控制分发逻辑,然后过新的复杂分发逻辑还原原来程序块之间的逻辑关系。
序言:函数的第一个执行的基本块 主 (子)
分发器:控制程序跳转到下一个待执行的基本块
retn 块:函数出口
真实块:混淆前的基本块,程序真正执行工作的块
预处理器:跳转到主分发器
例如一个程序源代码是这样
1 2 3 4 5 6 7 8 9 #include <stdlib.h> int main (int argc, char ** argv) { int a = atoi(argv[1 ]); if (a == 0 ) return 1 ; else return 10 ; return 0 ; }
平坦化后就会变成这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdlib.h> int main (int argc, char ** argv) { int a = atoi(argv[1 ]); int b = 0 ; while (1 ) { switch (b) { case 0 : if (a == 0 ) b = 1 ; else b = 2 ; break ; case 1 : return 1 ; case 2 : return 10 ; default : break ; } } return 0 ; }
混淆 实现流程
添加一个随机数种子 blockID
保存所有的基本块
将代码中含有switch改为if
删除第一个基本块,第一个需要特殊处理
识别main中的if,并且删除跳转指令
插入一个switch指令
第一个块跳转到loopEntry块
把所有的block保存到switch语句
重新计算switch变量的值
处理不是条件跳转 直接删除jump 跳转到loopEnd 进行下一轮循环
处理条件跳转 对真分支和假分支进行相应处理 真则选择真的ID
如果源代码含有switch, 那么先将里面含switch的改为if-else,再将所有的if-else变为Switch的结果,所以多次进行控制流平坦化就会变得越来越复杂
使用ollvm进行平坦化混淆
1 clang -mllvm -fla -mllvm -split -mllvm -split_num=3 test.c -o fla
-mllvm -fla : 激活控制流扁平化-mllvm -split : 激活基本块拆分。与激活时结合使用可提高扁平化效果。-mllvm -split_num=3 : 如果激活此传递,则对每个基本块应用 3 次。默认:1
对于我们的demo, 混淆结果如下
反混淆 反混淆最重要的肯定区分所有的基本快
找到序言块,这是整个函数的入口
序言块的后继是主分发器
主分发器的前驱有两个,除了序言块外,另一个块就是预处理器
预处理器的前驱是真实块
除此之外的其他块是子分发器
d810 d810同样支持去平坦化, 选择规则default_unflatteing_ollvm点击start, 然后再次编译即可
模拟执行 工具deflat )
源码分析 源码在于/lib/Transforms/Obfuscation/Flattening.cpp
1 2 3 4 5 6 7 8 9 10 11 bool Flattening::runOnFunction (Function &F) Function *tmp = &F; if (toObfuscate (flag, tmp, "fla" )) { if (flatten (tmp)) { ++Flattened; } } return false ; }
runOnFunction判断是否开启了fla便进入真正的混淆过程
1 2 3 4 5 char scrambling_key[16 ];llvm::cryptoutils->get_bytes (scrambling_key, 16 ); FunctionPass *lower = createLowerSwitchPass (); lower->runOnFunction (*f);
生成16字节的随机密钥,用于后续 case 值的混淆, 并将switch语句转为if-else语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 for (Function::iterator i = f->begin (); i != f->end (); ++i) { BasicBlock *tmp = &*i; origBB.push_back (tmp); BasicBlock *bb = &*i; if (isa <InvokeInst>(bb->getTerminator ())) { return false ; } } if (origBB.size () <= 1 ) { return false ; } origBB.erase (origBB.begin ());
收集所有基本块, 但如果存在异常调用相关(InvokeInst 是一个特殊的调用指令,它用于异常处理机制)则不对该函数进行平坦化操作
如果基本快数量小于等于1, 那么就没有必要平坦化
1 2 3 4 5 Function::iterator tmp = f->begin (); insert->getTerminator ()->eraseFromParent ();
获取函数的第一个基本块(f->begin()), 检查该块的终止指令
如果是条件分支指令(BranchInst),获取其指针, 判断是否满足以下任一条件:
是条件分支(br->isConditional())
有多个后继块(getNumSuccessors() > 1)
如果满足上述条件,则在适当位置分割基本块, 默认在终止指令前分割, 如果块中有其他指令(size() > 1),则在倒数第二条指令前分割
将分割出的新块(tmpBB)加入原始块列表(origBB)的头部
无论是否分割,最终都会移除入口块的终止指令
1 2 3 4 5 6 switchVar = new AllocaInst (Type::getInt32Ty (f->getContext ()), 0 , "switchVar" , insert); new StoreInst ( ConstantInt::get (Type::getInt32Ty (f->getContext ()), llvm::cryptoutils->scramble32 (0 , scrambling_key)), switchVar, insert);
在栈上分配4字节内存空间作为switchvar, 同时用之前的key加密0并存储在switchvar
1 2 loopEntry = BasicBlock::Create (f->getContext (), "loopEntry" , f, insert); loopEnd = BasicBlock::Create (f->getContext (), "loopEnd" , f, insert);
在insert块之后创建基本块loopEntry, loopEnd
1 load = new LoadInst (switchVar, "switchVar" , loopEntry);
在loopEntry起始位置插入load指令, 读取switchVar的当前值, 结果用于后续switch条件判断
1 2 3 4 5 insert->moveBefore (loopEntry); BranchInst::Create (loopEntry, insert); BranchInst::Create (loopEntry, loopEnd); BasicBlock *swDefault = BasicBlock::Create (..., "switchDefault" , f, loopEnd); BranchInst::Create (loopEnd, swDefault);
将原入口块insert移到loopEntry之前, 并在原入口块末尾插入无条件跳转,跳转到loopEntry, 再使loopEnd块末尾无条件跳回loopEntry
创建名为”switchDefault”的默认case块, 该块直接跳转至loopEnd(理论上不可达)
1 2 3 4 switchI = SwitchInst::Create (&*f->begin (), swDefault, 0 , loopEntry); switchI->setCondition (load); f->begin ()->getTerminator ()->eraseFromParent (); BranchInst::Create (loopEntry, &*f->begin ());
创建switch指令将之前加载的switchVar值(load)设为判断条件
移除函数第一个块的原始终止指令, 插入新的无条件跳转,强制进入loopEntry
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 for (vector<BasicBlock *>::iterator b = origBB.begin (); b != origBB.end (); ++b) { BasicBlock *i = *b; ConstantInt *numCase = NULL ; i->moveBefore (loopEnd); numCase = cast <ConstantInt>(ConstantInt::get ( switchI->getCondition ()->getType (), llvm::cryptoutils->scramble32 (switchI->getNumCases (), scrambling_key))); switchI->addCase (numCase, i); }
物理重组基本块位置(视觉混淆), 将每个基本块注册为switch语句的一个case, 并为其分配自己的case值
1 2 3 4 5 6 7 8 9 10 11 for (vector<BasicBlock *>::iterator b = origBB.begin (); b != origBB.end (); ++b) { BasicBlock *i = *b; ConstantInt *numCase = NULL ; if (i->getTerminator ()->getNumSuccessors () == 0 ) { continue ; }
在往后的部分完成控制流状态机的动态调度逻辑,通过三种方式重构基本块终结指令
处理返回块 (无后继块)转换无条件跳转 (单后继)转换条件分支 (双后继)
这一块针对返回块保留原始指令不变
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 if (i->getTerminator ()->getNumSuccessors () == 1 ) { BasicBlock *succ = i->getTerminator ()->getSuccessor (0 ); i->getTerminator ()->eraseFromParent (); numCase = switchI->findCaseDest (succ); if (numCase == NULL ) { numCase = cast <ConstantInt>( ConstantInt::get (switchI->getCondition ()->getType (), llvm::cryptoutils->scramble32 ( switchI->getNumCases () - 1 , scrambling_key))); } new StoreInst (numCase, load->getPointerOperand (), i); BranchInst::Create (loopEnd, i); continue ; }
这部分代码的转换类似如下
1 2 3 4 5 6 7 8 9 10 原始结构: BBx: ... br label %BBy 转换后: BBx: ... store i32 encryptedCase, i32 * %switchVar br label %loopEnd
主要针对单后继情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 if (i->getTerminator ()->getNumSuccessors () == 2 ) { ConstantInt *numCaseTrue = switchI->findCaseDest (i->getTerminator ()->getSuccessor (0 )); ConstantInt *numCaseFalse = switchI->findCaseDest (i->getTerminator ()->getSuccessor (1 )); if (numCaseTrue == NULL ) { numCaseTrue = cast <ConstantInt>( ConstantInt::get (switchI->getCondition ()->getType (), llvm::cryptoutils->scramble32 ( switchI->getNumCases () - 1 , scrambling_key))); } if (numCaseFalse == NULL ) { numCaseFalse = cast <ConstantInt>( ConstantInt::get (switchI->getCondition ()->getType (), llvm::cryptoutils->scramble32 ( switchI->getNumCases () - 1 , scrambling_key))); } BranchInst *br = cast <BranchInst>(i->getTerminator ()); SelectInst *sel = SelectInst::Create (br->getCondition (), numCaseTrue, numCaseFalse, "" , i->getTerminator ()); i->getTerminator ()->eraseFromParent (); new StoreInst (sel, load->getPointerOperand (), i); BranchInst::Create (loopEnd, i); continue ; }
针对条件分支的后继, 完成工作如下
1 2 3 4 5 6 7 8 9 10 原始结构: BBx: ... br i1 %cond , label %TrueBB , label %FalseBB 转换后: BBx: %nextState = select i1 %cond , i32 encryptedTrueCase, i32 encryptedFalseCase store i32 %nextState , i32 * %switchVar br label %loopEnd
最后调用fixstack用于修复phi指令, 所谓phi指令就是llvm用于控制流合并点动态选择变量的指令
它主要用于解决 基本块之间的变量依赖问题,确保 SSA静态单赋值(在 SSA 形式中,每个变量只能被赋值一次)形式的正确性
PHI 指令在 控制流合并点(如前趋块有多个来源) 动态选择变量的值:
1 2 %result = phi i32 [ 1 , %entry ], [ 2 , %else ]
%result 的值取决于执行路径:
如果来自 %entry,则 %result = 1
如果来自 %else,则 %result = 2
因为phi指令依赖于其前驱块, 所以必须位于基本块的开头 , 且每个 [value, label] 对必须指向 当前基本块的前趋块(Predecessor)
1 2 3 4 5 6 7 block: %x = phi i32 [ 0 , %entry ], [ 1 , %loop ] block: %x = phi i32 [ 0 , %wrong_block ]
也就是说phi指令的工作依赖于前驱块, 但在控制流平坦化中基本快之间的前后关系被破坏了, 所以需要想办法修复
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 void fixStack (Function *f) std::vector<PHINode *> tmpPhi; std::vector<Instruction *> tmpReg; BasicBlock *bbEntry = &*f->begin (); do { tmpPhi.clear (); tmpReg.clear (); for (Function::iterator i = f->begin (); i != f->end (); ++i) { for (BasicBlock::iterator j = i->begin (); j != i->end (); ++j) { if (isa <PHINode>(j)) { PHINode *phi = cast <PHINode>(j); tmpPhi.push_back (phi); continue ; } if (!(isa <AllocaInst>(j) && j->getParent () == bbEntry) && (valueEscapes (&*j) || j->isUsedOutsideOfBlock (&*i))) { tmpReg.push_back (&*j); continue ; } } } for (unsigned int i = 0 ; i != tmpReg.size (); ++i) { DemoteRegToStack (*tmpReg.at (i), f->begin ()->getTerminator ()); } for (unsigned int i = 0 ; i != tmpPhi.size (); ++i) { DemotePHIToStack (tmpPhi.at (i), f->begin ()->getTerminator ()); } } while (tmpReg.size () != 0 || tmpPhi.size () != 0 ); }
该函数用于修复控制流平坦化后可能破坏的SSA形式 , 主要处理两种特殊情况:
PHI节点跨基本块依赖问题 (PHINode)寄存器值逃逸问题 (Value escaping)
通过将寄存器变量降级为栈变量(alloca/load/store),确保混淆后的IR仍然符合LLVM规范
tmpPhi收集所有的PHI指令节点
1 2 3 4 5 6 7 8 if (isa <PHINode>(j)) { PHINode *phi = cast <PHINode>(j); tmpPhi.push_back (phi); continue ; } DemotePHIToStack (tmpPhi.at (i), f->begin ()->getTerminator ());
效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ; 原始PHI %val = phi i32 [0 , %A], [1 , %B] ; 降级后 %val.addr = alloca i32 ; 在每个前趋块插入store A: store i32 0 , i32* %val.addr br label %merge B: store i32 1 , i32* %val.addr br label %merge merge: %val = load i32, i32* %val.addr
tmpReg收集所有的寄存器逃逸点
1 2 3 4 5 6 7 8 if (!(isa <AllocaInst>(j) && j->getParent () == bbEntry) && (valueEscapes (&*j) || j->isUsedOutsideOfBlock (&*i))) { tmpReg.push_back (&*j); } DemoteRegToStack (*tmpReg.at (i), f->begin ()->getTerminator ());
效果
1 2 3 4 5 6 7 %x = add i32 1 , 2 %x.addr = alloca i32 store i32 3 , i32 * %x.addr %x = load i32 , i32 * %x.addr
SUB(指令替换) 这种混淆技术的目标简单来说就是用功能等效但更复杂的指令序列来替换标准二进制运算符(如加法、减法或布尔运算符)。当有多个等效指令序列可供选择时,随机选择一个。
这种混淆方法相对简单,增加的安全性不多,因为它可以通过重新优化生成的代码轻松移除。然而,如果伪随机数生成器的种子值不同,指令替换会在生成的二进制文件中引入多样性。
目前只应用于整型, 如果是浮点数, 可能因为运算符的替换而导致舍入的误差和不必要的数值不精确
混淆 1 clang -mllvm -sub -mllvm -sub_loop=3 test.c -o sub
-mllvm -sub : 激活指令替换-mllvm -sub_loop=3: 如果该 Pass 被激活,则对一个函数应用它 3 次。默认:1
demo启用SUB后混淆效果如下
相对原本
1 2 3 4 5 6 7 8 9 int complex_calculation (int a, int b) { int result = 0 ; if (a > b) { result = a * b + (a ^ b); } else { result = a + b * (a & b); } return result; }
确实复杂了许多
反混淆 d810 又是神奇的d810
使用后可以看到少了许多
但依然还存在一些
gooMBA IDA自带的一个去混淆插件, 不过只能处理一些简单情况, 对ollvm产生的混淆效果并不太好
GAMBA 同样是去混淆, 不过输入基于表达式
HexRaysSA/goomba: gooMBA is a Hex-Rays Decompiler plugin to simplify Mixed Boolean-Arithmetic (MBA) expressions