前言 第一篇堆学习笔记主要还是基础性的知识要多一点,像malloc和free的流程都只是贴了张图,这篇文章则稍微更深入一点点。
无tcache malloc初始化 malloc的入口是是_libc_malloc:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void * __libc_malloc (size_t bytes) { mstate ar_ptr; void *victim; void *(*hook) (size_t , const void *) = atomic_forced_read (__malloc_hook); if (__builtin_expect (hook != NULL , 0 )) return (*hook)(bytes, RETURN_ADDRESS (0 )); arena_get (ar_ptr, bytes); victim = _int_malloc (ar_ptr, bytes); return victim; }
从代码可以看出,主要包含callback、arena_get、_int_malloc 这几步,我们把callback和arena_get当作初始化 的过程,_int_malloc作为实际分配 的过程,本文着重来看初始化的过程,下篇文章再看_int_malloc。
再额外说一下builtin_expect,它是gcc的扩展,用来允许程序员将最有可能执行的分支告诉编译器,这样编译器就可以对分支预测做一些优化,简单来讲就是在遇到分支的时候,先生成大概率分支的指令,这样指令cache的命中率会变高,具体细节可以参考gcc的官方文档(以GCC10.1为例:https://gcc.gnu.org/onlinedocs/gcc-10.1.0/gcc/Other-Builtins.html#Other-Builtins),有时也会将__builtin_expect指令封装为likely和unlikely宏,它们的定义如下所示:
1 2 3 4 #define __builtin_expect(expr, val) (expr) #define likely(expr) __builtin_expect(!!(expr), 1) #define unlikely(expr) __builtin_expect(!!(expr), 0)
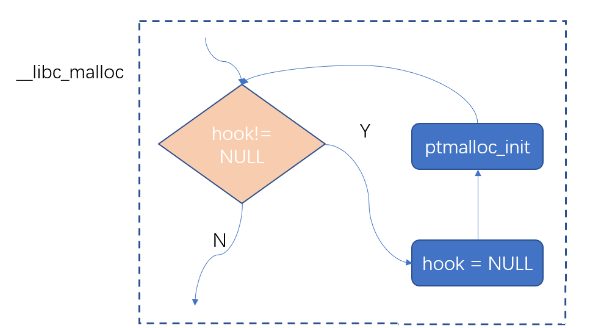
callback 先看前面代码1中的first part,如下两句,第一句是给函数指针变量赋值,第二句是函数调用:
1 2 3 4 void *(*hook) (size_t , const void *) = atomic_forced_read (__malloc_hook); if (__builtin_expect (hook != NULL , 0 )) return (*hook)(bytes, RETURN_ADDRESS (0 ));
hook是一个函数指针变量,被赋值成了__malloc_hook,后者定义如下:
1 2 3 void *weak_variable (*__malloc_hook) (size_t __size, const void *) = malloc_hook_ini;
__malloc_hook被初始化成了malloc_hook_ini,后者定义如下:
1 2 3 4 5 6 void * malloc_hook_ini (size_t sz, const void *caller) { __malloc_hook = NULL ; ptmalloc_init (); return __libc_malloc (sz); }
这里malloc_hook又被赋值成了NULL,然后再重新调用 libc_malloc,这样就可以保证在多次调用__libc_malloc的情况下,代码1中的hook回调函数只会被调用一次,如下图所示:
这个函数里的ptmalloc_init的精简定义如下:
1 2 3 4 5 6 7 8 9 10 void ptmalloc_init (void ) { if (__malloc_initialized >= 0 ) return ; __malloc_initialized = 0 ; thread_arena = &main_arena; malloc_init_state (&main_arena); __malloc_initialized = 1 ; }
可以看到通过__malloc_initialized这个全局flag来检测是不是已经初始化过了,如果没有,则把main_arena设成当前的thread_arena,这是因为初始化肯定是主线程在做,而主线程用的是main_arena,然后再调用malloc_init_state进一步初始化,malloc_init_state定义如下:
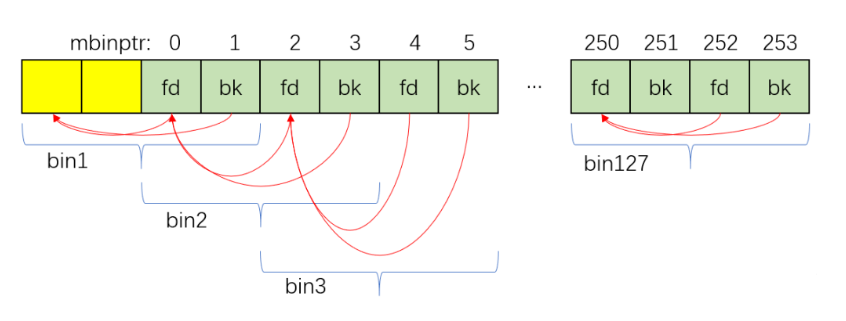
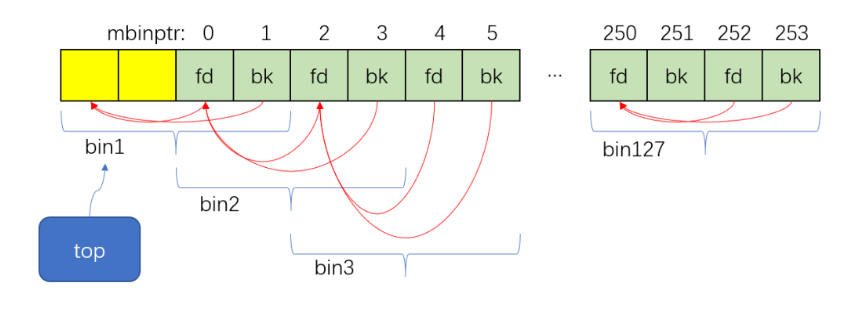
1 2 3 4 5 6 7 8 9 10 11 12 13 void malloc_init_state (mstate av) { int i; mbinptr bin; for (i = 1 ; i < NBINS; ++i) { bin = bin_at (av, i); bin->fd = bin->bk = bin; } if (av == &main_arena) set_max_fast(DEFAULT_MXFAST); av->top = initial_top (av); }
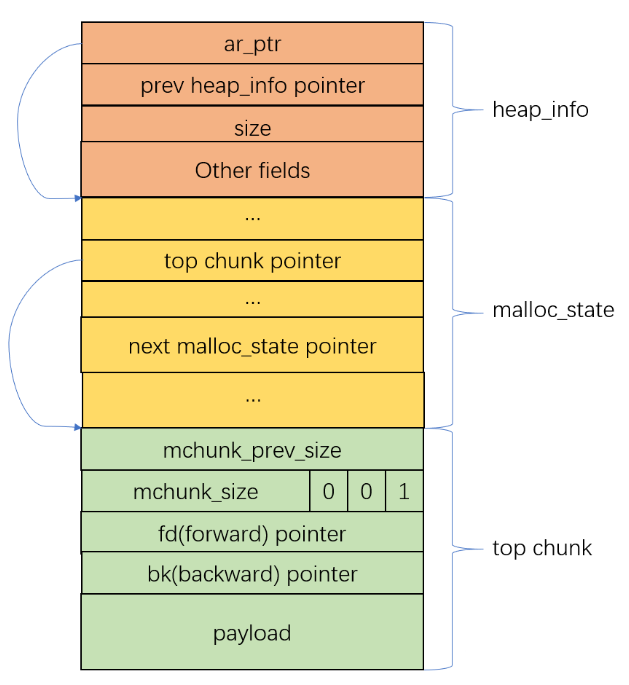
malloc_init_state的part1把malloc_state中的bins array初始化成了下图所示:
malloc_init_state的part2把malloc_state中的top初始化成了指向上图2中的bin1,修改top后如下图所示:
arena_get 介玩意是个宏,源代码里有一段解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #define arena_get(ptr, size) do { \ ptr = thread_arena; \ arena_lock (ptr, size); \ } while (0) #define arena_lock(ptr, size) do { \ if (ptr) \ __libc_lock_lock (ptr->mutex); \ else \ ptr = arena_get2 ((size), NULL); \ } while (0)
arena_get可以精简成如下代码:
1 2 3 4 5 #define arena_get(ptr, size) do { \ ptr = thread_arena; \ if (ptr) { __libc_lock_lock (ptr->mutex); } \ else { ptr = arena_get2 ((size), NULL); } \ } while (0)
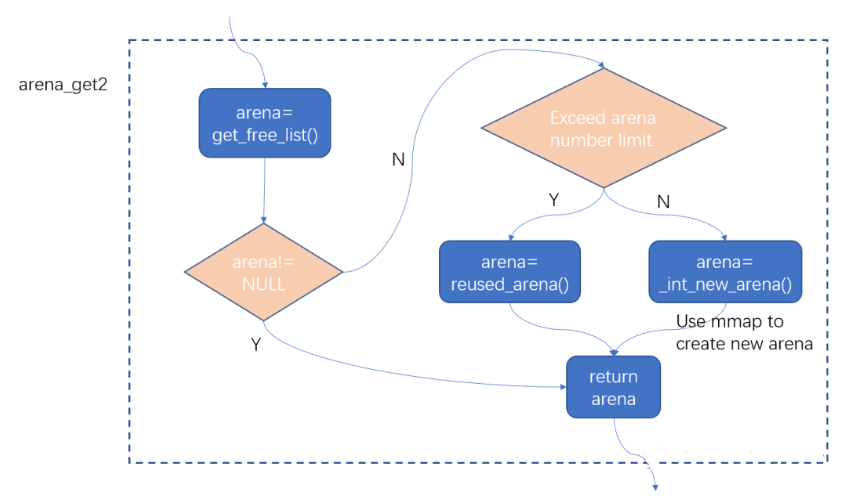
可见主要的实现在arena_get2这个函数里,它的主要作用是为当前线程获取一个可用的arena,这个函数的实现很复杂,考虑了各种情况,函数里又嵌套调用了多个函数,我把关键的流程总结在下图里:
上图可以看到,arena_get2的flow里主要调用了get_free_list、reused_arena、_int_new_arena这三个函数,这里不详细讲解每一个函数了,它们的作用从函数名就可以看出来,这三个函数里面_int_new_arena更重要一些,后面着重讲一下这一个函数。
_int_new_arena 这个函数如前图所示,它是用来在arena的个数超出限制之前创建新的arena的,关键代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static mstate _int_new_arena(size_t size) { heap_info *h = new_heap(size + (sizeof (heap_info) + sizeof (malloc_state) + MALLOC_ALIGNMENT), mp_.top_pad); if (!h) { h = new_heap (sizeof (heap_info) + sizeof (malloc_state) + MALLOC_ALIGNMENT, mp_.top_pad); if (!h) return 0 ; } malloc_state *a = h->ar_ptr = (malloc_state *) (h + 1 ); malloc_init_state (a); a->attached_threads = 1 ; a->system_mem = a->max_system_mem = h->size; char *ptr = (char *)(a + 1 ); top(a) = (mchunkptr)ptr; set_head(top(a), (((char *)h + h->size) - ptr) | PREV_INUSE); thread_arena = a; a->next = main_arena.next; main_arena.next = a; return a; }
下面再用一张memory layout的图示来展示刚创建过的arena长什么样子:
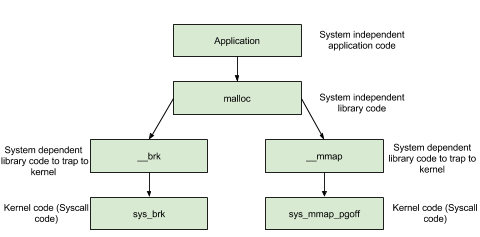
前面的_int_new_arena函数中调用了new_heap这个函数,这个函数主要是通过mmap对应的系统调用来通过操作系统分配空间,精简过的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static heap_info *new_heap (size_t size, size_t top_pad) { char *p2 = (char *)MMAP(aligned_heap_area, HEAP_MAX_SIZE, PROT_NONE, MAP_NORESERVE); if (__mprotect(p2, size, mtag_mmap_flags | PROT_READ | PROT_WRITE) != 0 ) { __munmap (p2, HEAP_MAX_SIZE); return 0 ; } heap_info *h = (heap_info *)p2; h->size = size; h->mprotect_size = size; return h; }
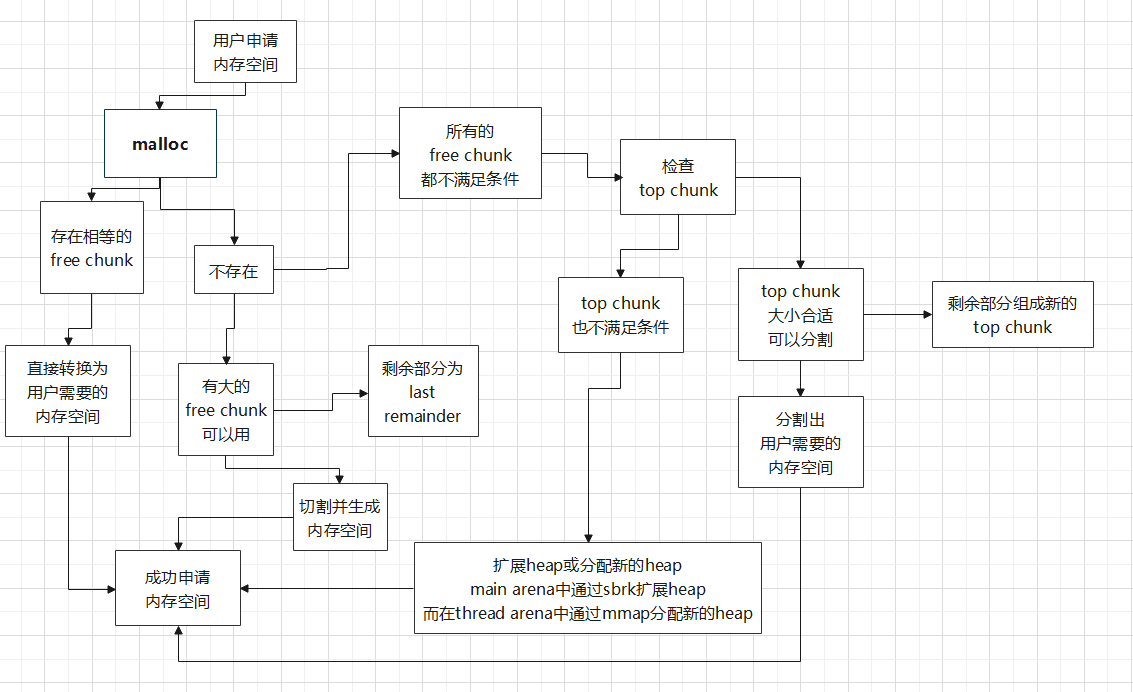
_int_malloc 还是先贴一个总流程图:
(s)brk
brk(*pointer)
sbrk(size)
二者都返回拓展后的当前堆的末尾地址
CAS操作 在malloc的实现中,需要频繁的插入和删除各个bin中的chunk,很多地方用到了CAS操作,因为用的比较多,这里先简单介绍一下
CAS是compare and swap的缩写,它是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题,该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
CAS需要有3个操作数:内存地址V,旧的预期值A,即将要更新的目标值B,CAS指令执行时,当且仅当内存地址V的值与预期值A相等时,将内存地址V的值修改为B,否则就什么都不做,整个比较并替换的操作是一个原子操作,下面举一个例子:
1 2 3 4 5 6 7 8 #define REMOVE_FB(fb, victim, pp) \ do { \ victim = pp; \ if (victim == NULL) \ break; \ pp = REVEAL_PTR(victim->fd); \ } while ((pp = catomic_compare_and_exchange_val_acq \ (fb, pp, victim)) != victim);
上面这段代码是用来从fast bin中删除一个chunk,我们这里只关注catomic_compare_and_exchange_val_acq(fb, pp, victim) 这个函数调用,其中fb是表头,pp新的节点,victim是老的节点,需要把老节点删掉,把新节点接上,这个调用就是通过CAS操作保证thread-safe的,以x86平台为例,一直往下追,最底层的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 #define __arch_c_compare_and_exchange_val_32_acq(mem, newval, oldval) \ ({ \ __typeof(*mem) ret; \ __asm __volatile("cmpl $0, %%" SEG_REG ":%P5\n\t" \ "je 0f\n\t" \ "lock\n" \ "0:\tcmpxchgl %2, %1" \ : "=a" (ret), "=m" (*mem) \ : BR_CONSTRAINT(newval), "m" (*mem), "0" (oldval), \ "i" (offsetof(tcbhead_t, multiple_threads))); \ ret; \ })
这是一段x86的内联汇编,GCC的内联汇编语法大家可以自行查阅相关资料,这里只关注lock和cmpxchgl这两个指令,lock确保对内存的read/write操作原子执行,cmpxchgl用来比较并交换操作数,所以归根结底,CAS操作还是通过硬件指令的支持才能实现原子操作。
从fastbin分配 在_int_malloc的开始,先看申请的内存大小nb是否符合fast bin的限制,符合的话,首先进入fast bin的分配代码:
1 2 3 4 5 6 7 8 9 10 11 if (nb <= get_max_fast()) { idx = fastbin_index(nb); mfastbinptr *fb = &fastbin(av, idx); mchunkptr pp; if ((victim = *fb) != NULL ) { REMOVE_FB(fb, pp, victim); void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; } }
会根据nb得到fast bin的index,再根据index,得到指向所在bin的head指针fb,如果这个bin非空,则取第一个chunk,使用前面介绍的REMOVE_FB将其从所在bin删除,并将取到的chunk返回。
从smallbin分配 不符合fast bin分配条件的话,会继续看是否符合small bin的分配条件,这部分的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (in_smallbin_range(nb)) { idx = smallbin_index(nb); bin = bin_at(av, idx); if ((victim = last(bin)) != bin) { bck = victim->bk; set_inuse_bit_at_offset(victim, nb); bin->bk = bck; bck->fd = bin; if (av != &main_arena) set_non_main_arena(victim); check_malloced_chunk(av, victim, nb); void *p = chunk2mem(victim); alloc_perturb(p, bytes); return p; } }
这里的处理过程和fast bin类似,也是根据nb定位到所在的bin,所在bin非空的话,就分配成功,返回得到的chunk,并且从所在bin中删除,和fast bin的最大不同之处在于这里操作的是双向链表。
merge fast bin into unsorted bin 在fast bin和small bin都分配失败之后,会把fast bin中的chunk进行一次整理合并,然后将合并后的chunk放入unsorted bin中,这是通过malloc_consolidate这个函数完成的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static void malloc_consolidate (mstate av) { atomic_store_relaxed (&av->have_fastchunks, false ); unsorted_bin = unsorted_chunks(av); maxfb = &fastbin(av, NFASTBINS - 1 ); fb = &fastbin (av, 0 ); do { p = atomic_exchange_acq (fb, NULL ); if (p != 0 ) { do { } while ((p = nextp) != 0 ); } } while (fb++ != maxfb); }
尝试从unsorted bin中分配 这部分代码已经进入_int_malloc中最后那个最大的for循环了,这部分的工作在for循环的刚开始,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 for (;;) { int iters = 0 ; while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) { bck = victim->bk; size = chunksize(victim); mchunkptr next = chunk_at_offset(victim, size); if (in_smallbin_range(nb) && bck == unsorted_chunks(av) && victim == av->last_remainder && size > (nb + MINSIZE)) { return p; } if (size == nb) { return p; } if (in_smallbin_range(size)) { } else { } if (++iters >= 10000 ) break ; } }
尝试从large bin中分配 这是_int_malloc中最后那个大for循环的第二部分代码,在从unsorted bin分配失败之后,准备从large bin分配:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 for (;;) { if (!in_smallbin_range(nb)) { bin = bin_at(av, idx); victim = first(bin); if (victim != bin && chunksize_nomask(victim) >= nb) { return p; } } ++idx; bin = bin_at(av, idx); block = idx2block(idx); map = av->binmap[block]; bit = idx2bit(idx); for (;;) { } }
尝试从top chunk中分配 这是_int_malloc中最后那个大for循环的第三部分代码,在从large bin分配失败之后,准备从top chunk分配:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 for (;;) { use_top: victim = av->top; size = chunksize(victim); if (size >= (nb + MINSIZE)) { remainder_size = size - nb; remainder = chunk_at_offset(victim, nb); av->top = remainder; set_head(victim, ...); set_head(remainder, remainder_size | PREV_INUSE); void *p = chunk2mem(victim); return p; } else if (av->have_fastchunks) { malloc_consolidate(av); if (in_smallbin_range(nb)) idx = smallbin_index(nb); else idx = largebin_index(nb); } else { void *p = sysmalloc(nb, av); return p; } }
free入口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void __libc_free(void *mem) { void (*hook)(void *, const void *) = atomic_forced_read(__free_hook); if (__builtin_expect(hook != NULL , 0 )) { (*hook)(mem, RETURN_ADDRESS(0 )); return ; } if (mem == 0 ) return ; mchunkptr p = mem2chunk(mem); if (chunk_is_mmapped(p)) { munmap_chunk(p); } else { mstate ar_ptr = arena_for_chunk(p); _int_free(ar_ptr, p, 0 ); } }
上面代码分成了part1/2/3三部分:
part1:调用回调函数,追代码可以发现,这个回调函数为NULL
part2:允许free(0)这样的调用,即什么都不做,直接返回
part3:判断所释放的空间是不是使用mmap分配得到的,如果是mmap分配得到的,就使用munmap来释放,如果不是的话,就调用_int_free这个主释放函数来释放,后面就来重点分析这个函数
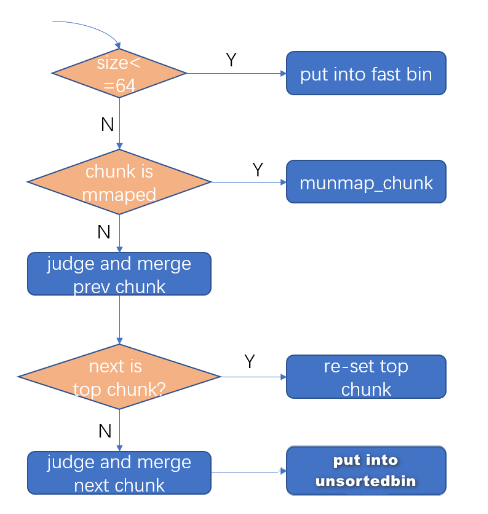
_int_free 先贴流程
根据上图,free时先是判断chunk size是不是处在fast bin的范围,是的话就把该chunk放入fast bin中,把chunk放入fast bin的操作是一个CAS操作.
通过代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if (size <= get_max_fast()) { free_perturb(chunk2mem(p), size - CHUNK_HDR_SZ); atomic_store_relaxed (&av->have_fastchunks, true ); unsigned int idx = fastbin_index(size); fb = &fastbin (av, idx); mchunkptr old = *fb, old2; do { old2 = old; p->fd = PROTECT_PTR(&p->fd, old); } while ((old = catomic_compare_and_exchange_val_rel(fb, p, old2)) != old2); }
上面代码除了前面提到的CAS操作,还有两个点值得注意一下:
使用freeperturb函数来改变一下所释放空间的原来内容,这个要在设置了glibc.malloc.perturb或者MALLOC_PERTURB 环境变量的时候才会起作用
PROTECT_PTR的底层原理实际上是一种safe-linking的安全机制,它利用了ASLR(地址空间布局随机化)中的随机性,可以很有效的防止UAF漏洞,这部分很有意思,黑客的入门题,以后有时间再专门写篇文章研究下,这里只简单提下
如果chunk size不属于fast bin的范围,继续判断是不是由mmap分配产生,如果由mmap分配产生,则使用munmap_chunk这个函数来进行free,munmap_chunk的主要代码也一并列在了下面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 if (chunk_is_mmapped(p)) { munmap_chunk (p); } static void munmap_chunk (mchunkptr p) { size_t pagesize = GLRO(dl_pagesize); INTERNAL_SIZE_T size = chunksize (p); uintptr_t mem = (uintptr_t )chunk2mem(p); uintptr_t block = (uintptr_t )p - prev_size(p); size_t total_size = prev_size(p) + size; if (((block | total_size) & (pagesize - 1 )) != 0 || (!powerof2(mem & (pagesize - 1 )))) malloc_printerr("invalid pointer" ); atomic_decrement(&mp_.n_mmaps); atomic_add (&mp_.mmapped_mem, -total_size); __munmap((char *)block, total_size); }
这个判断的原理很简单,都知道malloc的chunk header中有A、M、P 3个bit的flag,其中的M就是表示该chunk是不是由mmap系统调用产生,这个判断宏定义如下:
1 2 #define IS_MMAPPED 0x2 #define chunk_is_mmapped(p) ((p)->mchunk_size & IS_MMAPPED)
如果chunk不是由mmap分配,先判断该chunk的prev chunk是不是free state,如果是的话,需要和prev chunk进行merge:
1 2 3 4 5 6 7 if (!prev_inuse(p)) { prevsize = prev_size (p); size += prevsize; p = chunk_at_offset(p, -((long ) prevsize)); unlink_chunk (av, p); }
然后再判断next chunk是不是top chunk,是的话,重新设置top chunk:
1 2 3 4 5 6 7 8 nextchunk = chunk_at_offset(p, size); nextsize = chunksize(nextchunk); if (nextchunk == av->top) { ize += nextsize; set_head(p, size | PREV_INUSE); av->top = p; check_chunk(av, p); }
如果next chunk不是top chunk,有两种情况,如果是free state的话,则继续merge,如果是allocated state的话,则改变其P(PREV_INUSE) flag,最后把要free的chunk放入unsorted bin中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 nextchunk = chunk_at_offset(p, size); nextsize = chunksize(nextchunk); nextinuse = inuse_bit_at_offset(nextchunk, nextsize); if (!nextinuse) { unlink_chunk (av, nextchunk); size += nextsize; } else { clear_inuse_bit_at_offset(nextchunk, 0 ); } bck = unsorted_chunks(av); fwd = bck->fd; p->fd = fwd; p->bk = bck; if (!in_smallbin_range(size)) { p->fd_nextsize = NULL ; p->bk_nextsize = NULL ; } bck->fd = p; fwd->bk = p; set_head(p, size | PREV_INUSE); set_foot(p, size);
最后还要看下merge过后的chunk size是否达到FASTBIN_CONSOLIDATION_THRESHOLD这个阈值(默认大小是65536),达到的话要做一次malloc_consolidate操作(free fast bin中的chunk到unsorted bin中),对非main arena还要做一下heap_trim操作:
1 2 3 4 5 6 7 8 9 if (size >= FASTBIN_CONSOLIDATION_THRESHOLD) { if (atomic_load_relaxed (&av->have_fastchunks)) malloc_consolidate(av); if (av =!&main_arena) { heap_info *heap = heap_for_ptr(top(av)); assert(heap->ar_ptr == av); heap_trim(heap, mp_.top_pad); } }
这段代码中的heap_for_ptr这个宏是用来得到当前heap的heap_info的,从它的定义可以验证heap_info这个数据结构的一些特性,值得看一下:
1 2 3 #define heap_for_ptr(ptr) \ ((heap_info *)((unsigned long)(ptr) & ~(HEAP_MAX_SIZE - 1)))
有tcache 以上都是不考虑tcache的情况(libc<2.26),有tcache其实变化也并不是太大。
相关数据结构:
1 2 3 4 5 6 7 8 9 10 11 typedef struct tcache_entry { struct tcache_entry *next ; } tcache_entry; typedef struct tcache_perthread_struct { char counts[TCACHE_MAX_BINS]; tcache_entry *entries[TCACHE_MAX_BINS]; } tcache_perthread_struct;
tcache也是使用 类似 bins 方式来管理tcache 。
tcache_perthread_struct是整个tcache
每一项由 相同大小的 chunk 通过 tcache_entry 使用单向链表链接(类似于fastbin的链接方式)。
counts 用于记录 entries 中每一项当前链入的 chunk 数目, 最多可以有 7 个 chunk。
tcache_entry 用于链接 chunk 的结构体, 其中就只有一个 next 指针,指向下一个相同大小的 chunk.,也就说明tcache链上的成员只记录了fd指针
tcache中chunk大小范围0x20-0x410
基础操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static __always_inline void tcache_put (mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *) chunk2mem (chunk); assert (tc_idx < TCACHE_MAX_BINS); e->next = tcache->entries[tc_idx]; tcache->entries[tc_idx] = e; ++(tcache->counts[tc_idx]); } static __always_inline void *tcache_get (size_t tc_idx) { tcache_entry *e = tcache->entries[tc_idx]; assert (tc_idx < TCACHE_MAX_BINS); assert (tcache->entries[tc_idx] > 0 ); tcache->entries[tc_idx] = e->next; --(tcache->counts[tc_idx]); return (void *) e; }
通过这段代码能更好地理解上面两个结构体.
tcache_put 用于把一个 chunk 放到 指定的 tcache->entries 里面去, tc_idx 通过 csize2tidx (nb) 计算得到 (nb是 chunk 的大小)。
它首先把 chunk+2SIZE_SZ (就是除去 header 部分) 强制转换成 tcache_entry 类型,e指针也就指向了mem,然后修改mem的头字段(现在被视为entery的next指针)为之前的该entery的第一个chunk,然后再把entery的值改为e指针,最后把 tcache->counts[tc_idx] 加 1 ,表示新增了一个 chunk 到 该 表项。
tcache内的chunk不写该AMP三位,chunk之间不进行合并,且放入tcache的chunk哪怕与topchunk相邻也不会进行合并
tcache_get 简单来说就是put的逆操作,不多说.
得到tc_idx的宏定义
1 # define csize2tidx(x) (((x) - MINSIZE + MALLOC_ALIGNMENT - 1) / MALLOC_ALIGNMENT)
基本工作
第一次 malloc 时,会先 malloc 一块内存用来存放 tcache_perthread_struct 。
单链表tcache_entry,也即tcache Bin的默认最大数量是64 ,在64位程序中申请的最小chunk size为32,之后以16字节依次递增,所以size大小范围是0x20-0x410,也就是说我们必须要malloc size≤0x408的chunk
free 内存,且 size 小于 small bin size 时
先放到对应的 tcache 中,直到 tcache 被填满(默认是 7 个)(p位不置零故不合并 )
tcache 被填满之后,再次 free 的内存和之前一样被放到 fastbin 或者 unsorted bin 中
tcache 中的 chunk 不会合并(不取消 inuse bit)
malloc 内存,且 size 在 tcache 范围内
先从 tcache 取 chunk,直到 tcache 为空
tcache 为空后,从 bin 中找
tcache 为空时,如果 fastbin/smallbin/unsorted bin 中有 size 符合的 chunk,会先把 fastbin/smallbin/unsorted bin 中的其他chunk 放到 tcache 中,直到填满。之后再从 tcache 中取;因此 chunk 在 bin 中和 tcache 中的顺序会反过来
上一条第三点详细说
如果从 fastbin 中成功返回了一个需要的 chunk,那么对应 fastbin 中的其他 chunk 会被放进相应的 tcache bin 中,直到上限。需要注意的是 chunks 在 tcache bin 的顺序和在 fastbin 中的顺序是反过来的。
smallbin 中的情况与 fastbin 相似,双链表中的剩余 chunk 会被填充到 tcache bin 中,直到上限。
binning code(chunk合并等其他情况)中,每一个符合要求的 chunk 都会优先被放入 tcache,而不是直接返回(除非tcache被装满)。寻找结束后,tcache 会返回其中一个。
End 这篇文章较上一篇更多东西是缝上去的,归纳整理的成分更多,自己总结的少一点。