fuzzer应该是二进制安全学习者的必修项目,互联网上开源可供使用的fuzzer成百上千,专品精品应有尽有,但没什么比自己动手写一个fuzzer更好的学习方法了
这里跟随国外的h0mbre大佬的caveman系列从一个最简单的fuzzer开始动手
A Simple Start
从写一个宝宝级的fuzzer开始
STEPⅠ
以一个exif格式分析程序为目标程序mkttanabe/exif: simple implementation to access the Exif segment in the JPEG file切入我们的fuzzer分析
那么有必要稍微了解一下带exif的jpg格式规范
exif是一种为数码相机照片设定的档案格式,可以存储拍摄出照片的部分信息
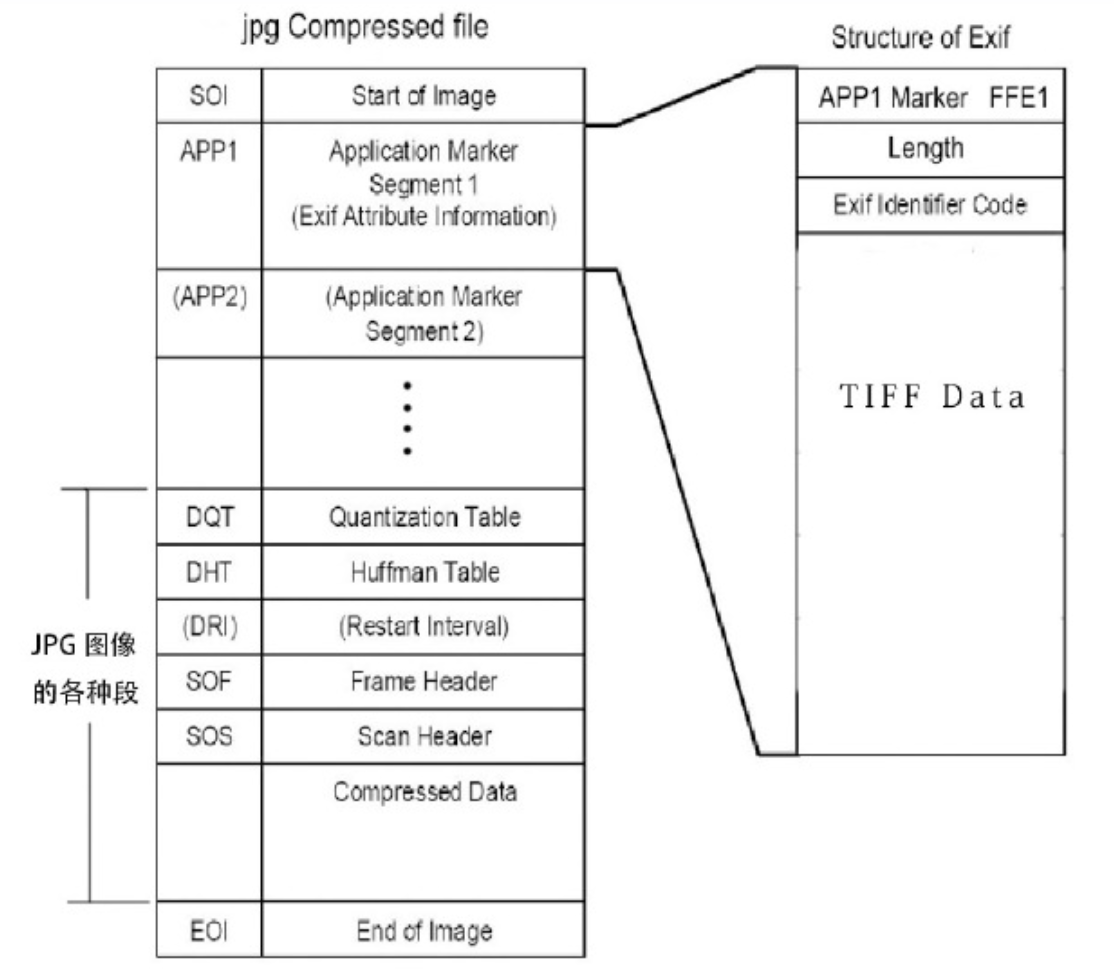

可以知道图片二进制格式中0xffxx一般是作为元标志使用,特别是
- 0xFFD8代表图片的开始,位于二进制格式的最前方
- 0xFFD9代表图片的结束,二进制的末尾必须有一个该标志
以该仓库下的照片作为样本exif-samples/jpg at master · ianare/exif-samples
STEP Ⅱ
代码部分h0mbre一开始采用的是较为方便调试与理解的python进行开发,并在后续改为c/c++等编译型语言以提升性能,这里就直接用cpp了
首先是最基础的io
从文件中读取二进制格式,使用一个vector来模拟可变字节流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| std::vector<char> GetData(std::string filename) {
std::ifstream file(filename, std::ios::binary | std::ios::ate);
if (!file) {
std::cerr << "Cannot open " << filename << std::endl;
return {};
}
std::streamsize size = file.tellg();
std::vector<char> bytes(size);
file.seekg(0);
file.read(bytes.data(), size);
file.close();
return bytes;
}
|
写出文件
1
2
3
4
5
6
7
8
9
10
| void BuildFile(const std::vector<char>& data) {
std::ofstream file("mutated.jpg", std::ios::binary | std::ios::trunc);
if (!file) {
std::cerr << "Cannot Create or Write to mutated.jpg" << std::endl;
}
else {
file.write(data.data(), data.size());
file.close();
}
}
|
测试一下
1
2
3
4
5
6
7
8
9
10
11
12
| int main(int argc, char* argv[]) {
if (argc < 2) {
std::cout << "Usage:baby_fuzzer [valid.jpg]" << std::endl;
return 1;
}
std::string filename = argv[1];
std::vector<char> origin_data = GetData(filename);
BuildFile(origin_data);
return 0;
}
|

STEP Ⅲ
接下来是变异功能,一种最简单的变异实现是位翻转
对于一个字节的数据,我们随机的对其一个bit位进行翻转,当然也可以翻转更多,甚至对每个字节的翻转位数也可以是随机的,不过暂时我们只翻转一个比特位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| class RandomGenerator {
public:
static void SetRange(unsigned int min, unsigned int max) {
dist = std::uniform_int_distribution<unsigned int>(min, max);
}
static unsigned int GetRandomNum() {
return dist(gen);
}
private:
RandomGenerator() = delete;
static std::random_device rd;
static std::mt19937 gen;
static std::uniform_int_distribution<unsigned int> dist;
};
std::random_device RandomGenerator::rd;
std::mt19937 RandomGenerator::gen(RandomGenerator::rd());
std::uniform_int_distribution<unsigned int> RandomGenerator::dist(0, 1);
void BitFlip(std::vector<char>& data) {
int num_to_flip = std::max(1, static_cast<int>((data.size() - 4) * 0.01));
std::vector<unsigned int> victim_indexs;
victim_indexs.reserve(num_to_flip);
RandomGenerator::SetRange(2, data.size() - 3);
for (int i = 0; i < num_to_flip; ++i) {
victim_indexs.emplace_back(RandomGenerator::GetRandomNum());
}
RandomGenerator::SetRange(0, 7);
for (auto& i : victim_indexs) {
int bit_index = RandomGenerator::GetRandomNum();
data[i] = data[i] ^ (1 << bit_index);
}
}
|
暂定修改1%的字节数
位翻转其实还是在一个较小的范围内变化,完全随机字节也许不错
STEP Ⅳ
我们已经完成了一个变异方法,现在我们需要测试他
首先是一个运行测试程序的接口,通过caveman后续系列的文章,我们可以知道fork出一个子进程并用execve函数启动目标程序,是优于使用popen函数的,因为popen会额外生成一个shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| void RunTest(int counter, const std::vector<char>& data) {
BuildFile("mutated.jpg", data);
pid_t pid = fork();
if (pid == -1) {
std::cerr << "fork failed" << std::endl;
return;
}
if (pid == 0) {
int fd = open("/dev/null", O_WRONLY);
dup2(fd, 1);
dup2(fd, 2);
close(fd);
char* const args[] = { "./exif", "mutated.jpg", "-v", nullptr };
if (execve(args[0], args, nullptr) == -1) {
std::cerr << "execve failed: " << errno << std::endl;
_exit(1);
}
}
else {
int status;
waitpid(pid, &status, 0);
if (WIFSIGNALED(status)) {
std::cout << "Process terminated with signal: " << WTERMSIG(status) << std::endl;
if (WTERMSIG(status) == SIGSEGV) {
std::cout << "Segmentation Fault detected!" << std::endl;
std::ostringstream oss;
oss << "crashes/crash_" << counter << ".jpg";
BuildFile(oss.str(), data);
}
}
}
}
|
相应地修改main
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| int main(int argc, char* argv[]) {
if (argc < 2) {
std::cout << "Usage:baby_fuzzer [valid.jpg]" << std::endl;
return 1;
}
CrashDirExists();
std::string filename = argv[1];
std::vector<char> origin_data = GetData(filename);
std::vector<char> mutated_data;
int counter = 0;
while (counter < 100) {
mutated_data = origin_data;
BitFlip(mutated_data);
RunTest(counter, mutated_data);
counter++;
}
return 0;
}
|
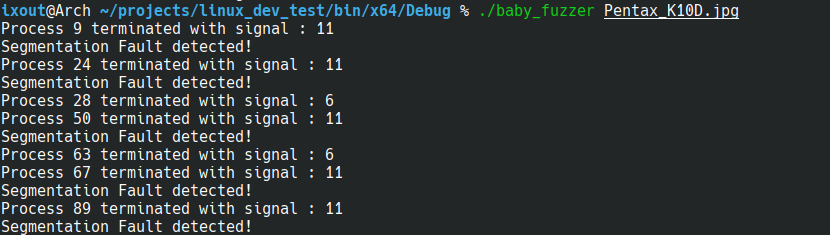
可以看到我们已经成功获得了crash,并且确实能够使得程序崩溃

在之后我们可以进一步分析它
STEP Ⅴ
现在继续增加另一种变异方法:特殊值注入
在计算机中存在这么一些值往往更容易触发意料之外的操作
例如
- 0xFF
- 0x7F
- 0x00
- 0xFFFF
- 0x0000
- 0xFFFFFFFF
- 0x00000000
- 0x80000000
- 0x40000000
- 0x7FFFFFFF
那么我们接下来就往数据中随机插入数个这样的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| std::pair<int, int> gMagicNums[] = {
{1, 0xff},
{1, 0x7f},
{1, 0},
{2, 0xffff},
{2, 0},
{4, 0},
{4, 0xffffffff},
{4, 0x80000000},
{4, 0x7fffffff},
{4, 0x40000000}
};
void MagicOverwrite(std::vector<char>& data) {
int num_to_over = std::max(1, static_cast<int>((data.size() - 4) * 0.001));
std::vector<unsigned int> victim_indexs;
victim_indexs.reserve(num_to_over);
RandomGenerator::SetRange(2, data.size() - 6);
for (int i = 0; i < num_to_over; ++i) {
victim_indexs.emplace_back(RandomGenerator::GetRandomNum());
}
RandomGenerator::SetRange(0, 9);
for (auto& i : victim_indexs) {
int magic_index = RandomGenerator::GetRandomNum();
memcpy(&data[i], &gMagicNums[magic_index].second, gMagicNums[magic_index].first);
}
}
|
运行测试,也成功得到了crash,但运行数次发现crash数量明显少于位翻转得到的

至此,一个简陋非常的fuzzer的基本结构就已经完成了
STEP Ⅵ
对结果可以进一步使用ASAN(AddressSanitizer)对crash进行分类处理
Learn Code Coverage
现在fuzzer基本都支持代码覆盖率,这是一个非常amazing的东西,接下来使用ptrace模拟代码覆盖率
仓库地址https://github.com/h0mbre/Fuzzing/blob/master/Caveman4/
STEP Ⅰ
先看一下我们的目标程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
| #include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
struct ORIGINAL_FILE {
char * data;
size_t length;
};
struct ORIGINAL_FILE get_bytes(char* fileName) {
FILE *filePtr;
char* buffer;
long fileLen;
filePtr = fopen(fileName, "rb");
if (!filePtr) {
printf("[>] Unable to open %s\n", fileName);
exit(-1);
}
if (fseek(filePtr, 0, SEEK_END)) {
printf("[>] fseek() failed, wtf?\n");
exit(-1);
}
fileLen = ftell(filePtr);
if (fileLen == -1) {
printf("[>] ftell() failed, wtf?\n");
exit(-1);
}
errno = 0;
rewind(filePtr);
if (errno) {
printf("[>] rewind() failed, wtf?\n");
exit(-1);
}
long trueSize = fileLen * sizeof(char);
printf("[>] %s is %ld bytes.\n", fileName, trueSize);
buffer = (char *)malloc(fileLen * sizeof(char));
fread(buffer, fileLen, 1, filePtr);
fclose(filePtr);
struct ORIGINAL_FILE original_file;
original_file.data = buffer;
original_file.length = trueSize;
return original_file;
}
void check_one(char* buffer, int check) {
if (buffer[check] == '\x6c') {
return;
}
else {
printf("[>] Check 1 failed.\n");
exit(-1);
}
}
void check_two(char* buffer, int check) {
if (buffer[check] == '\x57') {
return;
}
else {
printf("[>] Check 2 failed.\n");
exit(-1);
}
}
void check_three(char* buffer, int check) {
if (buffer[check] == '\x21') {
return;
}
else {
printf("[>] Check 3 failed.\n");
exit(-1);
}
}
void vuln(char* buffer, size_t length) {
printf("[>] Passed all checks!\n");
char vulnBuff[20];
memcpy(vulnBuff, buffer, length);
}
int main(int argc, char *argv[]) {
if (argc < 2 || argc > 2) {
printf("[>] Usage: vuln example.txt\n");
exit(-1);
}
char *filename = argv[1];
printf("[>] Analyzing file: %s.\n", filename);
struct ORIGINAL_FILE original_file = get_bytes(filename);
int checkNum1 = (int)(original_file.length * .33);
printf("[>] Check 1 no.: %d\n", checkNum1);
int checkNum2 = (int)(original_file.length * .5);
printf("[>] Check 2 no.: %d\n", checkNum2);
int checkNum3 = (int)(original_file.length * .67);
printf("[>] Check 3 no.: %d\n", checkNum3);
check_one(original_file.data, checkNum1);
check_two(original_file.data, checkNum2);
check_three(original_file.data, checkNum3);
vuln(original_file.data, original_file.length);
return 0;
}
|
目标程序有三个检查点,分别检查1/3,1/2,2/3处的字节是否通过检查,当全部通过时便会直接触发段错误
利用之前的fuzzer,每次选择%1的字节进行完全随机变异,选中1/3处字节进行变异且刚好变异为我们所需要的字节的概率是1/25600,三次检查点都成功命中的概率可见是很低的,估计所需次数达到了万亿级别
所以我们需要在通过第一个检查后,保存当前状态,以此为基础作为下一次变异的基础,这样概率就能从指数级降低改为线性降低
STEP Ⅱ
之前我们的fuzzer每一次启动都会使用大量的系统调用
其中fork()以及文件IO函数消耗极大却频繁出现,接下来我们考虑使用快照机制来减少这两种系统调用的出现,以提高性能,并实现我们的代码覆盖率
基本思路就是
- 在文件读取文件后内容后设置一个断点,将此时的寄存器以及所有可写内存保存一份
- 在另一块内存将jpg文件数据复制,并对其变异
- 将变异后的数据写入目标内存替换原始数据,开始运行
- 如果遇到exit那么就恢复寄存器以及所有可写内存,重新回到第二步
- 如果遇到断点,那么就将当前变异后数据作为新的变异源数据,并再次开始
Persistent Fuzz
通过劫持共享库使从文件或从网络中读取数据变为从内存中读取