void __init cred_init(void) { /* allocate a slab in which we can store credentials */ cred_jar = kmem_cache_create("cred_jar", sizeof(struct cred), 0, SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_ACCOUNT, NULL); }
/** * struct tty_struct - state associated with a tty while open * * @flow.lock: lock for flow members * @flow.stopped: tty stopped/started by tty_stop/tty_start * @flow.tco_stopped: tty stopped/started by TCOOFF/TCOON ioctls (it has * precedense over @flow.stopped) * @flow.unused: alignment for Alpha, so that no members other than @flow.* are * modified by the same 64b word store. The @flow's __aligned is * there for the very same reason. * @ctrl.lock: lock for ctrl members * @ctrl.pgrp: process group of this tty (setpgrp(2)) * @ctrl.session: session of this tty (setsid(2)). Writes are protected by both * @ctrl.lock and legacy mutex, readers must use at least one of * them. * @ctrl.pktstatus: packet mode status (bitwise OR of TIOCPKT_* constants) * @ctrl.packet: packet mode enabled * * All of the state associated with a tty while the tty is open. Persistent * storage for tty devices is referenced here as @port in struct tty_port. */ structtty_struct { int magic;//掩码0x5401 structkrefkref; structdevice *dev;/* class device or NULL (e.g. ptys, serdev) */ structtty_driver *driver; conststructtty_operations *ops; int index;
int closing; unsignedchar *write_buf; int write_cnt; /* If the tty has a pending do_SAK, queue it here - akpm */ structwork_structSAK_work; structtty_port *port; } __randomize_layout;
/* Each of a tty's open files has private_data pointing to tty_file_private */ structtty_file_private { structtty_struct *tty; structfile *file; structlist_headlist; };
/* * ldt_structs can be allocated, used, and freed, but they are never * modified while live. */ structldt_struct { /* * Xen requires page-aligned LDTs with special permissions. This is * needed to prevent us from installing evil descriptors such as * call gates. On native, we could merge the ldt_struct and LDT * allocations, but it's not worth trying to optimize. */ structdesc_struct *entries; unsignedint nr_entries;
/* * If PTI is in use, then the entries array is not mapped while we're * in user mode. The whole array will be aliased at the addressed * given by ldt_slot_va(slot). We use two slots so that we can allocate * and map, and enable a new LDT without invalidating the mapping * of an older, still-in-use LDT. * * slot will be -1 if this LDT doesn't have an alias mapping. */ int slot; };
SYSCALL_DEFINE3(modify_ldt, int , func , void __user * , ptr , unsignedlong , bytecount) { int ret = -ENOSYS;
switch (func) { case0: ret = read_ldt(ptr, bytecount); break; case1: ret = write_ldt(ptr, bytecount, 1); break; case2: ret = read_default_ldt(ptr, bytecount); break; case0x11: ret = write_ldt(ptr, bytecount, 0); break; } /* * The SYSCALL_DEFINE() macros give us an 'unsigned long' * return type, but tht ABI for sys_modify_ldt() expects * 'int'. This cast gives us an int-sized value in %rax * for the return code. The 'unsigned' is necessary so * the compiler does not try to sign-extend the negative * return codes into the high half of the register when * taking the value from int->long. */ return (unsignedint)ret; }
/* * Called on fork from arch_dup_mmap(). Just copy the current LDT state, * the new task is not running, so nothing can be installed. */ intldt_dup_context(struct mm_struct *old_mm, struct mm_struct *mm) { //...
/* * If we are using PTI, map the new LDT into the userspace pagetables. * If there is already an LDT, use the other slot so that other CPUs * will continue to use the old LDT until install_ldt() switches * them over to the new LDT. */ error = map_ldt_struct(mm, new_ldt, old_ldt ? !old_ldt->slot : 0); if (error) { /* * This only can fail for the first LDT setup. If an LDT is * already installed then the PTE page is already * populated. Mop up a half populated page table. */ if (!WARN_ON_ONCE(old_ldt)) free_ldt_pgtables(mm); free_ldt_struct(new_ldt); goto out_unlock; }
/* * Note on 64bit base and limit is ignored and you cannot set DS/ES/CS * not to the default values if you still want to do syscalls. This * call is more for 32bit mode therefore. */ structuser_desc { unsignedint entry_number; unsignedint base_addr; unsignedint limit; unsignedint seg_32bit:1; unsignedint contents:2; unsignedint read_exec_only:1; unsignedint limit_in_pages:1; unsignedint seg_not_present:1; unsignedint useable:1; #ifdef __x86_64__ /* * Because this bit is not present in 32-bit user code, user * programs can pass uninitialized values here. Therefore, in * any context in which a user_desc comes from a 32-bit program, * the kernel must act as though lm == 0, regardless of the * actual value. */ unsignedint lm:1; #endif };
setxattr
申请obj大小:任意
GFP_KERNEL_ACCOUNT:否
功能:堆占位
观察 setxattr 源码,发现如下调用链:
1 2 3
SYS_setxattr() path_setxattr() setxattr()
在 setxattr() 函数中有如下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
staticlong setxattr(struct dentry *d, constchar __user *name, constvoid __user *value, size_t size, int flags) { //... kvalue = kvmalloc(size, GFP_KERNEL); if (!kvalue) return -ENOMEM; if (copy_from_user(kvalue, value, size)) {
//,..
kvfree(kvalue);
return error; }
这里的 value 和 size 都是由我们来指定的,即我们可以分配任意大小的 object 并向其中写入内容,之后该对象会被释放掉
/* * shm_file_operations_huge is now identical to shm_file_operations, * but we keep it distinct for the sake of is_file_shm_hugepages(). */ staticconststructfile_operationsshm_file_operations_huge = { .mmap = shm_mmap, .fsync = shm_fsync, .release = shm_release, .get_unmapped_area = shm_get_unmapped_area, .llseek = noop_llseek, .fallocate = shm_fallocate, };
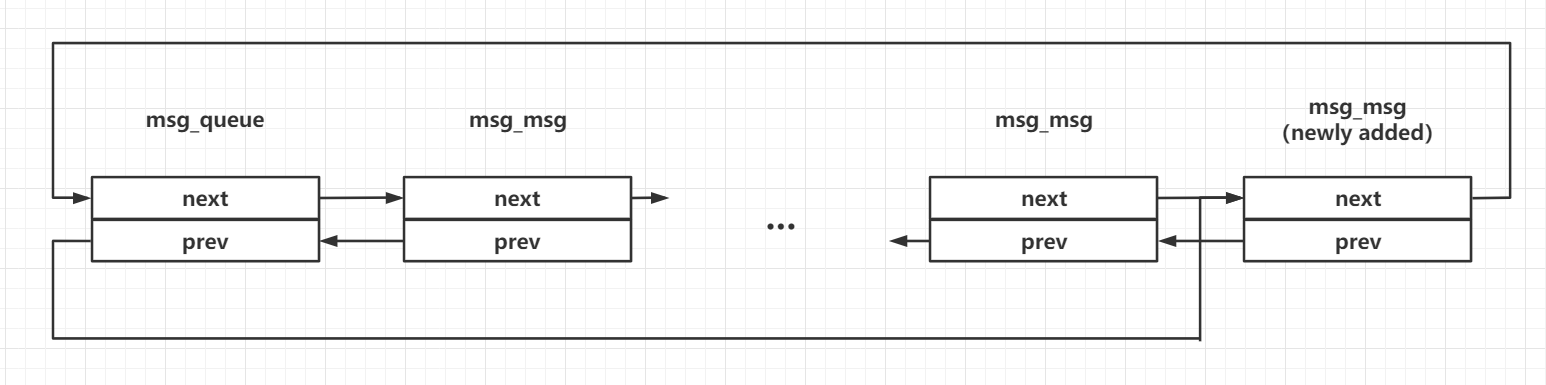
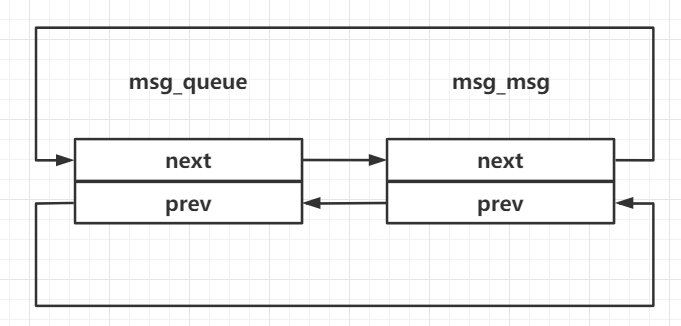
/* one msq_queue structure for each present queue on the system */ structmsg_queue { structkern_ipc_permq_perm; time64_t q_stime; /* last msgsnd time */ time64_t q_rtime; /* last msgrcv time */ time64_t q_ctime; /* last change time */ unsignedlong q_cbytes; /* current number of bytes on queue */ unsignedlong q_qnum; /* number of messages in queue */ unsignedlong q_qbytes; /* max number of bytes on queue */ structpid *q_lspid;/* pid of last msgsnd */ structpid *q_lrpid;/* last receive pid */
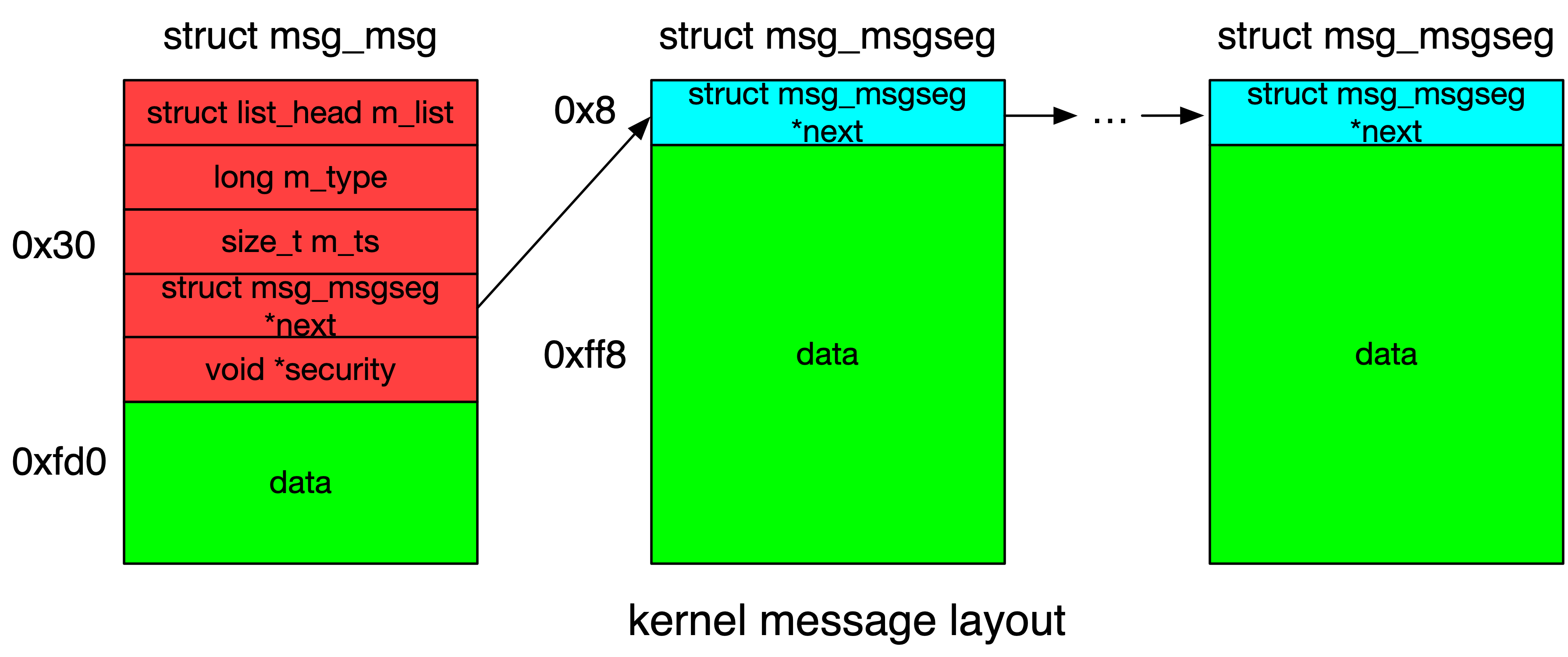
/* one msg_msg structure for each message */ structmsg_msg { structlist_headm_list; long m_type; size_t m_ts; /* message text size */ structmsg_msgseg *next; void *security; /* the actual message follows immediately */ };
/** * struct pipe_inode_info - a linux kernel pipe * @mutex: mutex protecting the whole thing * @rd_wait: reader wait point in case of empty pipe * @wr_wait: writer wait point in case of full pipe * @head: The point of buffer production * @tail: The point of buffer consumption * @note_loss: The next read() should insert a data-lost message * @max_usage: The maximum number of slots that may be used in the ring * @ring_size: total number of buffers (should be a power of 2) * @nr_accounted: The amount this pipe accounts for in user->pipe_bufs * @tmp_page: cached released page * @readers: number of current readers of this pipe * @writers: number of current writers of this pipe * @files: number of struct file referring this pipe (protected by ->i_lock) * @r_counter: reader counter * @w_counter: writer counter * @fasync_readers: reader side fasync * @fasync_writers: writer side fasync * @bufs: the circular array of pipe buffers * @user: the user who created this pipe * @watch_queue: If this pipe is a watch_queue, this is the stuff for that **/ structpipe_inode_info { structmutexmutex; wait_queue_head_t rd_wait, wr_wait; unsignedint head; unsignedint tail; unsignedint max_usage; unsignedint ring_size; #ifdef CONFIG_WATCH_QUEUE bool note_loss; #endif unsignedint nr_accounted; unsignedint readers; unsignedint writers; unsignedint files; unsignedint r_counter; unsignedint w_counter; structpage *tmp_page; structfasync_struct *fasync_readers; structfasync_struct *fasync_writers; structpipe_buffer *bufs; structuser_struct *user; #ifdef CONFIG_WATCH_QUEUE structwatch_queue *watch_queue; #endif };
/** * struct pipe_buffer - a linux kernel pipe buffer * @page: the page containing the data for the pipe buffer * @offset: offset of data inside the @page * @len: length of data inside the @page * @ops: operations associated with this buffer. See @pipe_buf_operations. * @flags: pipe buffer flags. See above. * @private: private data owned by the ops. **/ structpipe_buffer { structpage *page; unsignedint offset, len; conststructpipe_buf_operations *ops; unsignedint flags; unsignedlong private; };
/* * If trying to increase the pipe capacity, check that an * unprivileged user is not trying to exceed various limits * (soft limit check here, hard limit check just below). * Decreasing the pipe capacity is always permitted, even * if the user is currently over a limit. */ if (nr_pages > pipe->buffers && size > pipe_max_size && !capable(CAP_SYS_RESOURCE)) return -EPERM;
if (nr_pages > pipe->buffers && (too_many_pipe_buffers_hard(user_bufs) || too_many_pipe_buffers_soft(user_bufs)) && is_unprivileged_user()) { ret = -EPERM; goto out_revert_acct; }
/* * We can shrink the pipe, if arg >= pipe->nrbufs. Since we don't * expect a lot of shrink+grow operations, just free and allocate * again like we would do for growing. If the pipe currently * contains more buffers than arg, then return busy. */ if (nr_pages < pipe->nrbufs) { ret = -EBUSY; goto out_revert_acct; }
bufs = kcalloc(nr_pages, sizeof(*bufs), GFP_KERNEL_ACCOUNT | __GFP_NOWARN); if (unlikely(!bufs)) { ret = -ENOMEM; goto out_revert_acct; }
/* * The pipe array wraps around, so just start the new one at zero * and adjust the indexes. */ if (pipe->nrbufs) { unsignedint tail; unsignedint head;
structpipe_buf_operations { /* * ->confirm() verifies that the data in the pipe buffer is there * and that the contents are good. If the pages in the pipe belong * to a file system, we may need to wait for IO completion in this * hook. Returns 0 for good, or a negative error value in case of * error. If not present all pages are considered good. */ int (*confirm)(struct pipe_inode_info *, struct pipe_buffer *);
/* * When the contents of this pipe buffer has been completely * consumed by a reader, ->release() is called. */ void (*release)(struct pipe_inode_info *, struct pipe_buffer *);
/* * Attempt to take ownership of the pipe buffer and its contents. * ->try_steal() returns %true for success, in which case the contents * of the pipe (the buf->page) is locked and now completely owned by the * caller. The page may then be transferred to a different mapping, the * most often used case is insertion into different file address space * cache. */ bool (*try_steal)(struct pipe_inode_info *, struct pipe_buffer *);
/* * Get a reference to the pipe buffer. */ bool (*get)(struct pipe_inode_info *, struct pipe_buffer *); };
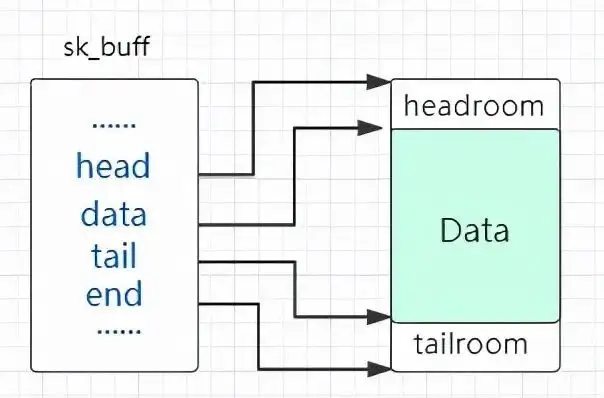
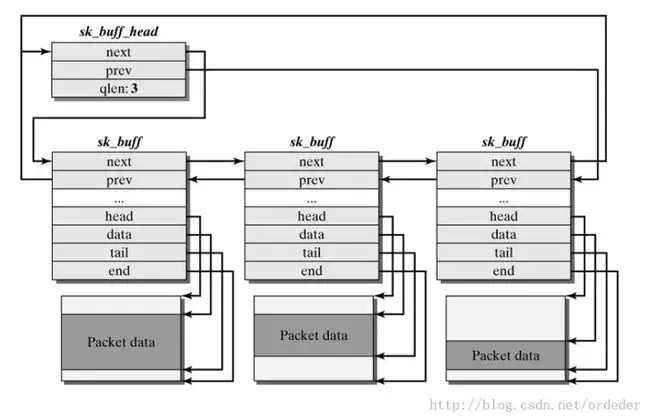
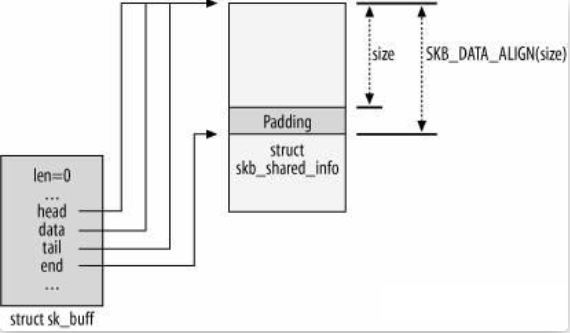
structsk_buff { union { struct { /* These two members must be first. */ structsk_buff *next; structsk_buff *prev;
// ... };
// ...
/* These elements must be at the end, see alloc_skb() for details. */ sk_buff_data_t tail; sk_buff_data_t end; unsignedchar *head, *data; unsignedint truesize; refcount_t users;
#ifdef CONFIG_SKB_EXTENSIONS /* only useable after checking ->active_extensions != 0 */ structskb_ext *extensions; #endif };
sk_buff 结构体与其所表示的数据包形成如下结构,其中:
head :一个数据包实际的起始处(也就是为该数据包分配的 object 的首地址)
end :一个数据包实际的末尾(为该数据包分配的 object 的末尾地址)
data :当前所在 layer 的数据包对应的起始地址
tail :当前所在 layer 的数据包对应的末尾地址
data 和 tail 可以这么理解:数据包每经过网络层次模型中的一层都会被添加/删除一个 header (有时还有一个 tail),data 与 tail 便是用以对此进行标识的
structuser_key_payload { structrcu_headrcu;/* RCU destructor */ unsignedshort datalen; /* length of this data */ char data[] __aligned(__alignof__(u64)); /* actual data */ };
mv bin evil_bin /evil_bin/mkdir bin echo"#!/evil_bin/sh" > /bin/power echo"/evil_bin/sh" >> /bin/power exit
密码设置
如果root账号的密码没有设置的话,直接su即可登录到root,非预期的。
又或者是默认的密码#,当然其实很多内核并没有提供su
例如linectf2022-encrypt
1 2 3 4 5 6 7 8 9 10 11 12 13
First, connect via netcat. We got a shell, let's look around: / $ ls => We see the flag file. / $ cat flag => Not enough permissions. Are there many other users? / $ cat /etc/passwd => Only root seems to be available. Let's try switching to it: / $ su / # => See the #? This worked! We got root! / # cat flag
suid
带有suid的可执行文件允许我们拥有文件所有者的权限
还是lincectf2022的encrypt
find / -perm -u=s -type f 2>/dev/null
打印的字符串告诉我们busybox具有这个权限位
Run busybox and it will show us all the configurations which are avialable
/* * Unprivileged users may change the real uid to the effective uid * or vice versa. (BSD-style) * * If you set the real uid at all, or set the effective uid to a value not * equal to the real uid, then the saved uid is set to the new effective uid. * * This makes it possible for a setuid program to completely drop its * privileges, which is often a useful assertion to make when you are doing * a security audit over a program. * * The general idea is that a program which uses just setreuid() will be * 100% compatible with BSD. A program which uses just setuid() will be * 100% compatible with POSIX with saved IDs. */ long __sys_setreuid(uid_t ruid, uid_t euid) { structuser_namespace *ns = current_user_ns(); conststructcred *old; structcred *new; int retval; kuid_t kruid, keuid;
This file implements KASLR memory randomization for x86_64. It randomizes the virtual address space of kernel memory regions (physical memory mapping, vmalloc & vmemmap) for x86_64. This security feature mitigates exploits relying on predictable kernel addresses.