
some_rop
ret2dl
一些前置知识见elf动态链接.md
ret2dlresolve的情况更多适用于没有打印函数的程序
毕竟如果有打印函数,且有完成ret2dl的条件,那不如直接用ret2libc等方法
链接过程
_dl_runtime_resolve(link_map,reloc_arg)
- 用
link_map访问.dynamic,取出.dynstr,.dynsym,.rel.plt的指针 .rel.plt + 第二个参数求出当前函数的重定位表项Elf_Rel的指针,记作relrel->r_info >> 8作为.dynsym的下标,求出当前函数的符号表项Elf_Sym的指针,记作sym.dynstr + sym->st_name得出符号名字符串指针- 在动态链接库查找这个函数的地址,并且把地址赋值给
*rel->r_offset,即GOT表 - 调用这个函数
但_dl_runtime_resolve的主体其实是调用_dl_fixup
_dl_fixup是在glibc/elf/dl-runtime.c实现的
利用思路
思路 1 - 直接控制重定位表项的相关内容
由于动态链接器最后在解析符号的地址时,是依据符号的名字进行解析的。因此,一个很自然的想法是直接修改动态字符串表 .dynstr,比如把某个函数在字符串表中对应的字符串修改为目标函数对应的字符串。但是,动态字符串表和代码映射在一起,是只读的。
此外,类似地,我们可以发现动态符号表、重定位表项都是只读的。
但是,假如我们可以控制程序执行流,那我们就可以伪造合适的重定位偏移,从而达到调用目标函数的目的。然而,这种方法比较麻烦,因为我们不仅需要伪造重定位表项,符号信息和字符串信息,而且我们还需要确保动态链接器在解析的过程中不会出错。
即伪造一个全新的表项,截取调用resolve来触发
思路 2 - 间接控制重定位表项的相关内容
既然动态链接器会从 .dynamic 节中索引到各个目标节,那如果我们可以修改动态节中的内容,那自然就很容易控制待解析符号对应的字符串,从而达到执行目标函数的目的。
即修改.dynamic的内容间接控制重定位表项
思路 3 - 伪造 link_map
由于动态连接器在解析符号地址时,主要依赖于 link_map 来查询相关的地址。因此,如果我们可以成功伪造 link_map,也就可以控制程序执行目标函数。
即修改GOT[1]伪造整个link_map(较难实现),又或者伪造link_map的部分l_info指针使其索引至伪造区域
64与32的一些差异
首先二者的
Elf_Rela和Elf_Dyn结构体存在一些差异1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1700000000 Elf32_Sym struc ; (sizeof=0x10, align=0x4, mappedto_1)
00000000 st_name dd ? ; offset (0804824C)
00000004 st_value dd ? ; offset (00000000)
00000008 st_size dd ?
0000000C st_info db ?
0000000D st_other db ?
0000000E st_shndx dw ?
00000010 Elf32_Sym ends
00000000 Elf64_Sym struc ; (sizeof=0x18, align=0x8, mappedto_1)
00000000 st_name dd ? ; offset (00400378)
00000004 st_info db ?
00000005 st_other db ?
00000006 st_shndx dw ?
00000008 st_value dq ? ; offset (00000000)
00000010 st_size dq ?
00000018 Elf64_Sym ends1
2
3
4
5
6
7
8
9
1000000000 Elf32_Rel struc ; (sizeof=0x8, align=0x4, copyof_2)
00000000 r_offset dd ?
00000004 r_info dd ?
00000008 Elf32_Rel ends
00000000 Elf64_Rela struc ; (sizeof=0x18, align=0x8, copyof_2)
00000000 r_offset dq ?
00000008 r_info dq ?
00000010 r_addend dq ?
00000018 Elf64_Rela ends_dl_runtime_resolve的第二个参数,在32位中是该函数表项相对.rel.plt的字节偏移,而在64位中是该函数表项相对.rel.plt的下标索引
- 64位下还会验证DT_VERSYM,使用符号表索引作为版本号索引寻找版本号,需要将其置零以绕过检查
- 64位下dl_resolve的参数依然使用栈传递,dl_fixup则寄存器传递
例题
xdctf2015-pwn200
1 |
|
wiki将其按照relro等级编译讲解
no relro
在这种情况下,修改 .dynamic 会简单些。因为只需要修改 .dynamic 节中的字符串表的地址为伪造的字符串表的地址,并且相应的位置为目标字符串基本就行了。具体思路如下
- 修改 .dynamic 节中字符串表的地址为伪造的地址
- 在伪造的地址处构造好字符串表,将 read 字符串替换为 system 字符串。
- 在特定的位置读取 /bin/sh 字符串。
- 调用 read 函数的 plt 的第二条指令,触发
_dl_runtime_resolve进行函数解析,从而执行 system 函数。从这里也可以看出,只要能控制返回流,就算函数已经被解析也可以使用来ret2dl
exp:
1 | from pwn import * |
partial relro
在这种情况下,ELF 文件中的 .dynamic 节将会变成只读的,这时可以通过伪造重定位表项的方式来调用目标函数。
即在指定地址处依次伪造好某一个函数动态链接对应的rel,sym,str
并以此得到一个rel的下标
然后直接返回到plt公共表项,那么dl的第二个参数就可以由我们直接在栈中布置
1 | #coding:utf-8 |
ezzzz
题目很明显只有栈溢出漏洞,没有泄露函数,没有canary、pie,考虑使用ret2resolve,是经典的利用手法。
题目编译使用的较老的GCC-5.4.0编译的,使得dynamic段的RELA和JMPREL合并成一个段,但是dl_fixup函数中会用到JMPREL,所以需要额外的恢复DT_JMPREL的值。之后就是用题目给的gadget完成利用。
gadgets
题目给了两个gadget:
gadget1:
1 | __int64 __fastcall sub_400606(int a1, int a2, int a3) |
其可以不断深入解引用指针,并可以将解引用出的内容写到指定内存中
在该题我们可以利用DT_debug表项,找到_r_debug全局结构体,再由_r_debug结构体找到elf的link_map,再由elf的link_map用两次l_next找到libc的link_map,再由link_map的l_info[DT_PLTGOT]表项找到libc的.got.plt,然后最后可以在libc的.got.plt公共表项中找到resolve的地址
gadget2:
1 | __int64 __fastcall sub_40067C(int a1, int a2, int a3) |
该gadget可以修改内存上的一个指针指向的区域的内容
我们可以利用其修改在上一个gadget中被我们写入内存的link_map
以恢复link_map的DT_JMPREL以及置零DT_Versym
利用流程
- 将magicnumber覆盖成0xbeefdead,实现初始化sea.head为dt_debug。将栈迁移到bss
- 通过gadget1获取linkmap和resolver地址,并将其写到任意地址。
- 通过gadget2修改linkmap的内容,bypass versym和JMPRel。
- 伪造dynrela、dynsym、dynstr
- 劫持执行流到resolver,调用resolver获取shell。
exp:
1 | # -*- coding: UTF-8 -*- |
总结
在partial|full relro时,更多时候目标就是依次伪造reloc表项,dynsym表项,dynstr表项,布置好参数,然后截取调用dlresolve(e.g.plt公共表项,ret直接调用等)
no relro时则方法要更多,但一般采用最方便的修改.dynamic中的索引指针
SROP
基础
sigreturn是一个系统调用,在类 unix 系统发生 signal 的时候会被间接地调用。
signal 机制是类 unix 系统中进程之间相互传递信息的一种方法。一般,我们也称其为软中断信号,或者软中断。比如说,进程之间可以通过系统调用 kill 来发送软中断信号。一般来说,信号机制常见的步骤如下图所示:
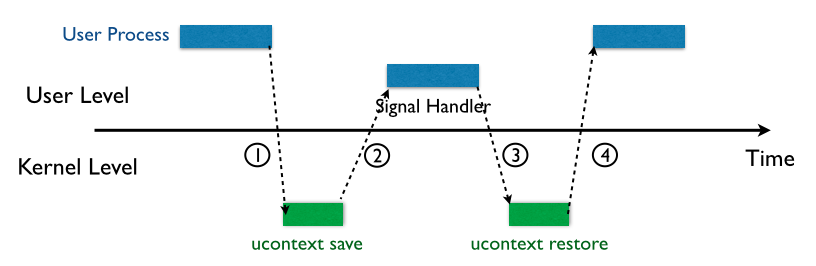
内核向某个进程发送 signal 机制,该进程会被暂时挂起,进入内核态。
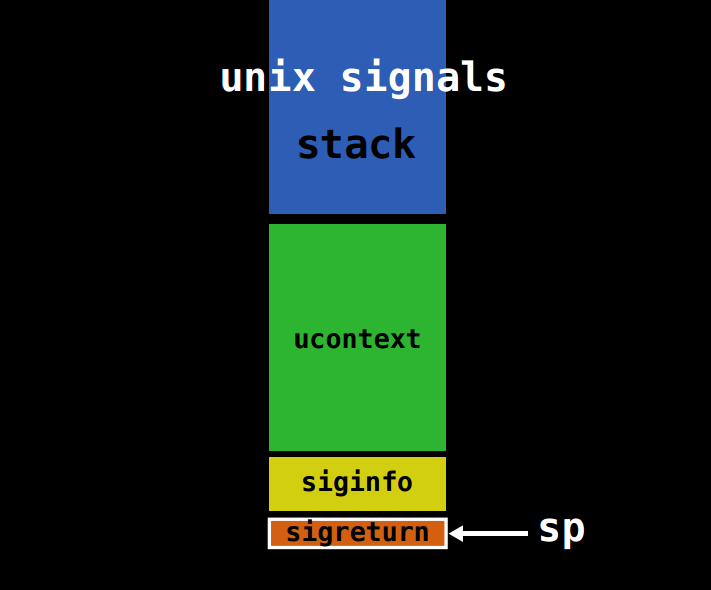
内核会为该进程保存相应的上下文,主要是将所有寄存器压入栈中,以及压入 signal 信息,以及指向 sigreturn 的系统调用地址。此时栈的结构如下图所示,我们称 ucontext 以及 siginfo 这一段为 Signal Frame。需要注意的是,这一部分是在用户进程的地址空间的。之后会跳转到注册过的 signal handler 中处理相应的 signal。因此,当 signal handler 执行完之后,就会执行 sigreturn 代码。

从图中可以看出,执行完sigreturn,当前rsp指向的就是sigframe
对于 signal Frame 来说,会因为架构的不同而有所区别,这里给出分别给出 x86 以及 x64 的 sigcontext
- x86
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25struct sigcontext
{
unsigned short gs, __gsh;
unsigned short fs, __fsh;
unsigned short es, __esh;
unsigned short ds, __dsh;
unsigned long edi;
unsigned long esi;
unsigned long ebp;
unsigned long esp;
unsigned long ebx;
unsigned long edx;
unsigned long ecx;
unsigned long eax;
unsigned long trapno;
unsigned long err;
unsigned long eip;
unsigned short cs, __csh;
unsigned long eflags;
unsigned long esp_at_signal;
unsigned short ss, __ssh;
struct _fpstate * fpstate;
unsigned long oldmask;
unsigned long cr2;
};- x64
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51struct _fpstate
{
/* FPU environment matching the 64-bit FXSAVE layout. */
__uint16_t cwd;
__uint16_t swd;
__uint16_t ftw;
__uint16_t fop;
__uint64_t rip;
__uint64_t rdp;
__uint32_t mxcsr;
__uint32_t mxcr_mask;
struct _fpxreg _st[8];
struct _xmmreg _xmm[16];
__uint32_t padding[24];
};
struct sigcontext
{
__uint64_t r8;
__uint64_t r9;
__uint64_t r10;
__uint64_t r11;
__uint64_t r12;
__uint64_t r13;
__uint64_t r14;
__uint64_t r15;
__uint64_t rdi;
__uint64_t rsi;
__uint64_t rbp;
__uint64_t rbx;
__uint64_t rdx;
__uint64_t rax;
__uint64_t rcx;
__uint64_t rsp;
__uint64_t rip;
__uint64_t eflags;
unsigned short cs;
unsigned short gs;
unsigned short fs;
unsigned short __pad0;
__uint64_t err;
__uint64_t trapno;
__uint64_t oldmask;
__uint64_t cr2;
__extension__ union
{
struct _fpstate * fpstate;
__uint64_t __fpstate_word;
};
__uint64_t __reserved1 [8];
};signal handler 返回后,内核为执行 sigreturn 系统调用,为该进程恢复之前保存的上下文,其中包括将所有压入的寄存器,重新 pop 回对应的寄存器,最后恢复进程的执行。其中,32 位的 sigreturn 的调用号为 119(0x77),64 位的系统调用号为 15(0xf)。
利用原理
仔细回顾一下内核在 signal 信号处理的过程中的工作,我们可以发现,内核主要做的工作就是为进程保存上下文,并且恢复上下文。这个主要的变动都在 Signal Frame 中。但是需要注意的是:
- Signal Frame 被保存在用户的地址空间中,所以用户是可以读写的。
- 由于内核与信号处理程序无关 (kernel agnostic about signal handlers),它并不会去记录这个 signal 对应的 Signal Frame,所以当执行 sigreturn 系统调用时,此时的 Signal Frame 并不一定是之前内核为用户进程保存的 Signal Frame。
说到这里,其实,SROP 的基本利用原理也就出现了。下面举两个简单的例子。
获取 shell
首先,假设攻击者可以控制用户进程的栈,那么它就可以伪造一个 Signal Frame,如下图所示,这里以 64 位为例子,给出 Signal Frame 更加详细的信息

当系统执行完 sigreturn 系统调用之后,会执行一系列的 pop 指令以便于恢复相应寄存器的值,当执行到 rip 时,就会将程序执行流指向 syscall 地址,根据相应寄存器的值,此时,便会得到一个 shell
system call chains
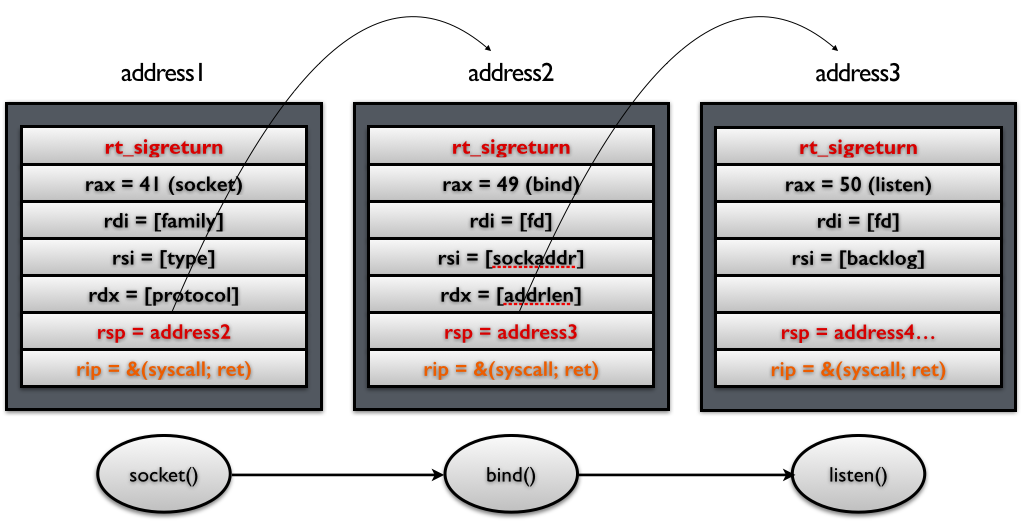
需要指出的是,上面的例子中,我们只是单独的获得一个 shell。有时候,我们可能会希望执行一系列的函数。只需要做两处修改即可
- 控制栈指针。
- 把原来 rip 指向的
syscallgadget 换成syscall; retgadget。
如下图所示 ,这样当每次 syscall 返回的时候,栈指针都会指向下一个 Signal Frame。因此就可以执行一系列的 sigreturn 函数调用。
后续
需要注意的是,我们在构造 ROP 攻击的时候,需要满足下面的条件
- 可以通过栈溢出来控制栈的内容
- 需要知道相应的地址
- “/bin/sh”
- Signal Frame
- syscall
- sigreturn
- 需要有够大的空间来塞下整个 sigal frame
此外,关于 sigreturn 以及 syscall;ret 这两个 gadget 在上面并没有提及。提出该攻击的论文作者发现了这些 gadgets 出现的某些地址:

并且有些系统上 SROP 的地址被随机化了,而有些则没有。比如说Linux < 3.3 x86_64(在 Debian 7.0, Ubuntu Long Term Support, CentOS 6 系统中默认内核),可以直接在 vsyscall 中的固定地址处找到 syscall&return 代码片段。如下
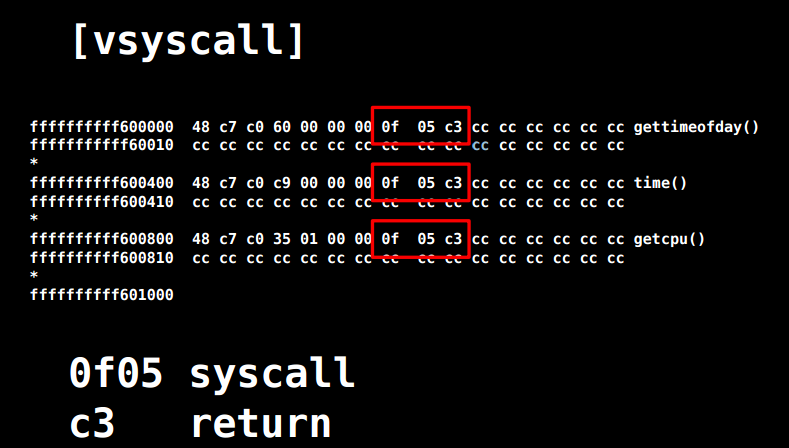
但是目前它已经被vsyscall-emulate和vdso机制代替了。此外,目前大多数系统都会开启 ASLR 保护,所以相对来说这些 gadgets 都并不容易找到。
值得一说的是,对于 sigreturn 系统调用来说,在 64 位系统中,sigreturn 系统调用对应的系统调用号为 15,只需要 RAX=15,并且执行 syscall 即可实现调用 syscall 调用。而 RAX 寄存器的值又可以通过控制某个函数的返回值来间接控制,比如说 read 函数的返回值为读取的字节数。
stack smash
原理
在程序加了 canary 保护之后,如果我们读取的 buffer 覆盖了对应的值时,程序就会报错,一般来说并不会关心报错信息。
而 stack smash 技巧则就是利用打印这一信息的程序来得到我们想要的内容。这是因为在程序启动 canary 保护之后,如果发现 canary 被修改的话,程序就会执行 __stack_chk_fail 函数来打印 argv[0] 指针所指向的字符串
argv[0]即函数名指针,正常情况下,这个指针指向了程序名。其代码如下
1 | void __attribute__ ((noreturn)) __stack_chk_fail (void) |
所以说如果我们利用栈溢出覆盖 argv[0] 为我们想要输出的字符串的地址,那么在 __fortify_fail 函数中就会输出我们想要的信息。
批注: 这个方法在 glibc-2.31 之后不可用了, 具体看这个部分代码 fortify_fail.c 。
1 | #include <stdio.h> |
总结一下原因就是现在不会打印 argv[0] 指针所指向的字符串
例题
32C3 CTF readme
ida
1 | unsigned __int64 sub_4007E0() |
显然_IO_gets(v3)存在溢出
观察可以得到0x600D20处就是存放flag的地址,但是可以看出无论我们读不读这个地址都会被覆盖
不过这里有一个知识点:
在 ELF 内存映射时,bss 段会被映射两次,所以可以使用另一处的地址来进行输出,可以使用 gdb 的search来进行查找。
1 | pwndbg> search 'Server' |
exp:
1 | from pwn import * |