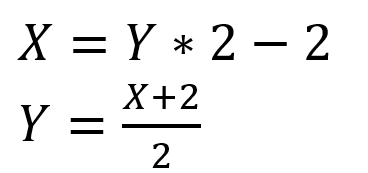前言 堆的学习可以说是一道坎了,要掌握的话对源码阅读及理解的能力要求挺高,初学时往往被搞得晕头转向,这里就记录一下我的学习记录,基础的东西到处都有就不记了,主要还是记一些我认为比较重要或者容易被忽略的细节。
学习记录 基础 基础的东西网上能搜到的教程(像ctfwiki,狼组安全,ctf-all-in-one等)讲的已经很细了,认真看一定能有一个基础的知识框架.不过还是推荐看一看华庭大佬的glibc内存管理-ptmalloc2源码分析 (很细很全很直白),看了之后真的能有很多收获.
理清从属关系 初学时,heap,arena,chunk这些东西很容易把人搞糊涂,这里简单梳理一下
系统中整个堆功能的实现区域都可以被叫做堆(heap),但其实但heap还有一个相对这个整个堆区域要更小的概念,如下:
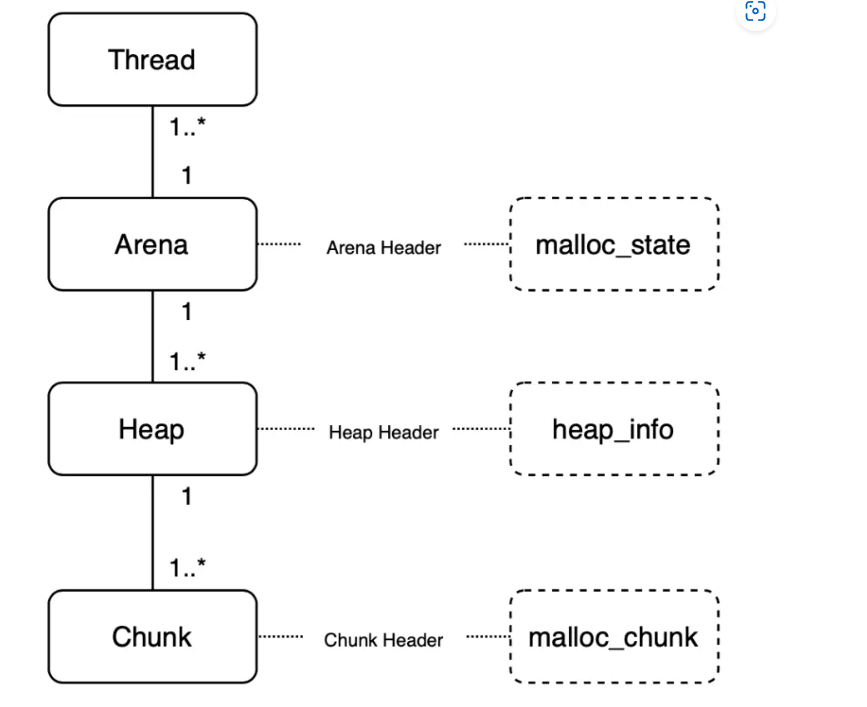
glibc的malloc源码中涉及三种最重要数据结构:Arena、Heap、Chunk ,分别对应结构体malloc_state、heap_info、malloc_chunk 。 每个数据结构都有对应的结构体实现,如图:
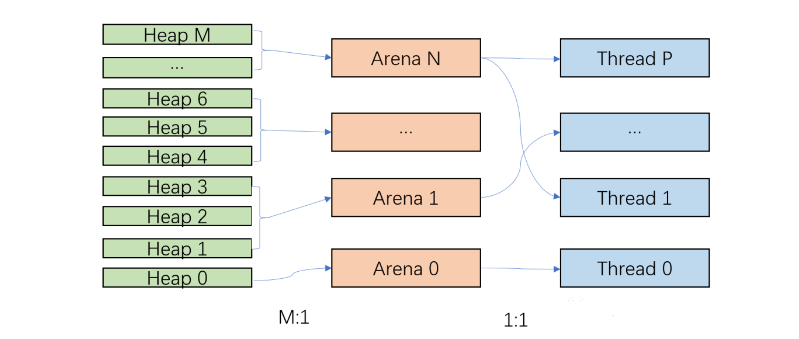
Thread - Arena : 一个Arena对应多个线程Thread。即每个线程都有一个Arena,但是有可能多个线程共用一个Arena(同一时间只能一对一)。每个Arena都包含一个malloc_state结构体,保存bins, top chunk, Last reminder chunk等信息。Arena - Heap :一个Arena可能拥有多个heap。Arena开始的时候只有一个heap,但是当这个heap的空间用尽时,就需要获取新的heap。(也可以理解为subheap子堆)Heap - Chunk :一个Heap根据用户的请求会划分为多个chunk,每个chunk拥有自己的header - malloc_chunk。
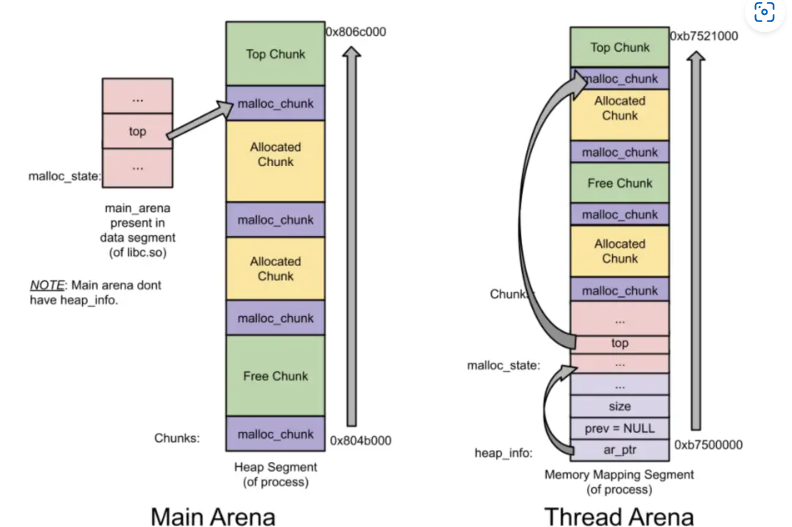
需要注意的是,Main Arena只有一个heap,因此没有heap_info结构 。当main arena用尽空间后,会扩展当前的heap空间。此外,Main Arean的Arena header并不是heap segment的一部分,而作为全局变量储存在libc.so的数据段中。
下图是只有一个heap时,主线程和线程的堆结构示意图,左图是Main Arena,右图是Threa Arena。堆是从低地址向高地址增长的,可以看到每一个malloc_chunk上面都跟着一个chunk。同时Main Arena没有heap_info和malloc_state的结构。
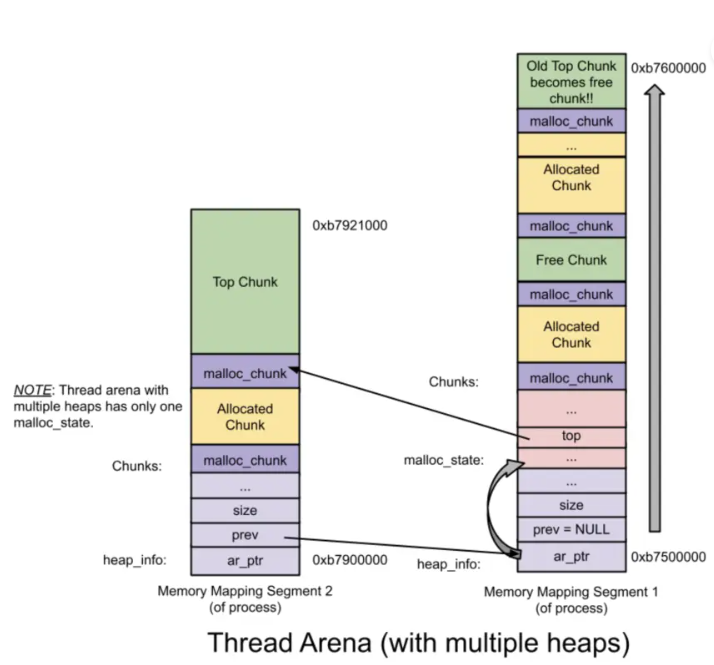
下图是存在多个heap的thread Arena的情况。可以看到每一个heap都一个heap header(heap_info),但是只有最初的heap拥有arena header(malloc_state).
当线程申请内存时,就创建一个Arena。主线程有自己独立的Arena,叫做main arena,但不是每一个线程都有独立的Arena。
Arena的个数取决于cpu核的个数
三个重要结构体的定义 malloc_state 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 struct malloc_state { __libc_lock_define (, mutex); int flags; int have_fastchunks; mfastbinptr fastbinsY[NFASTBINS]; mchunkptr top; mchunkptr last_remainder; mchunkptr bins[NBINS * 2 - 2 ]; unsigned int binmap[BINMAPSIZE]; struct malloc_state *next ; struct malloc_state *next_free ; INTERNAL_SIZE_T attached_threads; INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
malloc_chunk 1 2 3 4 5 6 7 8 9 10 11 12 13 struct malloc_chunk { INTERNAL_SIZE_T mchunk_prev_size; INTERNAL_SIZE_T mchunk_size; struct malloc_chunk * fd ; struct malloc_chunk * bk ; struct malloc_chunk * fd_nextsize ; struct malloc_chunk * bk_nextsize ; };
heap_info 1 2 3 4 5 6 7 8 9 10 11 12 typedef struct _heap_info { mstate ar_ptr; struct _heap_info *prev ; size_t size; size_t mprotect_size; char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; } heap_info;
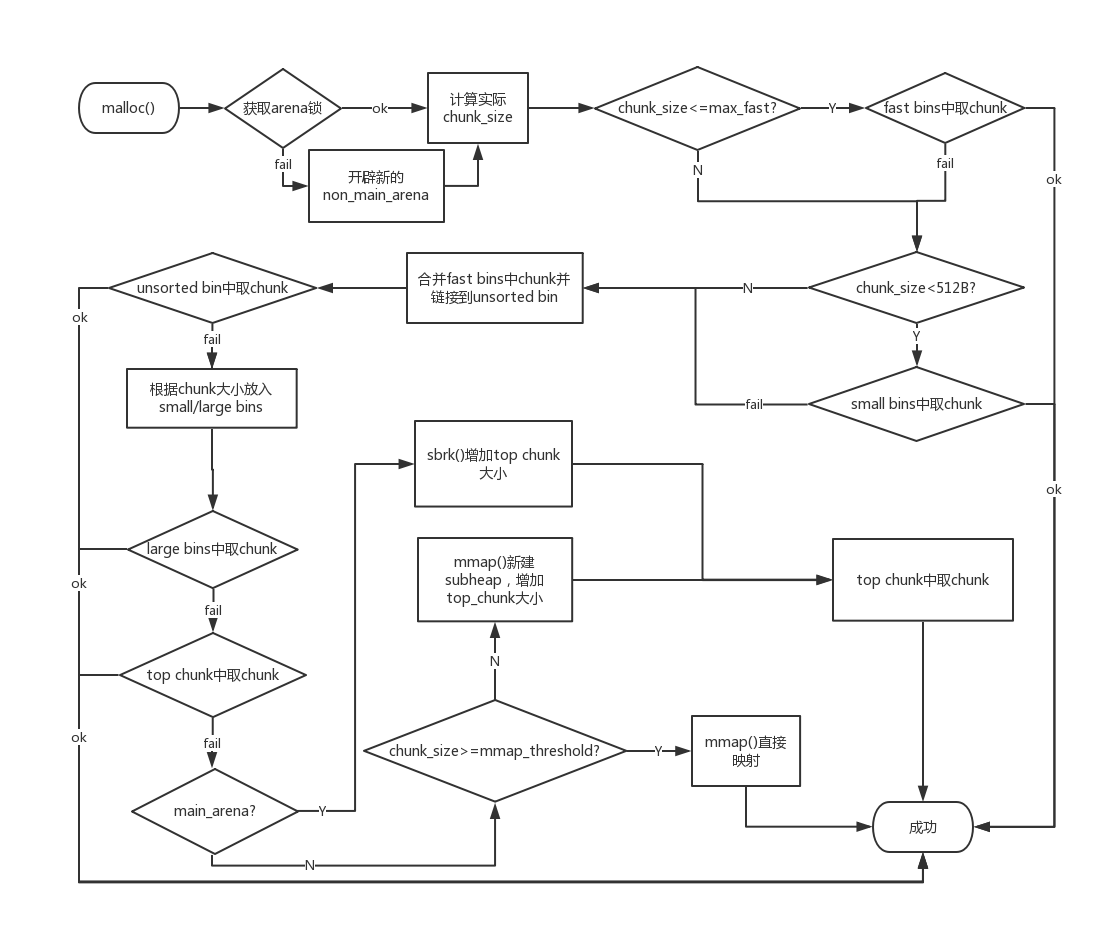
malloc和free的流程 malloc流程
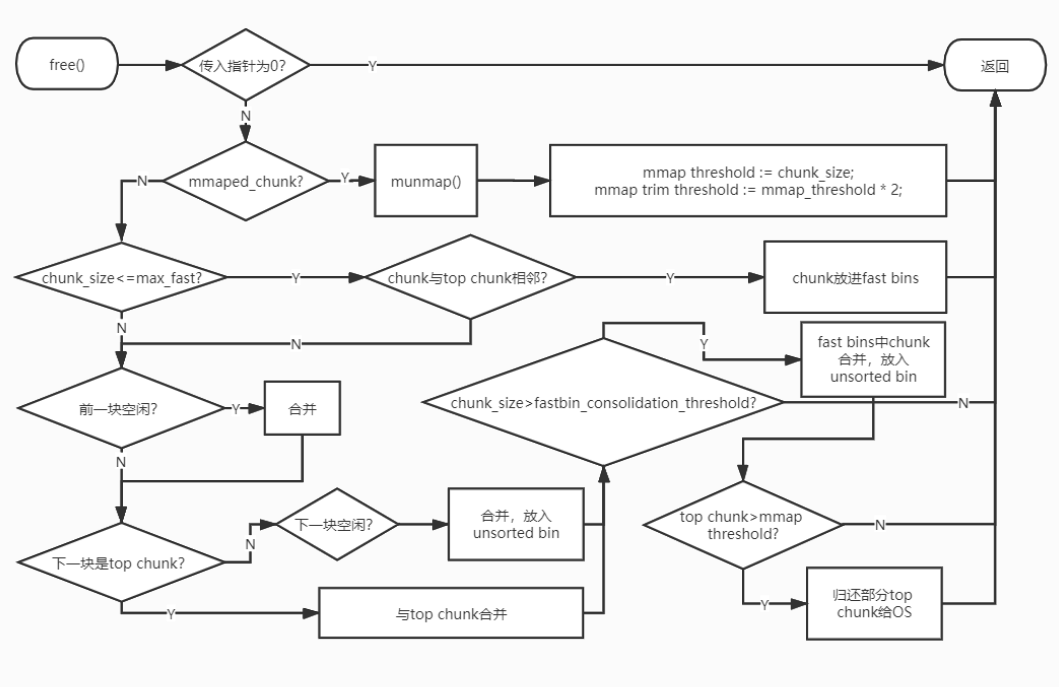
free流程
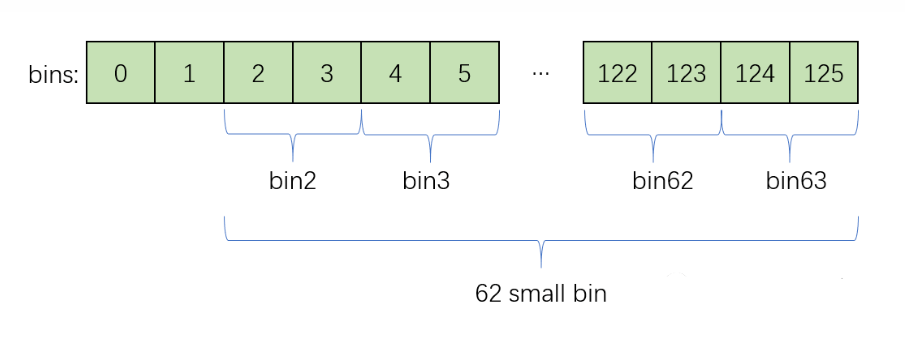
细节 bins数组相关 bins数组存在于malloc_state结构体中,它被定义为一个长度为254的数组,但我们都知道真正只有126个bin,及有效下标为[0,251] (多的那两个被浪费了)。
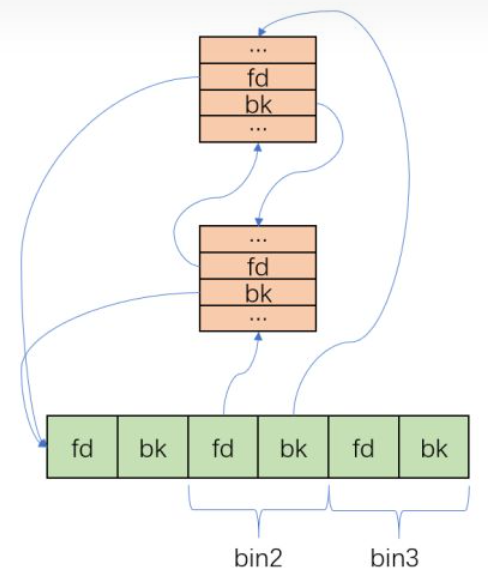
每个bins都是一个指针,在串联bin中起到了重要作用,同一个bin的fd指针和bk指针被存储在相邻位置(例如bins[0]为unsortedbin的fd指针bins[1]为unsortedbin的bk指针)。
但其实在讲解过程中我们更多提及的是bin的下标,实际上bin数组是一个更抽象的概念,它实际并不存在 ,但使用bin数组下标与对应各个bin的关系更为直接,因此被更多的使用。
bins下标[X]与bin下标[Y]的关系为:
这也就是为什么许多教程会说bin[0]和bin[127]不存在了,因为如果这样的话对应的bins下标就为-2和252,明显越界了。
以上所述其实我也不是很确定,各种教程里面的要么语焉不详没头没尾,要么上下矛盾,我也只能根据源码以及一些比较靠谱的博客做出一种比较合理的解释
我主要以这两个宏为根据,特别是第二个宏与我上面的公式对上了
1 2 3 4 5 6 #define smallbin_index(sz) \ ((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\ + SMALLBIN_CORRECTION) ##这个只是smallbin的索引计算方式,但其他bin大差不差 #define bin_at(m, i) \ (mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \ - offsetof (struct malloc_chunk, fd))
largebin的双向链表 largebin的双向链表与smallbin和unsortedbin不同在于,一个bin存在两个双向链表
其中一个与smallbin相同通过fd与bk将属于该bin的所有chunk串联
另一个则是通过fd_nextsize和bk_nextsize这个双向链表只串联每类大小中的一个 ,不包括节点bin .相同大小的chunk只有第一个会被串联,其余chunk的nextsize指针依然置为0.
阅读代码 1 2 3 4 5 victim一般代表被操作chunk fwd一般代表被操作chunk的下一个chunk bck一般代表被操作chunk的上一个chunk
chunk分配寻找
fastbin,tcachebin均为单链表,属于LIFO,头插头取,分配chunk主要利用fd指针
unsortedbin,smallbin,largebin均为双链表,属于FIFO,头插尾取,分配chunk主要利用bk指针,largebin有点特殊,不过大致与前两者相同
重要宏解释 看源码最让人头大的无非各种宏了(建议在vscode中阅读源码,能直接找到声明处。)这里记几个重要的宏,顺便做点解释。
chunk_at_offset 1 #define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
通过一个chunk指针和偏移得到另一个chunk
retquest2size 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #define REQUEST_OUT_OF_RANGE(req) \ ((unsigned long) (req) >= (unsigned long) (INTERNAL_SIZE_T)(-2 * MINSIZE)) #define request2size(req) \ (((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) \ ? MINSIZE \ : ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK) #define checked_request2size(req, sz) \ if (REQUEST_OUT_OF_RANGE(req)) { \ __set_errno(ENOMEM); \ return 0; \ } \ (sz) = request2size(req);
调整栈对齐,其中第三个宏整合了前两个,第二个是重点
一个细节
若申请大小零头<=size_sz,则不额外分配这部分内存,而是将下一个chunk的prev_size用以存储这部分数据
若申请大小零头>size_sz,则向下一个2*size_sz对齐,以求最小损耗
set_head 1 2 3 4 5 #define set_head_size(p, s) ((p)->mchunk_size = (((p)->mchunk_size & SIZE_BITS) | (s))) #define set_head(p, s) ((p)->mchunk_size = (s))
给切割或合并后新出现的chunk设置头
chunksize 1 2 3 4 5 #define chunksize(p) (chunksize_nomask (p) & ~(SIZE_BITS)) #define chunksize_nomask(p) ((p)->mchunk_size)
得到一个chunk的大小,可选是否忽略inuse位
inuse 1 2 3 4 5 6 7 8 9 10 #define inuse(p) \ ((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE) #define set_inuse(p) \ ((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE #define clear_inuse(p) \ ((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE)
分别是得到一个chunk的inuse位,设置inuse位为1,设置inuse位为0.
bin_at(m,i) 1 2 3 #define bin_at(m, i) \ (mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \ - offsetof (struct malloc_chunk, fd))
其中offsetof (struct malloc_chunk, fd))是常数值为16 ,所需bin的表头与前两个bins数组元素被视为了一个malloc_chunk(对unsorted bin来说前两个虽然不是bins数组成员,但也可以这样做),也就是说最终的结果就是指向这个chunk的指针,且这个chunk的fd和bk刚好是这个bin的头与尾指针。
first(b)与last(b) 1 2 #define first(b) ((b)->fd) #define last(b) ((b)->bk)
里面的b一般就是bin_at的返回结果,于是刚好指向所需bin的头和尾。
一些常数值 1 2 3 4 #define MINSIZE \ (unsigned long )(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)) #define MALLOC_ALIGNMENT (2 * SIZE_SZ < __alignof__ (long double) \ ? __alignof__ (long double ) : 2 * SIZE_SZ)
MINSIZE宏定义了最小的有效分配大小(32),它是为了确保分配的内存大小能够容纳一个堆块的头部信息和有效载荷而定义的。
MALLOC_ALIGNMENT定义了堆块的对齐方式,也就是堆块的起始地址必须是MALLOC_ALIGNMENT(16)的倍数。
unlink(AV, P, BK, FD) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #define unlink(AV, P, BK, FD) { \ if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0)) \ malloc_printerr ("corrupted size vs. prev_size" ); \ FD = P->fd; \ BK = P->bk; \ if (__builtin_expect (FD->bk != P || BK->fd != P, 0 )) \ malloc_printerr ("corrupted double-linked list" ); \ else { \ FD->bk = BK; \ BK->fd = FD; \ if (!in_smallbin_range (chunksize_nomask (P)) \ && __builtin_expect (P->fd_nextsize != NULL , 0 )) { \ if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0 ) \ || __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0 )) \ malloc_printerr ("corrupted double-linked list (not small)" ); \ if (FD->fd_nextsize == NULL ) { \ if (P->fd_nextsize == P) \ FD->fd_nextsize = FD->bk_nextsize = FD; \ else { \ FD->fd_nextsize = P->fd_nextsize; \ FD->bk_nextsize = P->bk_nextsize; \ P->fd_nextsize->bk_nextsize = FD; \ P->bk_nextsize->fd_nextsize = FD; \ } \ } else { \ P->fd_nextsize->bk_nextsize = P->bk_nextsize; \ P->bk_nextsize->fd_nextsize = P->fd_nextsize; \ } \ } \ } \ }
unlink的出现频率非常高,是一个很重要的宏
在malloc
从largebin中取chunk(fastbin,smallbin,unsortedbin都不这样做)
从比请求的chunk所在的bin大的bin中取chunk
在free 一般在free一个chunk-B时,若其前一个chunk-A或后一个chunk-C非top)处于空闲时,则会unlinkA或者C
一个细节 ,被free的chunk定然是没有fd,bk这些指针的,它通过自己的地址 与prev_size 或size 这两个字段的操作来得到上一个或下一个空闲chunk的地址
在malloc_consolidate 合并物理相邻的低地址或高地址空闲chunk
在realloc 合并物理相邻高地址空闲 chunk
index 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #define NBINS 128 #define NSMALLBINS 64 #define SMALLBIN_WIDTH MALLOC_ALIGNMENT #define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > 2 * SIZE_SZ) #define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH) #define in_smallbin_range(sz) \ ((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE) #define smallbin_index(sz) \ ((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\ + SMALLBIN_CORRECTION) #define largebin_index_32(sz) \ (((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) > > 6) :\ ((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) > > 9) :\ ((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) > > 12) :\ ((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) > > 15) :\ ((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) > > 18) :\ 126) #define largebin_index_32_big(sz) \ (((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) > > 6) :\ ((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) > > 9) :\ ((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) > > 12) :\ ((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) > > 15) :\ ((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) > > 18) :\ 126) #define largebin_index_64(sz) \ (((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) > > 6) :\ ((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) > > 9) :\ ((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) > > 12) :\ ((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) > > 15) :\ ((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) > > 18) :\ 126) #define largebin_index(sz) \ (SIZE_SZ == 8 ? largebin_index_64 (sz) \ : MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \ : largebin_index_32 (sz)) #define bin_index(sz) \ ((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz)) #define fastbin_index(sz) \ ((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
这一大串全是根据实际申请大小转换相应bin数组下标的宏
REMOVE_FB(fb, victim, pp) 1 2 3 4 5 6 7 8 9 #define REMOVE_FB(fb, victim, pp) \ do \ { \ victim = pp; \ if (victim == NULL) \ break; \ } \ while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) \ != victim); \
从fastbin中删除一个chunk
binmap相关 1 2 3 4 5 6 #define idx2block(i) ((i) >> BINMAPSHIFT) #define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT) - 1)))) #define mark_bin(m, i) ((m)->binmap[idx2block (i)] |= idx2bit (i)) #define unmark_bin(m, i) ((m)->binmap[idx2block (i)] &= ~(idx2bit (i))) #define get_binmap(m, i) ((m)->binmap[idx2block (i)] & idx2bit (i))
idx2block 宏接受一个整数 i,并将其右移 BINMAPSHIFT 位,相当于将 i 除以 1 << BINMAPSHIFT。这个值用于计算 binmap 数组中相应的块号。
idx2bit 宏接受一个整数 i,并将其按位左移 (i) & ((1U << BINMAPSHIFT) - 1) 位,这个值相当于将 i 对 1 << BINMAPSHIFT 取余。这个值用于计算 binmap 数组中相应块的二进制位。
mark_bin 宏接受一个指向 malloc_state 结构体的指针 m 和一个整数 i,它将 binmap 数组中相应的块标记为非空。
unmark_bin 宏与 mark_bin 宏类似,它将 binmap 数组中相应的块标记为空。
get_binmap 宏接受一个指向 malloc_state 结构体的指针 m 和一个整数 i,它返回 binmap 数组中相应块的二进制位,这个值表示该块是否为空闲块。
重要函数片段 0x1 1 2 3 4 5 6 7 if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0 )) { errstr = "malloc(): memory corruption (fast)" ; errout: malloc_printerr (check_action, errstr, chunk2mem (victim)); return NULL ; }
fastbin中取chunk时,判断chunk大小是否与当前fastbin大小匹配,实现是通过得到victim地大小,然后再由该大小得到真正地index,查看是否与idx相同
是Fastbin Double Free需要通过地一个验证
0x2 1 2 3 4 if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size)) <= 2 * SIZE_SZ, 0 ) || __builtin_expect (chunksize (chunk_at_offset (p, size)) >= av->system_mem, 0 ))
free过程中,用于检测要释放的chunk的nextchunk的大小是否合规,防止内存泄露或内存越界等问题.
system_mem一般为132k
0x3 1 2 3 4 5 mark_bin (av, victim_index); victim->bk = bck; victim->fd = fwd; fwd->bk = victim; bck->fd = victim;
在unsortedbin中取chunk时,最后将该chunk插入的操作
困惑 bins数组的双向链表是如何实现的[已解决]
从上图可以看到,每个small bin使用了bins array中的两个元素,以0、1、2、3四个元素为例,代码中把这部分空间强制转换成malloc_chunk类型
强制类型转换真的很重要
End 最后,堆的学习着实需要耐心,本人就是中途无数次摆烂,还总是被各种细节困惑,但只要坚持总是能入门的,另外有时遇到不懂又搜不到的知识点,不妨问问chatgpt或newbing之类的ai,虽然基本十个错九个(主要是gpt,bing不懂的它不会瞎答),但总是能给个方向。